标签:
“We are leaving the age of information and entering the age of recommendation” — Chris Anderson in The Long Tail。我们正在远离信息,而进入推荐时代。——克里斯·安德森
在介绍微博推荐算法之前,我们先聊一聊推荐系统和推荐算法。有这样一些问题:推荐系统适用哪些场景?用来解决什么问题、具有怎样的价值?效果如何衡量?
推荐系统诞生很早,但真正被大家所重视,缘起于以”facebook”为代表的社会化网络的兴起和以“淘宝“为代表的电商的繁荣,”选择“的时代已经来临,信息和物品的极大丰富,让用户如浩瀚宇宙中的小点,无所适从。推荐系统迎来爆发的机会,变得离用户更近:
推荐系统的适用场景还有很多,不再一一列举;其主要解决的问题是为用户找到合适的 item(连接和排序),并找到一个合理的理由来解释推荐结果。而问题的解决,就是系统的价值,即建立关联、促进流动和传播、加速优胜劣汰。
推荐算法是实现推荐系统目标的方法和手段。算法与产品相结合,搭载在高效稳定的架构上,才能发挥它的最大功效。
接下来我们说一下微博推荐,微博本身的产品设计,使得即使没有推荐系统,仍然会形成一个大的用户关系网络,实现信息快速传播;而衡量一个事物的价值,一个简单的方法是对比看看保留它和去掉它时的差别。微博需要健康的用户关系网络,保障用户 feed 流的质量,且需要优质信息快速流动,通过传播淘汰低质信息。微博推荐的作用在于加速这一过程,并在特定的情况下控制信息的流向,所以微博推荐的角色是一个加速器和控制器。
最后回到微博推荐算法中来,上面扯了那么多,只是为了让大家能对微博推荐算法有更好的理解。我们的工作,是将微博推荐的目标和需要解决的问题,抽样为一系列的数学问题,然后运用多种数据工具进行求解。
接下来首先用一个图梳理下我们用到的方法和技术,然后再逐一介绍。
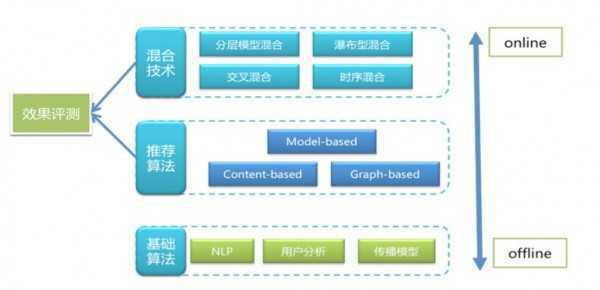
基础及关联算法
这一层算法的主要作用是为微博推荐挖掘必要的基础资源、解决推荐时的通用技术问题、完成必要的数据分析为推荐业务提供指导。
这一部分中常用的算法和技术如下:
分词技术与核心词提取
是微博内容推荐的基础,用于将微博内容转化为结构化向量,包括词语切分、词语信息标注、内容核心词/实体词提取、语义依存分析等。
分类与 anti-spam
用于微博内容推荐候选的分析,包含微博内容分类和营销广告/色情类微博识别;
内容分类采用决策树分类模型实现,共 3 级分类体系,148 个类别;营销广告/色情类微博的识别,采用贝叶斯与最大熵的混合模型。
聚类技术
主要用于热点话题挖掘,以及为内容相关推荐提供关联资源。属于微博自主研发的聚类技术 WVT 算法(word vector topic),依据微博内容特点和传播规律设计。
传播模型与用户影响力分析
开展微博传播模型研究和用户网络影响力分析(包含深度影响力、广度影响力和领域内影响力)。
主要推荐算法
1. Graph-based 推荐算法
微博具有这样的特点:用户贡献内容,社会化途径传播,带来信息的爆炸式传播。之所以称作 graph-based 推荐算法,而不是业界通用的 memory-based 算法,主要原因在于:
从 graph 的宏观角度看,我们的目标是建立一个具有更高价值的用户关系网络,促进优质信息的快速传播,提升 feed 流质量;其中的重要工作是关键节点挖掘、面向关键节点的内容推荐、用户推荐。
对这部分的算法做相应的梳理,如下面的表格:
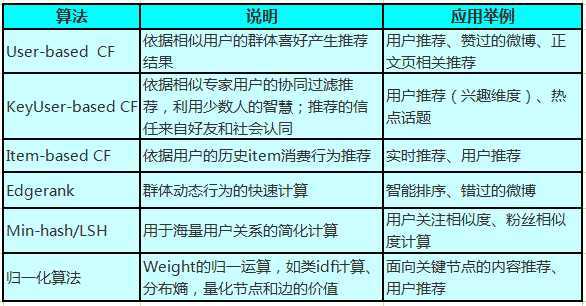
这里的困难点在于 graph 的“边”怎样量化与取舍,依据多个“边”与“节点”的综合评分计算,以及与网络挖掘分析结果的融合。
这部分的算法研发中,产出了如下的数据附产品:

2. Content-based 推荐算法
Content-based 是微博推荐中最常用也是最基础的推荐算法,它的主要技术环节在于候选集的内容结构化分析和相关性运算。
正文页相关推荐是 content-based 应用最广的地方,以它为例,简要的说一下
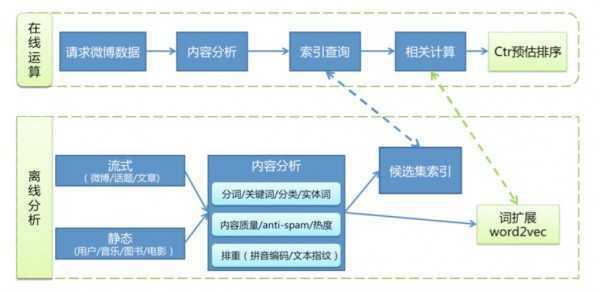
内容分析的很多点已在前面描述过了,这里重点说 2 个地方:
相关计算的技术点在于向量的量化和距离度量,我们通常使用“tf*idf 权重量化 + 余弦距离”或者“topic 概率 + KLD 距离“的两种方法。
3. Model-based 推荐算法
微博作为中国最大的社会化媒体产品,具有海量的用户和信息资源;这就给推荐带来了 2 个挑战:
来源融合与排序
候选的极大丰富,意味着我们有更多的选择,于是我们推荐结果的产生包含两层:多种推荐算法的初选与来源融合排序的精选,为了得到更客观准确的排序结果,我们需要引入机器学习模型,来学习隐藏在用户群体行为背后的规律。
内容动态分类和语义相关
微博 UGC 的内容生产模式,以及信息快速传播和更新的特点,意味着之前人工标注样本,训练静态分类模型的方法已经过时了,我们需要很好的聚类模型把近期的全量信息聚合成类,然后建立语义相关,完成推荐。
Model-based 算法就是为了解决上述的问题,下面是我们两块最重要的机器学习工作:
3. 1 CTR/RPM(每千次推荐关系达成率)预估模型,采用的基本算法为 Logistic regression,下面是我们 CTR 预估模型整体的架构图:
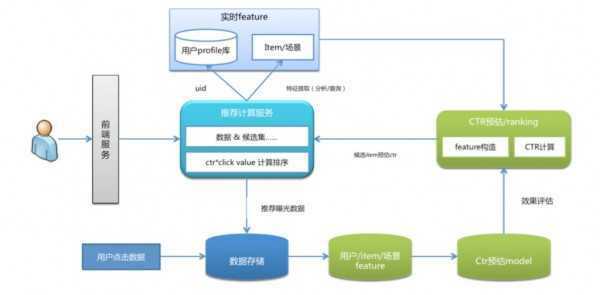
这部分工作包含样本选择、数据清洗、特征提取与选择、模型训练、在线预估和排序。值得一提的是,模型训练前的数据清洗和噪音剔除非常重要,数据质量是算法效果的上界,我们之前就在这个地方吃过亏。
Logisitic regression 是一个 2 分类概率模型
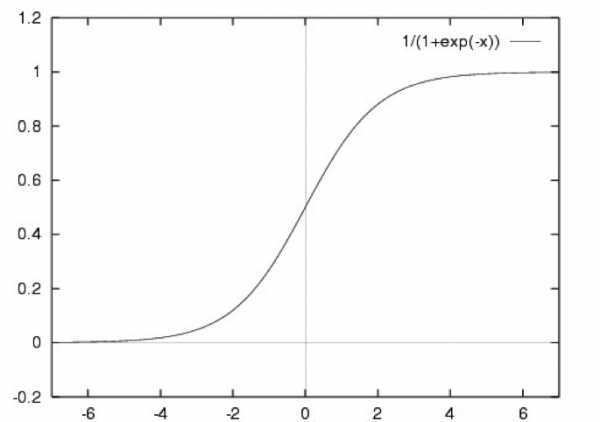
优化的目标在于最大化“样本正确分类概率的连乘值“;我们借助 yahoo 研发的 vowpal_wabbit 机器学习平台来完成模型特征值求解的最优化过程。
3. 2 LFM(Latent Factor Model):LDA、矩阵分解(SVD++、SVD Feature)
LDA 是 2014 年初重点开展的项目,现在已经有了较好的产出,也在推荐线上产品中得到了应用;LDA 本身是一个非常漂亮和严谨的数学模型,下面是我们一个 LDA topic 的例子,仅供参考。
至于矩阵分解,2013 年的时候做过相应的尝试,效果不是特别理想,没有继续投入。
隐语义模型是推荐精度最高的单一模型,其困难在于数据规模大时,计算效率会成为瓶颈;我们在这个地方开展了一些工作,后续会有同学专门介绍这一块。
混合技术
三个臭皮匠顶个诸葛亮,每一种方法都有其局限性,将不同的算法取长补短,各自发挥价值,是极为有效的方式。微博推荐算法主要采用了下面的混合技术:
时序混合:
即在推荐过程的不同时间段,采用不同的推荐算法;以正文页相关推荐为例,在正文页曝光的前期阶段,采用 content-based + ctr 预估的方法生成推荐结果,待产生的足量可信的用户点击行为后,再采用 user-based 协同过滤的方法得到推荐结果,如下图所示:
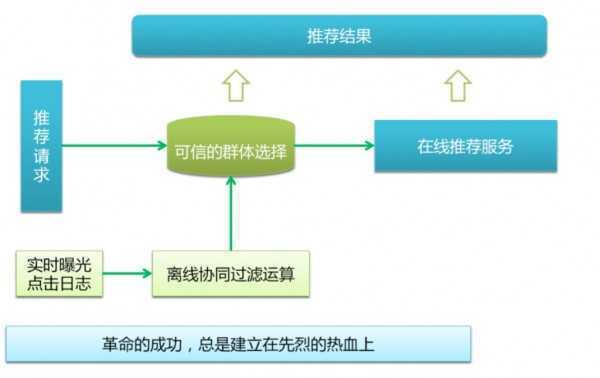
这样利用 content-based 很好的解决了冷启动的问题,又充分发挥了 user-based CF 的作用,实现1+1>2 的效果。
分层模型混合:
很多情况下,一个模型无法很好的得到想要的效果,而分层组合往往会取得比较好的效果,分层模型混合即“将上一层模型的输出作为下层模型的特征值,来综合训练模型,完成推荐任务“。比如我们在做微博首页右侧的 ctr 预估排序时,采用分层逻辑回归模型,解决了不同产品间特征天然缺失与样本量差异、曝光位置带来的效果偏差等问题。
瀑布型混合:
这类混合技术思路非常简单,即在推荐候选非常丰富的情况下,采用逐层过滤的方法的得到推荐结果,通常将运算快、区分度低的算法放在前面,完成大量候选集的筛选;将运算慢、区分度高的算法放在后面,精细计算剩下的小规模集合。这类混合在微博推荐中大量使用,我们采用各种轻量算法完成候选集粗选,然后采用 ctr 预估做精细化排序。
交叉混合:
各类推荐算法中子技术,可以在另外的推荐算法中综合使用,比如 content-based 在相关性计算中积累的距离计算方法,可以很好的应用在协同过滤的量化计算中。实际的例子,我们将研究 LDA 时积累的向量计算方法成功的应用到用户推荐中。
Online 与 offline
微博数据的特点(海量、多样、静态与动态数据混在一起),决定了大部分推荐产品的结果需要同时借助 online 和 offline 的计算来完成。从系统和算法设计的角度,这是一个“重”与“轻”的问题,计算分解和组合是关键,我们需要将对时间不敏感的重型计算放在 offline 端,而将时间敏感性强的轻型快速计算放在 online 端。几种我们常用的方式如下图:
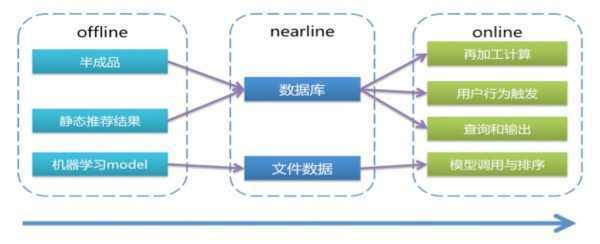
Online 需要简单可靠的算法,快速得到结果;简要说明下上面的图,如下
半成品有以下的 3 中形式
1)计算过程拆解的离线部分,如 user-based CF 中的用户相似度,online 通过数据库读取后在线计算完成 user-based 推荐。
2)离线挖掘的优质候选集,如正文页相关推荐的内容候选集,online 通过索引获取到数据后,再通过相关性和 ctr 预估排序生成推荐结果。
3)具有较高相似度的推荐结果集,如 offline 计算好粉丝相似高的用户,在线对用户行为做出实时反馈,实时补充推荐与其刚关注用户相似的用户。
此外,我们也有直接 online 计算完成的推荐结果,如首页右侧话题推荐,由于用户对话题需求的差异非常小,它基本上是一个排行榜的需求,但热门微博也可以有精巧的设计,我们采用了一个曝光动态收益模型,通过上一段时段的(点击收益-曝光成本)来控制下一时段的 item 曝光几率,取得了非常好的效果,ctr 和导流量有 3 倍以上的提升。
不同类型的推荐结果,要辅以不同的推荐理由,这一点需要前端的多种展示尝试和 offline 的日志分析。
效果评测
算法效果的度量方式决定了大家努力的方向,而对于不同类型的推荐,最好根据产品的定位和目标,采用不同的标准体系去衡量工作结果。实际效果的评测分为 3 个层次:用户满意度、产品层指标(如 ctr)、算法层指标,我们的效果评测也会分为人工评测、线上A/B测试、离线算法效果评测 3 种。
产品指标的制定,应该从产品期望达成的目标出发,体现用户满意度。
对算法离线评测而言,关键的是找到一套合理的算法评测指标去拟合产品层指标,因为算法离线评测总是在上线前进行,这个对应做的越好,算法的优化成果才能更好的转化为线上的产品指标。
下图为我们的算法离线效果评测的架构图
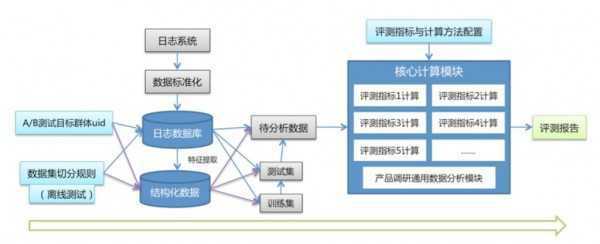
常用的离线评测指标有:RMSE、召回率、AUC、用户内多样性、用户间多样性、新颖性等。对于不同的产品有不同的组合指标去衡量,比如用户推荐中“用户间多样性”非常重要,而热点话题却可以允许用户间有较大的结果重合度。
标签:
原文地址:http://www.cnblogs.com/abc8023/p/4200812.html