标签:
前言
在前面的文章中,涉及到的机器学习算法均为监督学习算法。
所谓监督学习,就是有训练过程的学习。再确切点,就是有 "分类标签集" 的学习。
现在开始,将进入到非监督学习领域。从经典的聚类问题展开讨论。所谓聚类,就是事先并不知道具体分类方案的分类 (允许知道分类个数)。
本文将介绍一个最为经典的聚类算法 - K-Means 聚类算法以及它的两种实现。
现实中的聚类分析问题 - 总统大选
假设 M 国又开始全民选举总统了,目前 Mr.OBM 的投票率为48%(投票数占所有选民人数的百分比),而 Mr.MKN 的为47%,而剩下的一部分出于【种种原因】没有投票。
做为其中某个阵营的人,自然是希望能够尽可能的争取到这些剩余的票 -因为这完全可能影响最终选举结果。
然而,你不可能争取到这些人的所有投票,因为你满足某个群体的人,也许就伤害到了另一群人的利益。
一个很不错的想法是将这些人分为 K 个群体,然后主要对其中人数最多的几个群体做工作。这就需要使用到聚类的策略了。
聚类策略是搜集剩余选民的用户信息(各种满意/不满意的信息),将这些信息输入进聚类算法,然后对聚类结果中人数最多的簇的选民做思想工作。
可能你会发现某个簇的选民都是一个社区的,一个宗教信仰的,或者具有某些共性。这样就方便各种各样的拉票活动了。
K-Means 聚类算法
K,指的是它可以发现 K 个簇;Means,指的是簇中心采用簇所含的值的均值来计算。
下面先给出伪代码:
1 创建 k 个点作为起始质心 (随机选择): 2 当任意一个点的簇分配结果发生改变的时候: 3 对数据集中的每个数据点: 4 对每个质心: 5 计算质心与数据点之间的距离 6 将数据点分配到距其最近的簇 7 对每一个簇: 8 求出均值并将其更新为质心
然后是一个具体实现Python程序:
1 #!/usr/bin/env python 2 # -*- coding:UTF-8 -*- 3 4 ‘‘‘ 5 Created on 2015-01-05 6 7 @author: fangmeng 8 ‘‘‘ 9 10 from numpy import * 11 12 #================================== 13 # 输入: 14 # fileName: 数据文件名(含路径) 15 # 输出: 16 # dataMat: 数据集 17 #================================== 18 def loadDataSet(fileName): 19 ‘载入数据文件‘ 20 21 dataMat = [] 22 fr = open(fileName) 23 for line in fr.readlines(): 24 curLine = line.strip().split(‘\t‘) 25 fltLine = map(float,curLine) 26 dataMat.append(fltLine) 27 return dataMat 28 29 #================================================== 30 # 输入: 31 # vecA: 样本a 32 # vecB: 样本b 33 # 输出: 34 # sqrt(sum(power(vecA - vecB, 2))): 样本距离 35 #================================================== 36 def distEclud(vecA, vecB): 37 ‘计算样本距离‘ 38 39 return sqrt(sum(power(vecA - vecB, 2))) 40 41 #=========================================== 42 # 输入: 43 # dataSet: 数据集 44 # k: 簇个数 45 # 输出: 46 # centroids: 簇划分集合(每个元素为簇质心) 47 #=========================================== 48 def randCent(dataSet, k): 49 ‘随机初始化质心‘ 50 51 n = shape(dataSet)[1] 52 centroids = mat(zeros((k,n)))#create centroid mat 53 for j in range(n):#create random cluster centers, within bounds of each dimension 54 minJ = min(dataSet[:,j]) 55 rangeJ = float(max(dataSet[:,j]) - minJ) 56 centroids[:,j] = mat(minJ + rangeJ * random.rand(k,1)) 57 return centroids 58 59 #=========================================== 60 # 输入: 61 # dataSet: 数据集 62 # k: 簇个数 63 # distMeas: 距离生成器 64 # createCent: 质心生成器 65 # 输出: 66 # centroids: 簇划分集合(每个元素为簇质心) 67 # clusterAssment: 聚类结果 68 #=========================================== 69 def kMeans(dataSet, k, distMeas=distEclud, createCent=randCent): 70 ‘K-Means基本实现‘ 71 72 m = shape(dataSet)[0] 73 # 簇分配结果矩阵。一列为簇分类结果,一列为误差。 74 clusterAssment = mat(zeros((m,2))) 75 # 创建原始质心集 76 centroids = createCent(dataSet, k) 77 # 簇更改标记 78 clusterChanged = True 79 80 while clusterChanged: 81 clusterChanged = False 82 83 # 每个样本点加入其最近的簇。 84 for i in range(m): 85 minDist = inf; minIndex = -1 86 for j in range(k): 87 distJI = distMeas(centroids[j,:],dataSet[i,:]) 88 if distJI < minDist: 89 minDist = distJI; minIndex = j 90 if clusterAssment[i,0] != minIndex: clusterChanged = True 91 clusterAssment[i,:] = minIndex,minDist**2 92 93 # 更新簇 94 for cent in range(k):#recalculate centroids 95 ptsInClust = dataSet[nonzero(clusterAssment[:,0].A==cent)[0]] 96 centroids[cent,:] = mean(ptsInClust, axis=0) 97 98 return centroids, clusterAssment 99 100 def main(): 101 ‘k-Means聚类操作展示‘ 102 103 datMat = mat(loadDataSet(‘/home/fangmeng/testSet.txt‘)) 104 myCentroids, clustAssing = kMeans(datMat, 4) 105 106 #print myCentroids 107 print clustAssing 108 109 if __name__ == "__main__": 110 main()
测试结果:
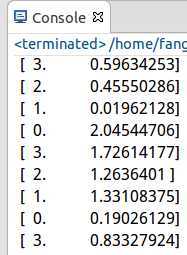
K-Means性能优化
主要有两种方式:
1. 分解最大SSE (误差平方和)的簇
PS:直接在簇内执行一次 k=2 的 K-Means 聚类即可。
2. 合并距离最小的簇 或者 合并SSE增幅最小的两个簇
基于这两种最基本优化策略,有一种更为科学的聚类算法 - 二分K-Means算法,下面进行详细介绍。
二分K-Means算法
该算法大致思路为:首先将所有的点作为一个簇,然后将该簇一分为二。之后选择其中一个簇继续划分。
选择方法自然是选择SSE增加更小的那个方式。
如此不断 "裂变",直到得到用户指定数目的簇。
伪代码:
将所有点视为一个簇: 当簇数目小于k时: 对于每一个簇: 计算SSE 在给定的簇上面进行 k=2 的K-Means聚类 计算将簇一分为二后的SSE 选择使得误差最小的那个簇进行划分操作
具体实现函数:
1 #====================================== 2 # 输入: 3 # dataSet: 数据集 4 # k: 簇个数 5 # distMeas: 距离生成器 6 # 输出: 7 # mat(centList): 簇划分集合(每个元素为簇质心) 8 # clusterAssment: 聚类结果 9 #====================================== 10 def biKmeans(dataSet, k, distMeas=distEclud): 11 ‘二分K-Means聚类算法‘ 12 13 m = shape(dataSet)[0] 14 # 聚类结果数据结构 15 clusterAssment = mat(zeros((m,2))) 16 # 原始质心 17 centroid0 = mean(dataSet, axis=0).tolist()[0] 18 centList =[centroid0] 19 20 # 统计原始SSE 21 for j in range(m): 22 clusterAssment[j,1] = distMeas(mat(centroid0), dataSet[j,:])**2 23 24 # 循环执行直到得到k个簇 25 while (len(centList) < k): 26 # 最小SSE 27 lowestSSE = inf 28 # 找到最适合分裂的簇进行分裂 29 for i in range(len(centList)): 30 ptsInCurrCluster = dataSet[nonzero(clusterAssment[:,0].A==i)[0],:] 31 centroidMat, splitClustAss = kMeans(ptsInCurrCluster, 2, distMeas) 32 sseSplit = sum(splitClustAss[:,1]) 33 sseNotSplit = sum(clusterAssment[nonzero(clusterAssment[:,0].A!=i)[0],1]) 34 35 if (sseSplit + sseNotSplit) < lowestSSE: 36 bestCentToSplit = i 37 bestNewCents = centroidMat 38 bestClustAss = splitClustAss.copy() 39 lowestSSE = sseSplit + sseNotSplit 40 41 # 本次划分信息 42 bestClustAss[nonzero(bestClustAss[:,0].A == 1)[0],0] = len(centList) 43 bestClustAss[nonzero(bestClustAss[:,0].A == 0)[0],0] = bestCentToSplit 44 45 # 更新簇集 46 centList[bestCentToSplit] = bestNewCents[0,:].tolist()[0] 47 centList.append(bestNewCents[1,:].tolist()[0]) 48 # 更新聚类结果集 49 clusterAssment[nonzero(clusterAssment[:,0].A == bestCentToSplit)[0],:]= bestClustAss 50 51 return mat(centList), clusterAssment
测试结果:
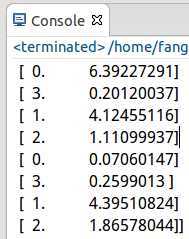
小结
1. KMeans的用途很广泛,再举个例子吧:比如你计划要去中国100个城市旅游,那么如何规划路线呢?
---> 可以采用聚类的方法,将这些城市聚到几个簇里面,然后一个 ”簇"一个 "簇" 的进行游玩。质心就相当于机场,误差平方和就相当于游玩城市到质心的距离 :)
2. KMeans算法是很常用的聚类算法,然而,这里也要提一提它的缺点 - k值选取很难。这个话题也产生了很多研究,文章。有兴趣的读者可以进一步研究。
标签:
原文地址:http://www.cnblogs.com/scut-fm/p/4206247.html