标签:style blog http ar color 使用 sp for java
?
在各种SQL 的教程上一直都强调SQL SERVER 的4个隔离级别(其实这是SQL 工业标)
未提交读 | ReadUncommited? |
已提交读 | ReadCommited? |
不可重复读 | RepeatableRead? |
序列化 | Serializable (为什么叫这个么名字?) |
这4种隔离级别,本身没有优劣之分,完全取决于应用的场景。
本质上,他们是在 隔离性(紊乱程度) 和 灵活性(并发性) 之间博弈。简单的说,灵活性越高,隔离性越差。反之亦然。
我的理解是:如果不太计较数据出现的少许紊乱,可以使用用最低级别的隔离性(保持高并发性) ,比如 刷微信 这类事情,你不能让用户人等着 朋友圈数据同步完了再出来结果。
同样的,发奖金这样的事情是极其敏感的。你不能因为来了几个新人,就要求把老员工的奖金拿去平均了(总奖金/员工数量=单人奖金?,计算奖金的时候应该隔离新员工的INSERT,请刚入职的人不要恨我),这时候要强调隔离性(绝不能乱!),并发慢一点我们无所谓(反正有时间等,大家也理解,当然也不能太慢了)。
世界就是如此,不存在又灵活又能保持一致的数据库解决方案 (可能我眼界窄,也许已经有了),即不存在: 超人+蝙蝠侠 这样的完美个体存在。于是,我们需要在超人(灵活性)和蝙蝠侠(隔离性)之间做出选择。
我按照自己的理解来说明,这些隔离级别存在的问题。
先建立原料,创建一个Testtb
CREATE TABLE TESTTB ( ID INT, NAME VARCHAR(32) ) |
?
所谓未提交读,可以这么简单理解:查询语句不发出锁。这是个与世无争的存在,速度也是最快的。
BEGIN TRAN SELECT * FROM TESTTB WITH(NOLOCK) COMMIT |
?
但是,他存在一个问题(快是有代价的),我们用2个并发查询(SQL SERVER 新建2个查询,事务1先执行)
--脏读事务1 BEGIN TRAN INSERT INTO TESTTB VALUES(1,‘EFG‘) --这个时候运行事务2 WAITFOR DELAY ‘00:00:10‘ INSERT INTO TESTTB VALUES(1,‘EFG‘) ROLLBACK | --事务2 BEGIN TRAN SELECT * FROM TESTTB WITH(NOLOCK) COMMIT |
?
请注意这个ROLLBACK ,事务1 是回滚的。你猜事务2读到了什么,事务最后回滚的,他居然读出了一个数据,这种情况就叫脏读
(可以这么理解,你想在微信上吐槽,已经点了发送,但突然想到可能得罪某人,连忙点了取消;刚好此时某个家伙刷一下微信,居然读出那条吐槽。就这么个感觉)

前面说了,对于微信这样的要求高并发的系统,未提交读是无所谓的。但是作为企业应用你可能想解决这个问题。
?
?
?
?
我们做下面这个测试
BEGIN TRAN INSERT INTO TESTTB VALUES(1,‘EFG‘) --这个时候运行事务2 WAITFOR DELAY ‘00:00:10‘ INSERT INTO TESTTB VALUES(1,‘EFG‘) ROLLBACK | --事务2 BEGIN TRAN SELECT * FROM TESTTB COMMIT |
?
我们的事务2的结果是怎么样的呢?
我们发现有趣的事情
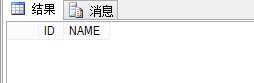
问题的关键就在这个阻塞上面(没错,如果你工作中碰到用户说现场阻塞了,就是这么回事)。SQL SERVER数据库使用了 已提交读 作为隔离级别的时候。会发出一个共享锁
(S锁,oracle ,mysql,sybase 我不知道,但估计是一个意思:一份文件正在被写的时候,其他人不能读。)
也就是说,这个SELECT 正在等待 INSERT 事务提交。 INSERT 完了,它才执行
(如果你有 windows 核心编程背景,就理解为INSERT 产生了一个信号量,SELECT 之前 要用WaitForSIngleObject 判断有无信号)
使用已提交读,就解决了这个脏读的问题。SQL SERVER 默认用这个隔离级别。所以,你没有看到WITH (xxx) 这样的锁\隔离级别声明。
?
?
已提交读能在大多数情况下工作良好,但是,他也有郁闷的缺陷。
我们先往Testtb中插入一条数据
INSERT INTO TESTTB VALUES(1,‘EFG‘) |
?
让我们来看下面的并发事务
BEGIN TRAN SELECT NAME FROM TESTTB WHERE ID = 1 WAITFOR DELAY ‘00:00:10‘ --阻塞之后执行事务2 SELECT NAME FROM TESTTB WHERE ID = 1 COMMIT | --事务2 BEGIN TRAN UPDATE TESTTB SET NAME = ‘变!‘ WHERE ID = 1 COMMIT |
?
事务1执行结果是怎样的?
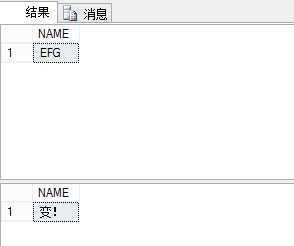
什么情况?事务1,读到2次不同的值。这就出现了前后不一致的情况。这就是不可重复读。
这种感觉就是:你通过淘宝买了iphone6 ,商家给你发了个iphone6 (事务开始了),中间某个环节出了差错。你收到货了(事务结束),打开一看,是iphon4。就这种感觉
?
在企业应用中,前后状态不一致,可能是不允许的。
那么我们看看如何解决
BEGIN TRAN SELECT NAME FROM TESTTB WITH(REPEATABLEREAD) WHERE ID =1 --阻塞之后执行事务2 WAITFOR DELAY ‘00:00:10‘ SELECT NAME FROM TESTTB WITH(REPEATABLEREAD) WHERE ID =1 COMMIT | --事务2 BEGIN TRAN UPDATE TESTTB SET NAME = ‘给老子变!‘ WHERE ID = 1 COMMIT |
?
看看事务1的输出结果
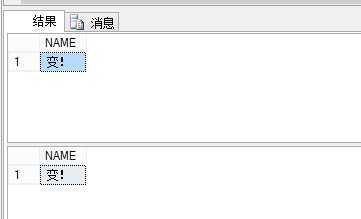
而且执行事务2的时候,他一直在阻塞,直到事务1提交,才运行。
这个阻塞,一样的,就好读比一个文档,我加了一条规矩(隔离级别):哥们在读的时候,旁的人都给我等着!于是事务2就老老实实的等着。
对于前面 已提交读就没这个功能,他的规矩是:别人在写的时候,我等着。
而未提交读的规矩是啥呢?: 写啥呢?我瞅瞅! 没写完不要紧的,我就拍个照,绝不浪费您的时间!
?
就这样,通过WITH(REPEATABLEREAD) 隔离级别提示,我们解决了不可重复读的问题。
?
很完美了 对吗? 有了可重复读 隔离级别,我们能保持前后数据一致。
现在我们来修改需求,我们要求计算表中记录数量。我们看下面的代码
BEGIN TRAN SELECT COUNT(1) FROM TESTTB WITH(REPEATABLEREAD) WAITFOR DELAY ‘00:00:10‘ --阻塞之后执行事务 SELECT COUNT(1) FROM TESTTB WITH(REPEATABLEREAD) COMMIT | --事务2 BEGIN TRAN INSERT INTO TESTTB VALUES (2,‘A‘) INSERT INTO TESTTB VALUES (3,‘B‘) INSERT INTO TESTTB VALUES (4,‘C‘) COMMIT |
至今为止,我们数据库里面只有一条记录对吗?
我们看看事务1输出结果
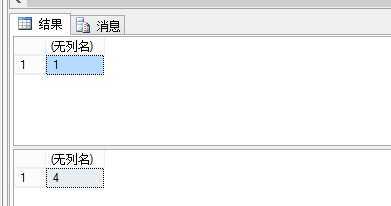
?
即使我们增加了REPEATABLEREAD 关键字,但是得到结果前后数量不一致。这就是幻读
运用你的直觉(我认为这是一种天赋)!你感觉到了 REPEATABLEREAD
好像没有阻塞INSERT ,但在上一个例子中,他成功的阻塞了UPDATE.
why?
我是这么理解的,UPDATE 和 DELETE 有一个共同点是,对一个已经存在的记录进行操作。也就是说能被SELECT 到。因此可以加锁。但是INSERT在执行的时候数据是不存在的。你无法给记录加锁!所以,你无法阻塞任何INSERT语句。虽然INSERT 语句也发出一个排它锁,但是数据产生之前,你只能尝试阻塞这空气一般的存在。因为,你不知道它在哪儿。
?
解决幻读
?
SQL 在4个隔离级别中,最高级隔离别就是Serializable (可序列化),老实说我真不理解这个名字。他和JAVA /C# 中的 序列化好像完全没关系。根本就无法通过名字理解这个隔离级别的意思。因此,我私下给他重新取了个名"不可新增读"。 顾名思义:在SELECT执行的时候,不可INSERT.
来,我们修改我们的隔离级别。
--事务1 BEGIN TRAN SELECT COUNT(1) FROM TESTTB WITH(SERIALIZABLE) WAITFOR DELAY ‘00:00:10‘ --阻塞之后执行事务 SELECT COUNT(1) FROM TESTTB WITH(SERIALIZABLE) COMMIT | --事务2 BEGIN TRAN INSERT INTO TESTTB VALUES (5,‘AA‘) INSERT INTO TESTTB VALUES (6,‘BB‘) INSERT INTO TESTTB VALUES (7,‘CC‘) COMMIT |
?
再次运行你的直觉! 上一次INSERT 之后,我们有4条数据了! 这次依次执行执行事务1,2之后,我们得到结果是多少呢?
我认为是2条都是4.
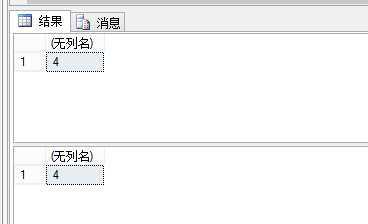
果然,WITH(SERIALIZABLE) 隔离级别解决了幻读的问题。保证了前后读取一致。这个隔离级别是最严格的。他连INSERT 都给阻塞了(它是怎么做到的,原理是什么?参考 《SQL SERVER 2008 查询性能优化》P340 页 老实说它也解释的不够详细,(没有证实,纯属猜测)我是这么认为的, SQL SERVER 不是有一个自动增长设置吗? 像不像C++中的vector 的 capacity 属性? 预分配一些空间,这样不用等到insert 的时候才去分配空间,那么我分配给这个表的预留空间 是不是也有ID? 即有许多没有用的空间的集合? 当我指定了SERIALIZABLE 隔离级别时,我用一个 信号量把 这块集合个阻塞起来!)
上面的例子分析了 脏读,不可重复度,幻读 。
分别解释了 他们是什么,以及简单的原因。并用代码做出了演示。
事实上,这些隔离级别是层层递进的。下面这幅图来源于《企业应用架构模式》P 52

标签:style blog http ar color 使用 sp for java
原文地址:http://www.cnblogs.com/songr/p/4172213.html