标签:
原文:SQL开发中容易忽视的一些小地方(四) 本篇我想针对网上一些对于非聚集索引使用场合的某些说法进行一些更正. 下面引用下MSDN对于非聚集索引结构的描述.
非聚集索引结构:
1:非聚集索引与聚集索引具有相同的 B 树结构,它们之间的显著差别在于以下两点: * 如果表有聚集索引或索引视图上有聚集索引,则行定位器是行的聚集索引键。如果聚集索引不是唯一的索引,SQL Server 将添加在内部生成的值(称为唯一值)以使所有重复键唯一。此四字节的值对于用户不可见。仅当需要使聚集键唯一以用于非聚集索引中时,才添加该值。SQL Server 通过使用存储在非聚集索引的叶行内的聚集索引键搜索聚集索引来检索数据行。
网络观点:order by 子句中使用了的列,可以在此列上建非聚集索引以提高查询速度.
原文地址:http://gocom.primeton.com/blog10697_1221.htm
本人观点:总之一句话,环境不同,表结构不同,数据分布不同,最终结果也不一定相同.
2008-10-05 03:42:09.000
订单表和会员表有一个关联字段为proxyID,各自均建有索引.查询语句如下:
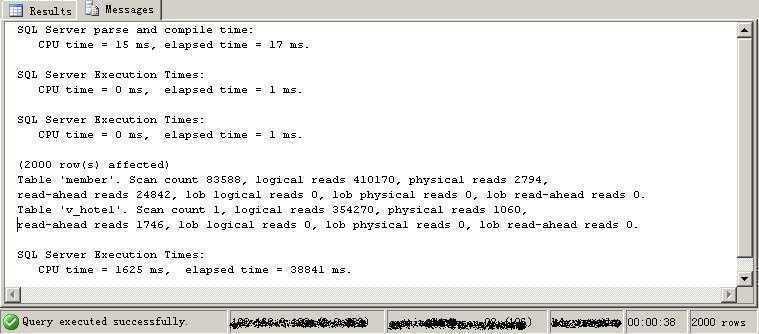
情况一:在create_date上创建非聚集索引.执行的IO和所用时间消耗如下图:可以看出这种情况对memer表进行了大量的表扫描. 83588次.
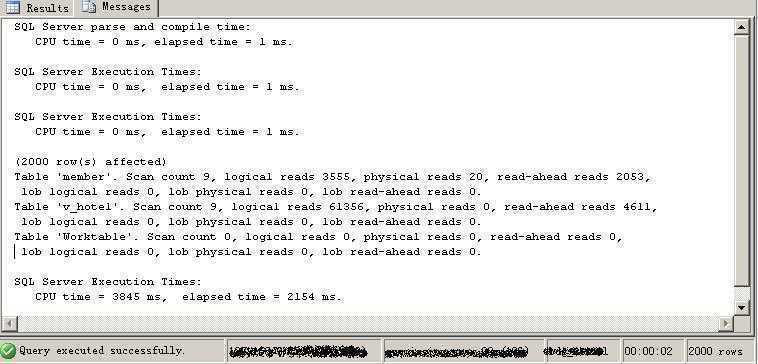
情况二:删除create_date上的索引,按理来说应该会比有索引会慢些,下面是执行的IO和时间消耗图:
3:创建索引的查询会比没有创建索引的查询早一步显示数据,不过最终完成的时间要长.
测试未知难题:
1:就查询速度来说,是早一步在查询分析器中显示数据的查询快还是说要看最终完全的时间来判断.(create_date创建索引的情况会更早显示数据,不过总共用时会比不创建索引的慢)园友zping曾告诉我不要看时间要看IO数量.不知道大家是怎么分析的.
2:在一个字段上创建索引为什么会引发member表的多次表扫描.
测试说明:由于SQL2005有缓存功能,所有两次查询的时间段并不相同,但数据量都差不多.
根据园友 perfectdesign的观点,order by 时,如果字段是聚集索引将会是最优的,这点我个人以及MSDN都同意,奇怪的是,上面的语句中,leave_date上即聚集索引,然后order by leave_date desc,然而也会产生5万多次的member表扫描,好像是order by 索引字段,无论是聚集还是非聚集都会大量增加对member表的扫描.真是百思不得其解.下面是详细的ID情况:
(2000 row(s) affected)
Table ‘member‘. Scan count 52796, logical reads 234885, physical reads 0, read-ahead reads 3687, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table ‘v_hotel‘. Scan count 1, logical reads 3121, physical reads 0, read-ahead reads 28, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
测试结论:这种情况足以说明对于order by 字段创建索引并不一定能发挥非聚集索引的优势,至于其中原因本人不才,目前并无答案,如大家有答案还望指教一二.数据库的调优虽然有一定的原则及准则,但这些所谓准则并一定全对.本人觉的都仅供参考,还是要按实际情况来分析.
下面贴下MSDN对于非聚集索引应用场合的说明,我觉的还是可能参考的:
在创建非聚集索引之前,应先了解访问数据的方式。考虑对具有以下属性的查询使用非聚集索引:
注:
本文引用:MSDN
标签:
原文地址:http://www.cnblogs.com/lonelyxmas/p/4203019.html