标签:
java集合
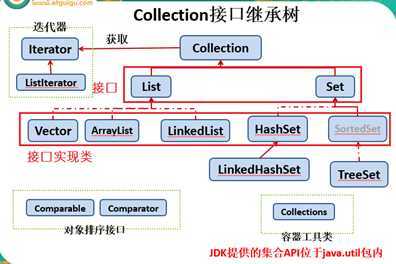
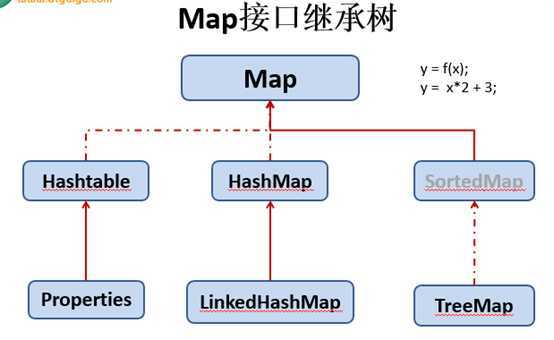


红色部分:集合与数组间转换操作的方法:如下图
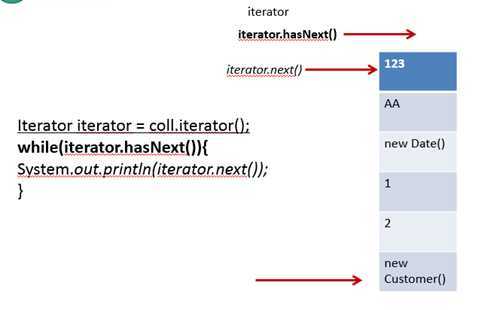
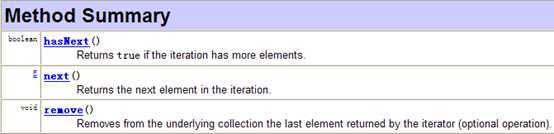

在调用it.next()方法之前必须要调用it.hasNext()进行检测。若不调用,且下一条记录无效,直接调用it.next()会抛出NoSuchElementException异常
?
while(it.hasNext()){
????…..it.next();
}
使用 foreach 循环遍历集合元素

1、ListIterator和Iterator都有hasNext()和next()方法,可以实现顺序向后遍历。但是ListIterator有hasPrevious()和previous()方法,可以实现逆向(顺序向前)遍历。Iterator就不可以。
2、ListIterator可以定位当前的索引位置,nextIndex()和previousIndex()可以实现。Iterator 没有此功能。
3、ListIterator有add()方法,可以向List中插入对象,而Iterator不能。
4、都可实现删除对象,但是ListIterator可以实现对象的修改,set()方法可以实现。Iterator仅能遍历,不能修改。因为ListIterator的这些功能,可以实现对LinkedList等List数据结构的操作。
?
hashCode() 方法
对象中用作 equals() 方法比较的 Field,都应该用来计算 hashCode 值

?
排 序——自然排序 Comparable 接口
?
排 序——定制排序 comparator接口

若使用自定义类作为TreeMap的key,所属类需要重写equals()和hashCode()方法,且equals()方法返回true时,compareTo()方法应返回0
Properties pros = new Properties(); pros.load(new FileInputStream("jdbc.properties")); String user = pros.getProperty("user"); System.out.println(user); |
查找、替换
?
同步控制

Enumeration stringEnum = new StringTokenizer("a-b*c-d-e-g", "-"); ????while(stringEnum.hasMoreElements()){ ????????Object obj = stringEnum.nextElement(); ????????System.out.println(obj); ????} |
?
1 Collection 和 Collections的区别
答:Collection是集合类的上级接口,继承与他的接口主要有Set 和List.
Collections是针对集合类的一个帮助类,他提供一系列静态方法实现对各种集合的搜索、排序、线程安全化等操作
?
--------------------------------------------------
2 Set里的元素是不能重复的,那么用什么方法来区分重复与否呢? 是用==还是equals()? 它们有何区别
答:Set里的元素是不能重复的,那么用iterator()方法来区分重复与否。equals()是判读两个Set是否相等
equals()和==方法决定引用值是否指向同一对象equals()在类中被覆盖,为的是当两个分离的对象的内容
和类型相配的话,返回真值
?
--------------------------------------------------
3 List, Set, Map是否继承自Collection接口
答: List,Set是,Map不是
?
--------------------------------------------------
4 两个对象值相同(x.equals(y) == true),但却可有不同的hash code,这句话对不对
答:不对,有相同的hash code
?
--------------------------------------------------
5 说出ArrayList,Vector, LinkedList的存储性能和特性
答:ArrayList和Vector都是使用数组方式存储数据,此数组元素数大于实际存储的数据以便增加和插入元素,它们都允许直接按序号索引元素,但是插入元素要涉及数组元素移动等内存操作,所以索引数据快而插入数据慢,Vector由于使用了synchronized方法(线程安全),通常性能上较ArrayList差,而LinkedList使用双向链表实现存储,按序号索引数据需要进行前向或后向遍历,但是插入数据时只需要记录本项的前后项即可,所以插入速度较快。
?
--------------------------------------------------
6 HashMap和Hashtable的区别
答:HashMap是Hashtable的轻量级实现(非线程安全的实现),他们都完成了Map接口,主要区别在于
HashMap允许空(null)键值(key),由于非线程安全,效率上可能高于Hashtable。
HashMap允许将null作为一个entry的key或者value,而Hashtable不允许。
HashMap把Hashtable的contains方法去掉了,改成containsvalue和containsKey。因为contains方法容易让人引起误解。
Hashtable继承自Dictionary类,而HashMap是Java1.2引进的Map interface的一个实现。
最大的不同是,Hashtable的方法是Synchronize的,而HashMap不是,在多个线程访问Hashtable时,不需要自己为它的方法实现同步,而HashMap 就必须为之提供外同步。
Hashtable和HashMap采用的hash/rehash算法都大概一样,所以性能不会有很大的差异。
?
--------------------------------------------------
?
7 ArrayList和Vector的区别,HashMap和Hashtable的区别
答:就ArrayList与Vector主要从二方面来说.
一.同步性:Vector是线程安全的,也就是说是同步的,而ArrayList是线程序不安全的,不是同步的
二.数据增长:当需要增长时,Vector默认增长为原来一培,而ArrayList却是原来的一半
就HashMap与HashTable主要从三方面来说。
一.历史原因:Hashtable是基于陈旧的Dictionary类的,HashMap是Java 1.2引进的Map接口的一个实现
二.同步性:Hashtable是线程安全的,也就是说是同步的,而HashMap是线程序不安全的,不是同步的
三.值:只有HashMap可以让你将空值作为一个表的条目的key或value
?
?
?
如何检查一个未排序的数组中是否包含某个特定值,这是一个在Java中非常实用并且频繁使用的操作。检查数组中是否包含特定值可以用多种不同的方式实现,但是时间复杂度差别很大。下面,将为大家展示各种方法及其需要花费的时间。
1.检查数组中是否包含特定值的四种不同方法
1)使用List:
public static boolean useList(String[] arr, String targetValue) { ????return Arrays.asList(arr).contains(targetValue); } |
2)使用Set:
1 2 3 4 | public static boolean useSet(String[] arr, String targetValue) { ????Set<String> set = new HashSet<String>(Arrays.asList(arr)); ????return set.contains(targetValue); } |
3)使用一个简单循环:
1 2 3 4 5 6 7 | public static boolean useLoop(String[] arr, String targetValue) { ????for(String s: arr){ ????????if(s.equals(targetValue)) ????????????return true; ????} ????return false; } |
4)使用Arrays.binarySearch():
注:下面的代码是错误的,这样写出来仅仅为了理解方便。binarySearch()只能用于已排好序的数组中。所以,你会发现下面结果很奇怪。
1 2 3 4 5 6 7 | public static boolean useArraysBinarySearch(String[] arr, String targetValue) { ????int a =? Arrays.binarySearch(arr, targetValue); ????if(a > 0) ????????return true; ????else ????????return false; } |
2.时间复杂度
通过下面的这段代码可以近似比较几个方法的时间复杂度。虽然分别搜索一个大小为5、1K、10K的数组是不够精确的,但是思路是清晰的。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 | public static void main(String[] args) { ????String[] arr = new String[] {? "CD",? "BC", "EF", "DE", "AB"}; ?? ? ????//use list ????long startTime = System.nanoTime(); ????for (int i = 0; i < 100000; i++) { ????????useList(arr, "A"); ????} ????long endTime = System.nanoTime(); ????long duration = endTime - startTime; ????System.out.println("useList:? " + duration / 1000000); ?? ? ????//use set ????startTime = System.nanoTime(); ????for (int i = 0; i < 100000; i++) { ????????useSet(arr, "A"); ????} ????endTime = System.nanoTime(); ????duration = endTime - startTime; ????System.out.println("useSet:? " + duration / 1000000); ?? ? ????//use loop ????startTime = System.nanoTime(); ????for (int i = 0; i < 100000; i++) { ????????useLoop(arr, "A"); ????} ????endTime = System.nanoTime(); ????duration = endTime - startTime; ????System.out.println("useLoop:? " + duration / 1000000); ?? ? ????//use Arrays.binarySearch() ????startTime = System.nanoTime(); ????for (int i = 0; i < 100000; i++) { ????????useArraysBinarySearch(arr, "A"); ????} ????endTime = System.nanoTime(); ????duration = endTime - startTime; ????System.out.println("useArrayBinary:? " + duration / 1000000); } |
结果:
1 2 3 4 | useList:? 13 useSet:? 72 useLoop:? 5 useArraysBinarySearch:? 9 |
对于长度为1K的数组:
1 2 3 4 5 6 | String[] arr = new String[1000]; ?? ? Random s = new Random(); for(int i=0; i< 1000; i++){ ????arr[i] = String.valueOf(s.nextInt()); } |
结果:
1 2 3 4 | useList:? 112 useSet:? 2055 useLoop:? 99 useArrayBinary:? 12 |
对于长度为10K的数组:
1 2 3 4 5 6 | String[] arr = new String[10000]; ?? ? Random s = new Random(); for(int i=0; i< 10000; i++){ ????arr[i] = String.valueOf(s.nextInt()); } |
结果:
1 2 3 4 | useList:? 1590 useSet:? 23819 useLoop:? 1526 useArrayBinary:? 12 |
很明显,使用简单循环的方法比使用其他任何集合效率更高。许多开发者会使用第一种方法,但是它并不是高效的。将数组压入Collection类型中,需要首先将数组元素遍历一遍,然后再使用集合类做其他操作。
如果使用Arrays.binarySearch()方法,数组必须是已排序的。由于上面的数组并没有进行排序,所以该方法不可使用。
实际上,如果你需要借助数组或者集合类高效地检查数组中是否包含特定值,一个已排序的列表或树可以做到时间复杂度为O(log(n)),hashset可以达到O(1)。
标签:
原文地址:http://www.cnblogs.com/baixl/p/4199315.html