标签:
数据:数据库文章条数超过200W,每天3K左右的增加。
现状:Lucene 2.9 + 盘古分词,读写分离。索引文件达到1G多,列表读取越来愈慢。
需求:前台页面实现列表秒出,检索秒出,提升用户体验。
---------------------------------------------------------------------------------
已经略过 MS-SQL分区、分库、全文索引... 上MongoDB
---------------------------------------------------------------------------------
经过:把 Lucene 2.9 + 盘古分词 => MongoDB + cache,线下测试效果非常的好
构建好历史数据之后,放到线上(IBM System X3650 7979I09机器 内存16G )试运行,傻眼了,如图:
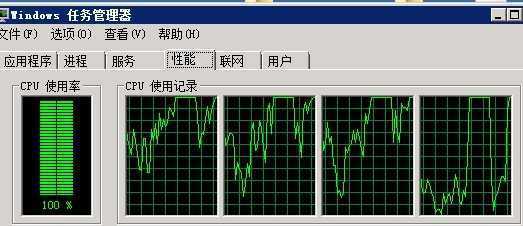
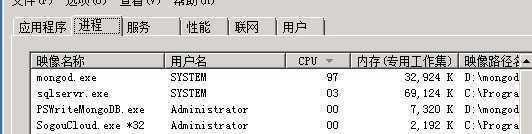
直觉有地方出问题了。但是任性了一把,数据库导出、迁移到 IBM System X3650 M4 机器 内存24G上,CPU经常跳到80%;
但是前台列表速度依然很快,赞一个Mongo。同机的其他应用就非常慢。
乐趣与焦灼一起来了,打开 mongostat、mongotop 也没发现异常。 查了一通是NUMA。忽然想起来MongoDB 运行起来时给出的警告了。
当天去机房,修改BIOS => Memory => Scoket Inter leave 为 Non-NUMA即可。 如图:
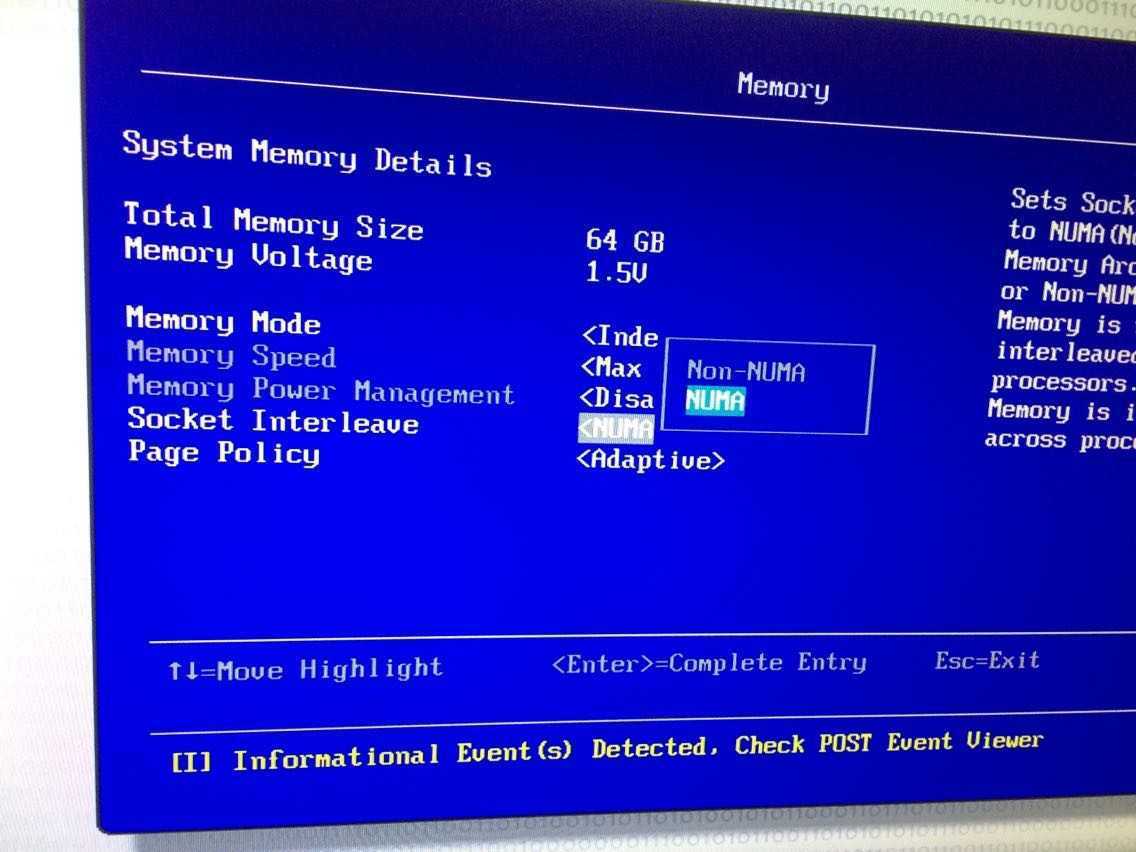
重启机器,MongoDB进程CPU在 0附近了。
--------------------------------------------------------------------------------------------------------
微软NUMA方案:http://technet.microsoft.com/zh-cn/library/ms345345(v=sql.105).aspx
Mongo部署到Win2008 上 CPU持续100%,改为 Non- NUMA 即可
标签:
原文地址:http://www.cnblogs.com/recordman/p/4213659.html