标签:style blog http ar color os sp on 2014
遗传算法(Genetic Algorithm,简称GA)是一类借鉴生物界的进化规律(适者生存,优胜劣汰遗传机制)演化而来的随机化搜索方法,由美国的J.Holland教授1975年首先提出。遗传算法是一种模拟达尔文的遗传选择和自然淘汰的生物进化过程的计算模型,通过模拟自然进化过程搜索最优解,它常用来解决多约束条件下的最优问题。
遗传算法是从代表问题可能潜在的解集的一个种群开始的,而一个种群则由经过基因编码的一定数目的个体组成。每个个体实际上是染色体带有特征的实体。染色体作为遗传物质的主要载体,即多个基因的集合,它决定了个体的形状的外部表现。因此,在一开始需要实现从表现型到基因型的映射即编码工作。由于仿照基因编码的工作很复杂,往往进行简化,如二进制编码,初始种群产生之后,按照适者生存和优胜劣汰的原理,逐代演化产生出越来越好的近似解,在每一代,根据问题域中个体的适应度大小挑选个体,并借助于自然遗传学的遗传算子进行组合交叉和变异,产生出代表新的解集的种群。这个过程将导致种群像自然进化一样的后生代种群比前代更加适应于环境,末代种群中的最优个体经过解码,可以作为问题近似最优解。
遗传算法提供了一种求解复杂系统优化问题的通用框架。它不依赖于问题的具体领域,对问题的种类有很强的鲁棒性,所以广泛应用于很多学科。遗传算法的主要应用领域有:函数优化、组合优化、生产调度问题、自动控制、机器人自动控制、图像处理和模式识别、人工生命、遗传程序设计、机器学习等。
(1)初始化。设置进化代数计数器,设置最大进化代数,随机生成N个个体作为初始种群。
(2)计算机适应度。 计算初始种群中每个体的适应度。
(3)选择。选择是用来确定重组或交叉的个体,以及被选个体将产生多少子个体。按照上面得出的适应度进行父代个体的选择。可以挑选以下算法:轮盘赌选择、随机遍历抽样、局部选择、截断选择、锦标赛选择。
(4)交叉。基因重组是结合来自父代交配种群中的信息产生新的个体。依据个体编码表示方法的不同,可以有以下的算法:实值重组;离散重组;中间重组;线性重组;扩展线性重组。二进制交叉、单点交叉、多点交叉、均匀交叉、洗牌交叉、缩小代理交叉。
(5)变异。交叉之后子代经历的变异,实际上是子代基因按小概率扰动产生的变化。依据个体编码表示方法的不同,可以有以下的算法:实值变异、二进制变异。
(1)遗传算法从问题解的串集开始嫂索,而不是从单个解开始。这是遗传算法与传统优化算法的极大区别。传统优化算法是从单个初始值迭代求最优解的;容易误入局部最优解。遗传算法从串集开始搜索,覆盖面大,利于全局择优。
(2)许多传统搜索算法都是单点搜索算法,容易陷入局部的最优解。遗传算法同时处理群体中的多个个体,即对搜索空间中的多个解进行评估,减少了陷入局部最优解的风险,同时算法本身易于实现并行化。
(3)遗传算法基本上不用搜索空间的知识或其它辅助信息,而仅用适应度函数值来评估个体,在此基础上进行遗传操作。适应度函数不仅不受连续可微的约束,而且其定义域可以任意设定。这一特点使得遗传算法的应用范围大大扩展。
(4)遗传算法不是采用确定性规则,而是采用概率的变迁规则来指导他的搜索方向。 (5)具有自组织、自适应和自学习性。遗传算法利用进化过程获得的信息自行组织搜索时,适应度大的个体具有较高的生存概率,并获得更适应环境的基因结构。
1、 在选择的过程中,选择多少次,会不会造成种群的减少,选到重复的怎么办?
答:选择次数没有限制,即然是选择肯定就会有没选上的,因此会造成种群数量减少,选到重复的个体舍弃重新选择。建议选择的次数少于种群数量,因为不重复,因此当次数为种群数量时即全部选择了,这样就失去了选择的意义。舍弃重复的是因为重复的个体对种群的差异化没有帮忙(试想极端情况下全是重复个体,那么交叉后全是一样的,没有意义)。
2、 即然计算出了种群中每个个体的适应度,为什么不直接选择适应度高的,舍弃适应度低的,而要用其他算法来选择?
答:适应度低的个体也可能存在优质基因。现实生活中的例子:一对傻子生了个聪明儿子。
3、交叉的过程是随机交叉还是两两交叉,交叉多少次合适?
答:随机或两两交叉都可以,交叉次数大于或等于初始种群中个体数量/2。因为交叉一次产生两个新个体,而第3步的变异不产生新个体,因此为保证种群中个体的数量不致于越来越少(人口负增长), 交叉次数大于或等于初始种群中个体数量/2。
自动组卷是根据出卷者给定的约束条件(目前考虑试题总数量、总分、知识点分布、难度系数、题型比例等因素),搜索试题库中与特征参数相匹配的试题,从而抽取最优的试题组合。由此可见,自动组卷问题是一个具有多重约束的组合优化问题。
传统的遗传算法存在搜索后期效率低和易形成末成熟收敛的情况。根据具体情况和需求分析要求,对遗传算法进了稍微改进,表现为采用实数编码、分段交叉、有条件生成初始种群,选择交叉后增加适应度检查。具体解决方案如下。
用遗传算法求解问题, 首先要将问题的解空间映射成一组代码串,即染色体的编码问题。在传统的遗传算法中采用二进制编码。用二进制编码时,题库里的每一道题都要出现在这个二进制位串中,1表示该题选中,0表示该题未被选中。这样的二进制位串较长,且在进行交叉和变异遗传算子操作时,各种题型的题目数量不好控制。采用实数编码方案,将一份试卷映射为一个染色体,组成该试卷的每道题的题号作为基因,基因的值直接用试题号表示,每种题型的题号放在一起,按题型分段,在随后的遗传算子操作时也按段进行,保证了每种题型的题目总数不变。比如,要组一份《C语言程序设计》试卷,其单选题6道,多选题4道,判断题5道,填空题5道,问答题3道,则染色体编码是:
(1、6、13、12、10、4 | 18、22、25、28 | 52、36、67、11、123 | 31、35、32、47、44 | 99、85、45)
单选题 多选题 判断题 填空题 问答题
试卷初始种群不是采用完全随机的方法产生,而是根据总题数、题型比例、总分等要求随机产生,使得初始种群一开始就满足了题数、总分等要求。这样加快遗传算法的收敛并减少迭代次数。采用分组实数编码,可以克服以往采用二进制编码搜索空间过大和编码长度过长的缺点,同时取消了个体的解码时间,提高了求解速度。
适应度函数是用来评判试卷群体中个体的优劣程度的指标,遗传算法利用适应度值这一信息来指导搜索方向,而不需要适应度函数连续或可导以及其它辅助信息。因为题数,总分等要求在初始化种群时已经考虑,这里只剩下知识点分布跟难度系数要考虑的了。所以适应度函数跟试卷难度系数和知识点分布有关。试卷难度系数公式:P=∑Di×Si/∑Si;其中i=1,2,....N,N是试卷所含的题目数,Di,Si分别是第i题的难度系数和分数。知识点分布用一个个体知识点的覆盖率来衡量,例如期望本试卷包含N个知识点,而一个个体中所有题目知识点的并集中包含M个(M<=N),则知识点的覆盖率为M/N。用户的期望难度系数EP与试卷难度系数P之差越小越好,知识点覆盖率越大越好,因此适应度函数如下:
f=1-(1-M/N)*f1-|EP-P|*f2
其中f1为知识点分布的权重,f2为难度系数所占权重。当f1=0时退化为只限制试题难度系数,当f2=0时退化为只限制知识点分布。
(1)选择算子。选择算子的作用在于根据个体的优劣程度决定它在下一代是被淘汰还是被复制。通过选择,将使适应度高的个体有较大的生存机会。本系统采用轮盘赌方法,它是目前遗传算法中最常用也是最经典的选择方法。其具体实现为:规模为M的群体P中各个个体的适应度为P={A1、A2、… Am} ,其被选择概率为: Ai/∑Ai(i从0到m)。
(2)交叉算子。由于在编码时采用的是分段实数编码,所以在进行交叉时采用分段单点交叉(按题型分段来进行交叉),整个染色体就表现为多点交叉。交叉的实现过程:将群体中的染色体任意进行两两配对,对每对染色体产生一个[0, N-2 ]的随机数r,r即为分段点,将r后的两道题目互换(保证分值相加一样)得到下一代。交叉后生成的子代有可能因存在重复的题号而非法。出现这种情况要将出现的题号换成该段中没有出现过的题号,这样重新得到新子代。
(3)变异算子。在遗传算法中,变异概率一般较小。这里不分段进行变异,而是只对某段上的某个基因进行变异。变异的操作如下:在[1,n]范围内随机生成一个变异位置P,以一定的原则从题库中选择一个变异基因,变异基因的选择原则为:与原基因题型相同的,分数相同,与至少包含原题目一个有效知识点(期望试卷中也有此知识点)。
算法实施流程如图所示:
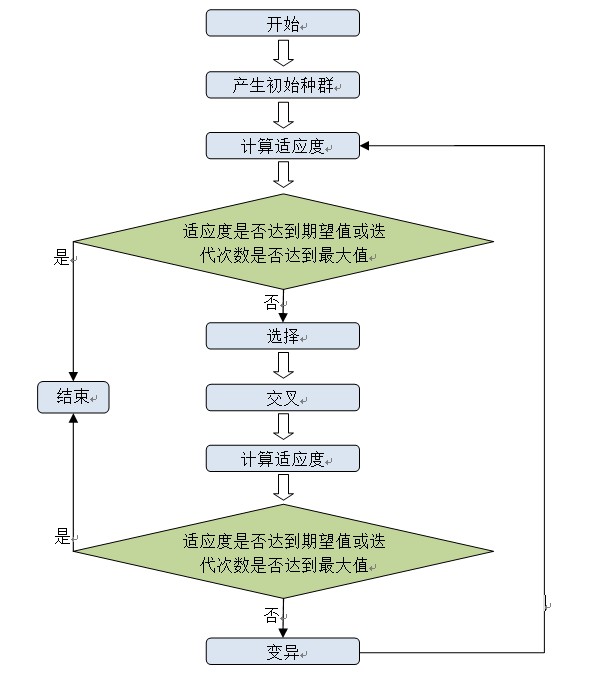
图1 算法实施流程图
程序设计请看下篇:实例讲解遗传算法——基于遗传算法的自动组卷系统【实践篇】
浪了N年:基于遗传算法自动组卷的实现
百度百科:遗传算法
标签:style blog http ar color os sp on 2014
原文地址:http://my.oschina.net/darkness/blog/357230