标签:style blog http ar io color os 使用 sp
文档的数据模型代表了数据的组织结构,一个好的数据模型能更好的支持应用程序。在MongoDB中,文档有两种数据模型,内嵌(embed)和引用(references)。
MongoDB的文档是无模式的,所以可以支持各种数据结构,内嵌模型也叫做非规格化模型(denormalized)。在MongoDB中,一组相关的数据可以是一个文档,也可以是组成文档的一部分。看看下面一张MongoDB文档中的图片。

内嵌类型支持一组相关的数据存储在一个文档中,这样的好处就是,应用程序可以通过比较少的的查询和更新操作来完成一些常规的数据的查询和更新工作。
根据MongoDB文档,当遇到以下情况的时候,我们应该考虑使用内嵌类型:
像这种一对一的关系,使用内嵌类型可以很方便的进行数据的查询和更新。
{ "_id": <ObjectId0>, "name": "Wilber", "contact": { "phone": "12345678", "email": "wilber@shanghai.com" } }
在这中情况中,如果应用程序会经常通过用户名字段来查询改用户发布的博客信息。那么,把posts作为内嵌字段会是一个比较好的选择,这样就可以减少很多查询的操作。
{ "_id": <ObjectId1>, "name": "Wilber", "contact": { "phone": "12345678", "email": "wilber@shanghai.com" }, "posts": [ { "title": "Indexes in MongoDB", "created": "12/01/2014", "link": "www.blog.com" }, { "title": "Replication in MongoDB", "created": "12/02/2014", "link": "www.blog.com" }, { "title": "Sharding in MongoDB", "created": "12/03/2014", "link": "www.blog.com" } ] }
根据上面的描述可以看出,内嵌模型可以给应用程序提供很好的数据查询性能,因为基于内嵌模型,可以通过一次数据库操作得到所有相关的数据。同时,内嵌模型可以使数据更新操作变成一个原子写操作。
然而,内嵌模型也可能引入一些问题,比如说文档会越来越大,这样就可能会影响数据库写操作的性能,还可能会产生数据碎片(data fragmentation)(即:使用内嵌模型要考虑Document Growth,下面引入MongoDB文档对Document Grouth的介绍)。另外,MongoDB中会有最大文档大小限制,所以在使用内嵌类型时还要考虑这点。
Some updates to documents can increase the size of documents. These updates include pushing elements to an array (i.e. $push) and adding new fields to a document. If the document size exceeds the allocated space for that document, MongoDB will relocate the document on disk. Relocating documents takes longer than in place updates and can lead to fragmented storage. Although MongoDB automatically adds padding to document allocations to minimize the likelihood of relocation, data models should avoid document growth when possible.
For instance, if your applications require updates that will cause document growth, you may want to refactor your data model to use references between data in distinct documents rather than a denormalized data model.
相对于嵌入模型,引用模型又称规格化模型(Normalized data models),通过引用的方式来表示数据之间的关系。
这里同样使用来自MongoDB文档中的图片,在这个模型中,把contact和access从user中移出,并通过user_id作为索引来表示他们之间的联系。
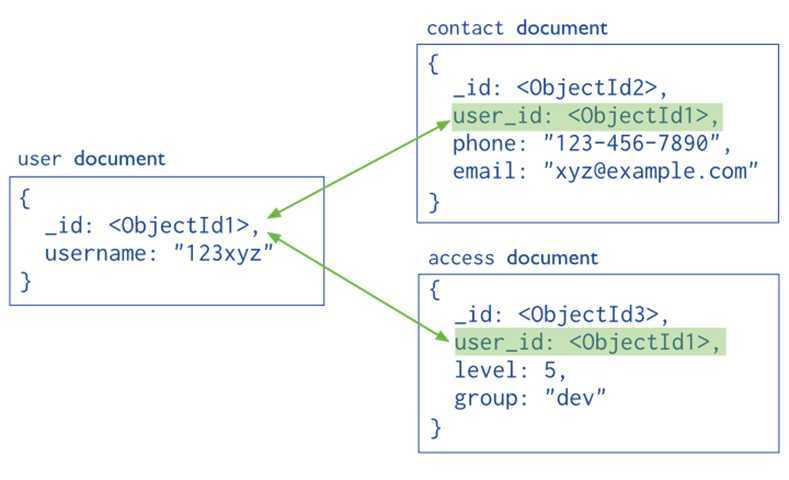
当我们遇到以下情况的时候,就可以考虑使用引用模型了:
下面看一个比较有意思的例子,该例子来自MongoDB文档
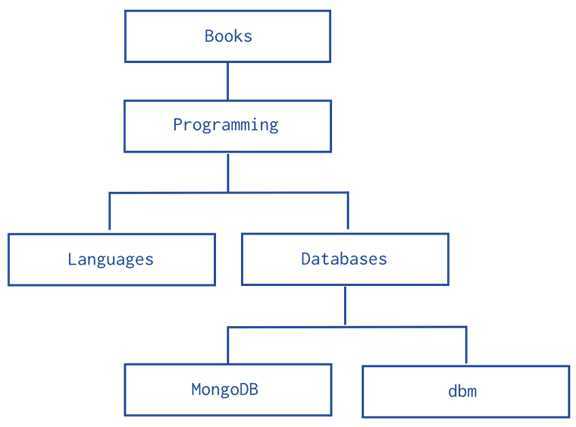
很直观的,我们都会使用父子关系来表示这中树形结构
db.categories.insert( { _id: "MongoDB", parent: "Databases" } )
db.categories.insert( { _id: "dbm", parent: "Databases" } )
db.categories.insert( { _id: "Databases", parent: "Programming" } )
db.categories.insert( { _id: "Languages", parent: "Programming" } )
db.categories.insert( { _id: "Programming", parent: "Books" } )
db.categories.insert( { _id: "Books", parent: null } )
db.categories.insert( { _id: "MongoDB", children: [] } )
db.categories.insert( { _id: "dbm", children: [] } )
db.categories.insert( { _id: "Databases", children: [ "MongoDB", "dbm" ] } )
db.categories.insert( { _id: "Languages", children: [] } )
db.categories.insert( { _id: "Programming", children: [ "Databases", "Languages" ] } )
db.categories.insert( { _id: "Books", children: [ "Programming" ] } )
在MongoDB中,引用又有两种实现方式,手动引用(Manual references)和DBRefs。
像前面的一对多例子,我们可以把use中的name字段保存在post文档中建立两者的关系,这样我们可以通过多次查询的方式的到我们想要的数据。这种引用方式比较简单,而且可以满足大多数的需求。
|
user document |
post document |
|
{ "name": "Wilber", "gender": "Male", "birthday": "1987-09", "contact": { "phone": "12345678", "email": "wilber@shanghai.com" } } |
{ "title": "Indexes in MongoDB", "created": "12/01/2014", "link": "www.blog.com", "author": "Wilber" } { "title": "Replication in MongoDB", "created": "12/02/2014", "link": "www.blog.com", "author": "Wilber" } { "title": "Sharding in MongoDB", "created": "12/03/2014", "link": "www.blog.com", "author": "Wilber" } |
注意,手动引用的唯一不足是这种引用没有指明使用哪个database,哪个collection。如果出现一个collection中的文档与多个其它collection中的文档有引用关系,我们可能就要考虑使用DBRefs了。
举例,假如用户可以在多个博客平台上发布博客,不同博客平台的数据保存在不同的collection。这种情况使用DBRefs就比较方便了。
|
user document |
Post4CNblog document |
Post4CSDN document |
Post4ITeye document |
|
{ "name": "Wilber", "gender": "Male", "birthday": "1987-09", "contact": { "phone": "12345678", "email": "wilber@shanghai.com" } } |
{ "title": "Indexes in MongoDB", "created": "12/01/2014", "link": "www.blog.com", "author": "Wilber" } { "title": "Replication in MongoDB", "created": "12/02/2014", "link": "www.blog.com", "author": "Wilber" } |
{ "title": "Sharding in MongoDB", "created": "12/03/2014", "link": "www.blog.com", "author": "Wilber" } |
{ "title": "Notepad++ configuration", "created": "12/05/2014", "link": "www.blog.com", "author": "Wilber" }
|
如果要查询在CNblog上发布"Replication in MongoDB"的用户详细信息,我们可以使用下面语句,通过两次查询得到用户详细信息
> db.Post4CNblog.find({"title": "Replication in MongoDB"}) { "_id" : ObjectId("548fe8100c3e84a00806a48f"), "title" : "Replication in MongoDB", "created" : "12/02/2014", "link" : "www.blog.com", "auth or" : "Wilber" } > db.user.find({"name":"Wilber"}).toArray() [ { "_id" : ObjectId("548fe8100c3e84a00806a48d"), "name" : "Wilber", "gender" : "Male", "birthday" : "1987-09", "contact" : { "phone" : "12345678", "email" : "wilber@shanghai.com" } } ]
DBRefs引用通过_id,collection名和database名(可选)来建立文档之间的关系。通过这种方式,即使文档分布在多个不同的collection中,也可以被方便的链接起来。
DBRefs有特定的格式,会包含下面字段:
举例,将上面的例子通过DBRefs来实现。注意,这是要把user文档中的用户名设置成_id字段。
|
user document |
Post4CNblog document |
Post4CSDN document |
Post4ITeye document |
|
{ "_id": "Wilber", "gender": "Male", "birthday": "1987-09", "contact": { "phone": "12345678", "email": "wilber@shanghai.com" } } |
{ "title": "Indexes in MongoDB", "created": "12/01/2014", "link": "www.blog.com", "author": {"$ref": "user", "$id": "Wilber"} } { "title": "Replication in MongoDB", "created": "12/02/2014", "link": "www.blog.com", "author": {"$ref": "user", "$id": "Wilber"} } |
{ "title": "Sharding in MongoDB", "created": "12/03/2014", "link": "www.blog.com", "author": {"$ref": "user", "$id": "Wilber"} } |
{ "title": "Notepad++ configuration", "created": "12/05/2014", "link": "www.blog.com", "author": {"$ref": "user", "$id": "Wilber"} }
|
同样查询在CNblog上发布"Replication in MongoDB"的用户详细信息,这样可以通过一次查询来完成
> db.Post4CNblog.findOne({"title":"Replication in MongoDB"}).author.fetch()
{
"_id" : "Wilber",
"gender" : "Male",
"birthday" : "1987-09",
"contact" : {
"phone" : "12345678",
"email" : "wilber@shanghai.com"
}
}
>
通过这篇文章大概认识了MongoDB中的数据模型,不能说内嵌模型和引用模型那个好,关键是看应用场景。
还有就是,在使用内嵌模型是一定要注意Document Growth和最大文档限制。
Ps:例子中所有的命令都可以参考以下链接
http://files.cnblogs.com/wilber2013/data_modeling.js
标签:style blog http ar io color os 使用 sp
原文地址:http://www.cnblogs.com/wilber2013/p/4167413.html