标签:style blog http ar io os 使用 sp for
Apple要求2015/2/1之后提交的包必须包含arm64,否则要被拒。因此,对于64-bit的支持可谓迫在眉睫,尤其是对于有很多遗留代码的项目,更要提早开工。
为了支持arm64结构,需要满足一下几个条件:
完成这些步骤之后,就可以build一个同时包含32-bit和64-bit的IPA文件。build完成之后你会发现有成千上百的警告和错误,这时候才是真正工作的开始。
另外,经过以上步骤之后,会发现当前的项目无法通过Xcode在iOS6以下的系统上联调,或者iTunes等直接安装打包的IPA文件。不过将打包的IPA文件通过AppStore发布是可以安装在iOS5.1.1上的,有人推断AppStore会对提交的IPA文件做一些magic的事情。如果想在iOS6以下的系统上联调,则需要在Valid Architectures里去掉arm64。
根据Apple官方介绍,arm64会带来以下的改变:
下面分别介绍这三方面的具体变化。
arm64带来的最大改变就是寻址空间和寄存器从32-bit增长为64-bit,系统可以提供更多的内存和更大的寄存器空间。下面两张图列出了转移到64-bit后Data Type的变化。
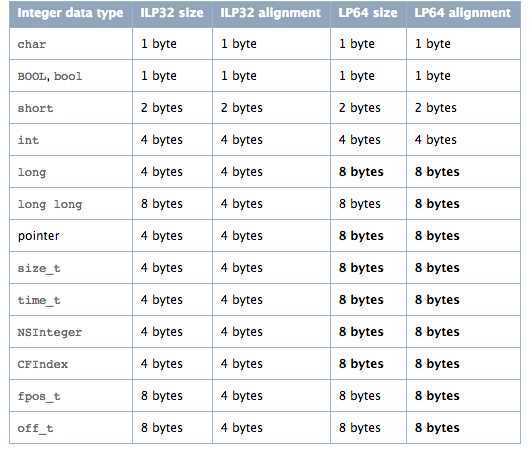
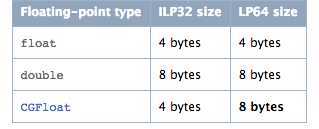
ILP32表示32-bit系统,LP64表示64-bit系统。图中的黑体表示64-bit相对于32-bit的不同,其改变可以概括为以下几点:
从以上总结可知,如果同时为32-bit和64-bit的系统开发软件,不可避免地会在32-bit和64-bit的数据之间产生运算和赋值等操作。面临的风险主要有以下:
32-bit和64-bit数据之间的操作。
这里的操作包括数学运算和赋值等运算,运算过程中可能会遇到数据截断,数据的溢出以及一些独特的边界情况。主要有以下几种情况:
32-bit和64-bit数据之间的赋值。将一个64-bit的数据赋给一个32-bit的变量,比如:
int intValue = NSItegerMax;
这将会导致数据截断,并不会得到期望的结果。同理如果将一个32-bit的数据赋给一个64-bit的变量,将会获得意想不到的结果,比如:
NSUInteger biggerIntValue = -1;
指向32-bit数据的指针变量和指向64-bit数据的指针变量互相赋值。如下操作:
int *pointerToInt = pointerToLong;
pointerToLong = pointerToInt;
由于pointerToInt + 1实际上是+4,而pointerToLong + 1实际上是+8,所以转换之后再进行指针运算所得结果是错的。
指针和变量之间的赋值。如下:
int currentAddress = pointerToLong;
NSInteger *pointerToNSInteger = currentAddress + 1;
这里的指针地址不但被截断了,并且+1操作也不会得到期望的结果。
针对以上列出的潜在风险,这里有两点建议:
在32-bit和64-bit的软件之间交换数据。
32-bit和64-bit的软件很可能通过网络读写同一份文件,甚至用户也会用32-bit软件的数据覆盖64-bit软件下的同一份数据,这些都会导致无法预测地错误。比如NSInteger在32-bit是4Byte,而在64-bit上则是8Byte。如果这时在32-bit软件里访问由64-bit软件生成的内容为NSInteger类型的文件,结果无法预测。
struct second {
int milliSecond;
long microSecond;
};
使用一致的数据类型。
也即尽量使用与系统无关的数据类型,如果该软件同时存在32-bit和64-bit的版本,建议在32-bit和64-bit中使用相同的数据类型。比如,不管在32-bit软件还是64-bit软件上,尽量都使用int32_t或者int64_t。
创建内存模型一致的数据模型。
即数据模型大小和其中的元素偏移量都相同。针对上面提到的第二个问题,有以下两种解决方案:
struct second {
int32_t milliSecond;
int32_t microSecond;
};
#pagram pack(4)
struct second {
int32_t milliSecond;
int64_t microSecond;
};
#pragma options align=reset
使用plist,XML和JSON进行序列化和持久化。
当使用NSCoder在64-bit软件上encode一个NSInteger数据,而后在32-bit软件上decode该NSInteger数据,同时该整型数值正好超出了32-bit int类型可以表示的范围时,将会抛出一个异常。
消耗更多的内存。
由以上的分析可知,很多的基本类型和指针地址都从4Byte增长为8Byte,这也预示着64-bit软件将消耗更多的内存。不但一些基本类型消耗了更多的内存,甚至常用的Foundation Object都要消耗更多的内存,由于其强大的功能,比如NSArray,NSDictionary。针对这个问题有以下几点建议:
选用合适的Foundation Object。
如果在NSArray里只存储一个简单的对象,然后产生成千上百这也的对象,那么消耗的内存将是巨大的。因此,尽量在合适的场合使用合适的类。
选择紧凑的数据模型。
尽量选择更合适的数据模型来表示你的数据。假定你要表示一个date类型,使用的数据模型如下:
struct date {
NSInteger second;
NSInteger minute;
NSInteger hour;
NSInteger day;
NSInteger month;
NSInteger year;
};
在32-bit的软件上date的大小是24Byte,在64-bit的软件上date是48Byte,惊人吧!简单地改变一下设计,在达到目标的同时还可以节省很多的内存使用,结构如下:
struct date {
long seconds;
};
seconds表示流逝的总秒数,通过简单的计算即可得到year,month,day......
消除多余的padding。
为了性能的原因,编译器通常会在基本数据类型之间添加padding,以使他们对齐,避免多次访问内存。比如:
struct morePadding { //32-bit
char second; //offset 0
int minute; //offset 4
char hour; //offset 8
NSInteger day; //offset 12
}; //total size 16
morePadding的实际大小为10Byte,而占据的内存大小为16Byte。经过重新设计将其改为以下结构:
struct morePadding { //32-bit
int minute; //offset 0
NSInteger day; //offset 4
char second; //offset 8
char hour; //offset 9
}; //total size 10
使用尽量少的指针变量。
避免在数据模型中过度使用指针,考虑以下模型:
struct node{
node *previous;
node *next;
uint32_t value;
};
在64-bit软件中node总大小为20Byte,而有效数据只有4Byte,80%的空间都被指针占据,可以考虑使用其他的数据结构代替。
在可以表达的范围内使用更小的数据类型。
如果只是表达几千几百的数字,则int就可以满足需求了,不需要使用NSInteger。宗旨就是使用够用的数据类型表示数字,没有必要64-bit软件就一定要使用int64_t类型。
只cache必须的数据。
为了性能优化的目的,我们的代码经常使用cache机制,即拿空间换时间,cache确实可以在很多地方提高软件的响应速度,甚至节省网络流量等。比如缓存网络图片避免下次联网,缓存经过滤镜处理以后的图片,避免CPU多次执行同意操作。64-bit软件消耗了更多的内存,如果缓存了过多的无关紧要的东西,可能反而会降低软件的整体性能。因此,建议以下的情况不要使用缓存:
所以,应该经常地测试cache确实提升了性能。
合理使用@autoreleasepool。
尽快释放不再需要的autorelease对象,避免内存耗尽迫使系统发出UIApplicationDidReceiveMemoryWarningNotification通知。尤其是for循环和递归调用的场合,需要给出特别的关注。
处理UIApplicationDidReceiveMemoryWarningNotification。
所有相关的对象都必须处理UIApplicationDidReceiveMemoryWarningNotification通知,尤其是各个Controller,cache Manager需要第一时间响应该通知,避免导致低内存的crash。
如果没有使用汇编语言的话,转换到64-bit的影响并不是很大,只有一点,可变参数的函数的调用规则在64-bit软件上是不一样的。因此,对于函数调用建议如下:
避免在函数签名不一样的函数之间强制转换。
在不同的函数签名的指针变量之间互相传递,很容易导致调用函数的时候传递不合适的参数,从而无法得到预期的结果,尤其在固定参数的函数和可变参数的函数之间强制转换,如下所示:
int MyFunction(int a, int b, ...);
int (*action)(int, int, int) = (int (*)(int, int, int)) MyFunction;
action(1,2,3); // Error!
给可变参数的函数传递正确的参数。
由于可变参数列表通常未提供类型信息,如果这时传递了错误的参数值,将不会得到正确的结果。所以,可以考虑给可变参数添加格式字符串,提供一定的类型信息,比如printf()。
不要直接访问OC对象的isa,在64-bit软件里边isa不再是一个指向class object的指针,它包含一些指针数据和一些运行时信息。如果需要得到class object,使用object_getClass函数。
arm64的指令极大地不同于32-bit的指令,因此,汇编代码需要重写。arm64的函数调用约定跟标准的arm不太一样,可以参考iOS ABI Function Call Guide。
标签:style blog http ar io os 使用 sp for
原文地址:http://www.cnblogs.com/CoderPlace/p/4170418.html