标签:
前言
本文将继续讲解K-近邻算法的项目实例 - 手写识别系统。
该系统在获取用户的手写输入后,判断用户写的是什么。
为了突出核心,简化细节,本示例系统中的输入为32x32矩阵,分类结果也均为数字。但对于汉字或者别的分类情形原理都是一样的。
有了前面学习的基础,下面直接进入项目开发步骤。
第一步:收集并准备数据
在用户主目录的trainingDigits子目录中,存放的是2000个样本数据。
每个样本一个文件,其中一部分如下所示:

文件命名格式为:
分类标签_标签内序号
如 0_20.txt 就表示该样本是分类标签为0的第20个特征集。20就是个序号以区分标签内不同文件而已,没其他意义。
样本数据都是32x32矩阵:

对于这样的二维数据,如何判断样本和目标对象的距离呢?首先想到的是可以将二维降到一维。
当然也可以考虑去找找二维的距离求解方法。
下面给出降维函数:
1 def img2vector(filename): 2 ‘将32x32的矩阵转换为1024一维向量‘ 3 4 # 初始化返回向量 5 returnVect = numpy.zeros((1,1024)) 6 7 # 打开样本数据文件 8 fr = open(filename) 9 10 # 降维处理 11 for i in range(32): 12 lineStr = fr.readline() 13 for j in range(32): 14 returnVect[0,32*i+j] = int(lineStr[j]) 15 16 return returnVect
第二步:测试算法
K临近的分类函数代码在之前的文章K-近邻分类算法原理分析与代码实现中给出了,这里直接调用:
1 def handwritingClassTest(): 2 ‘手写数字识别系统测试代码‘ 3 4 hwLabels = [] 5 6 # 获取所有训练集文件名 7 trainingFileList = os.listdir(‘/home/fangmeng/trainingDigits‘) 8 9 # 定义训练集结构体 10 m = len(trainingFileList) 11 trainingMat = numpy.zeros((m, 1024)) 12 13 for i in range(m): 14 # 当前训练集文件名 15 filenameStr = trainingFileList[i] 16 # 文件名(filenameStr去掉.txt后缀) 17 fileStr = filenameStr.split(‘.‘)[0] 18 # 分类标记 19 classNumStr = int(fileStr.split(‘_‘)[0]) 20 # 将分类标记加入分类列表 21 hwLabels.append(classNumStr) 22 # 将当前训练集文件降维后加入到训练集结构体 23 trainingMat[i] = img2vector(‘/home/fangmeng/trainingDigits/%s‘ % filenameStr) 24 25 # 获取所有测试集文件名 26 testFileList = os.listdir(‘/home/fangmeng/testDigits‘) 27 # 错误分类记数 28 errorCount = 0 29 # 测试集文件个数 30 mTest = len(testFileList) 31 32 print "错误的分类结果如下:" 33 for i in range(mTest): 34 # 当前测试集文件名 35 fileNameStr = testFileList[i] 36 # 文件名(filenameStr去掉.txt后缀) 37 fileStr = fileNameStr.split(‘.‘)[0] 38 # 分类标记 39 classNumStr = int(fileStr.split(‘_‘)[0]) 40 # 将当前测试集文件降维 41 vectorUnderTest = img2vector(‘/home/fangmeng/testDigits/%s‘ % fileNameStr) 42 # 对当前测试文件进行分类 43 classifierResult = classify0(vectorUnderTest, trainingMat, hwLabels, 3) 44 45 if (classifierResult != classNumStr): 46 print "分类结果: %d, 实际结果: %d" % (classifierResult, classNumStr) 47 errorCount += 1.0 48 49 print "\n总错误数: %d" % errorCount 50 print "\n总错误数: %f" % (errorCount/float(mTest))
运行结果:
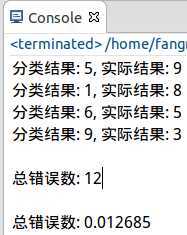
小结
1. K-邻近算法的本质是用来分类的,要从分类的思想去思考这个算法的运用。
2. 再强调一次K-邻近算法是没有训练过程的,这点和以后学习的其他分类方法,比如决策树对比后就更清楚了。
3. K-邻近算法的效率很低,不论是从时间还是空间上看(单就这个简单项目都跑得很慢)。因此需要学习更多更优化的算法。
4. 有兴趣有时间可以考虑在hadoop集群下实现这个项目或使用该算法的其他类似项目,定能大幅度提升性能。
标签:
原文地址:http://www.cnblogs.com/scut-fm/p/4180359.html