标签:style blog http ar color os sp strong on
函数,变量

1 def add1(a,b): 2 c=a+b 3 print ‘add1:%s‘ %c 4 def add2(a): 5 print ‘add2:%s‘ %a 6 def add3(): 7 print ‘add3:no‘ 8 def add4(*arr): 9 a,b=arr 10 print ‘add4:%s,%s‘ %(a,b) 11 add1(1,2) 12 add2(4) 13 add3() 14 add4(100,‘qwer‘)

注意:
*arr 的 * 是什么意思?
它的功能是告诉 python 让它把函数的所有参数都接受进来, 然后放到名字叫 arr 的列表中去。
和你一直在用的 argv 差不多, 只不过前者是用在函数上面。
============================================================
按行读取文件:
1 script,file_name = argv 2 print ‘please input your file_name %s‘ %file_name 3 4 open_file = open(file_name) 5 6 def rewind(f): 7 f.seek(0) 8 rewind(open_file) 9 10 def print_line(line_number,f): 11 print line_number,f.readline() 12 13 current_line = 1 14 print_line(current_line,open_file) 15 current_line = current_line+1 16 print_line(current_line,open_file) 17 current_line = current_line+1 18 print_line(current_line,open_file)
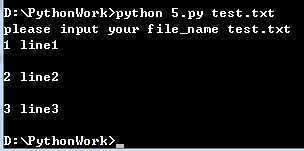
注意:
1.为什么文件里会有间隔空行?
readline() 函数返回的内容中包含文件本来就有的 \n,而 print 在打印时又会添加一个 \n,这样一来就会多出一个空行了。
解决方法是在 print 语句结尾加一个逗号 , ,这样 print 就
不会把它自 己的 \n 打印出来了。
2.为什么 seek(0) 没有把 current_line 设为 0?
首先 seek() 函数的处理对象是 字节 而非行,所以 seek(0) 只是转到文件的 0 byte,也就
是第一个 byte 的位置。其次, current_line 只是一个独立变量,和文件本身没有任何关系,
我们只能手动为其增值。
3.readline() 是怎么知道每一行在哪里的?
readline() 里边的代码会扫描文件的每一个字节,直到找到一个 \n 为止, 然后它停止读取
文件,并且返回此前的文件内容。文件 f 会记录每次调用 readline() 后的读取位置,这样它
就可以在下次被调用时读取接下来的一行了。
标签:style blog http ar color os sp strong on
原文地址:http://www.cnblogs.com/wufeng0927/p/4167366.html
