标签:
//检测浏览器是否支持DOM2级XML var hasXmlDom = document.implementation.hasFeature(‘XML‘, ‘2.0‘); //检测浏览器是否支持DOM3级XPath var supportsXPath = document.implementation.hasFeature(‘XPath‘, ‘3.0‘);
//创建一个新的 文档元素为<root>的xml文档 var xmldom = document.implementation.createDocument("", "root", null); alert(xmldom.documentElement.tagName); //"root" var child = xmldom.createElement("child"); xmldom.documentElement.appendChild(child);
createDocument方法每一个参数为命名空间、第三个参数为文档类型。(创建一个XML DOM文档没有默认的命名空间,也没有文档类型)
但即使这样也必须传入相应的参数,即使你不需要指定命名空间和文档类型。
为了将XML解析为DOM文档,FireFox引入了DOMParser类型。来看一下如何使用。
var parser = new DOMParser();//firefox引入DOMParser var xmldom = parser.parseFromString("<root><child/></root>", "text/xml");// 要解析的xml字符串 第二个参数为内容类型 alert(xmldom.documentElement.tagName); //"root" alert(xmldom.documentElement.firstChild.tagName); //"child" var anotherChild = xmldom.createElement("child"); xmldom.documentElement.appendChild(anotherChild); var children = xmldom.getElementsByTagName("child"); alert(children.length); //2
DOMParser只能解析格式良好的XML,那如果解析发生错误,我们应该怎么处理呢,看代码
var parser = new DOMParser(), xmldom, errors; try { xmldom = parser.parseFromString("<root>", "text/xml"); errors = xmldom.getElementsByTagName("parsererror");//如果发生错误将会返回一个文档元素是<parsererror> if (errors.length > 0){ throw new Error("XML Parsing Error:" + (new XMLSerializer()).serializeToString(xmldom, "text/xml")); } } catch (ex) { alert(ex.message); }
上述我们讲了如何把将XML解析为DOM文档,那如果我们需要将DOM文档序列化为XML字符串,怎么办呢,这时XMLSerializer登场了,创建好XMLSerializer实例后我们只需要把文档传入给serializeToString方法即可。看代码:
var parser = new DOMParser(); var xmldom = parser.parseFromString("<root><child/></root>", "text/xml"); //convert back into XML var serializer = new XMLSerializer();//先创建XMLSerializer实例 var xml = serializer.serializeToString(xmldom);//将文档传入到serializeToString alert(xml);
XMLSerializer可以序列化任何有效的DOM对象,不仅仅包括个别的节点,也可以是HTML文档。但如果把非DOM对象传入给serializeToString方法将会导致错误。
//ie8及之前版本的xml function createDocument(){ if (typeof arguments.callee.activeXString != "string"){ var versions = ["MSXML2.DOMDocument.6.0", "MSXML2.DOMDocument.3.0", "MSXML2.DOMDocument"]; for (var i=0,len=versions.length; i < len; i++){ try { var xmldom = new ActiveXObject(versions[i]); arguments.callee.activeXString = versions[i]; return xmldom; } catch (ex){ //skip } } } return new ActiveXObject(arguments.callee.activeXString);//这里用了“惰性载入”方式进行了createDocument函数的优化 }
在同步方式下,调用load方法加载好xml文件之后就可以立即解析并执行相关的xml处理了。
用到了example.xml文件代码如下:
<?xml version="1.0"?> <root><child/></root>
js同步加载的代码:
var xmldom = createDocument();//这里用到了上面的createDocument方法 xmldom.async = false; xmldom.load("example.xml"); if (xmldom.parseError != 0) { alert("An error occurred:\nError Code: " + xmldom.parseError.errorCode + "\n"//错误类型的数值编码 + "Line: " + xmldom.parseError.line + "\n"//发生错误的行 + "Line Pos: " + xmldom.parseError.linepos + "\n"//发生错误的行中的字符 + "Reason: " + xmldom.parseError.reason);//错误的具体原因 } else { alert(xmldom.documentElement.tagName); //"root" alert(xmldom.documentElement.firstChild.tagName); //"child" var anotherChild = xmldom.createElement("child"); xmldom.documentElement.appendChild(anotherChild); var children = xmldom.getElementsByTagName("child"); alert(children.length); //2 alert(xmldom.xml);/*<?xml version="1.0"?><root><child/></root>*/ }
var xmldom = createDocument(); xmldom.async = true;//设置为异步 xmldom.onreadystatechange = function () {//onreadystatechange事件绑定必须在调用load方法之前 if (xmldom.readyState == 4) {//表示xml文件已经全部加载完毕 readyState表示就绪状态 if (xmldom.parseError != 0) { alert("An error occurred:\nError Code: " + xmldom.parseError.errorCode + "\n" + "Line: " + xmldom.parseError.line + "\n" + "Line Pos: " + xmldom.parseError.linepos + "\n" + "Reason: " + xmldom.parseError.reason); } else { //在方法内部必须使用xmldom而不能使用this对象 alert(xmldom.documentElement.tagName); //"root" alert(xmldom.documentElement.firstChild.tagName); //"child" var anotherChild = xmldom.createElement("child"); xmldom.documentElement.appendChild(anotherChild); var children = xmldom.getElementsByTagName("child"); alert(children.length); //2 alert(xmldom.xml); } } }; xmldom.load("example.xml");
将XML转换为DOM对象
function parseXml(xml){ var xmldom = null; if (typeof DOMParser != "undefined") {//code for Mozilla, Firefox, Opera, etc. xmldom = (new DOMParser()).parseFromString(xml, "text/xml"); var errors = xmldom.getElementsByTagName("parsererror"); if (errors.length){ throw new Error("XML parsing error:" + errors[0].textContent); } } else if (typeof ActiveXObject != "undefined") {//code for IE xmldom = createDocument(); xmldom.loadXML(xml); if (xmldom.parseError != 0){ throw new Error("XML parsing error: " + xmldom.parseError.reason); } } else { throw new Error("No XML parser available."); } return xmldom; }
将DOM对象转换为XML
function serializeXml(xmldom){ if (typeof XMLSerializer != "undefined"){//code for Mozilla, Firefox, Opera, etc. return (new XMLSerializer()).serializeToString(xmldom); } else if (typeof xmldom.xml != "undefined") {//code for IE return xmldom.xml; } else { throw new Error("Could not serialize XML DOM."); } }
讲到xml自然而然不会少了XPath,DOM3级XPath规范定义的类型中,最重要的两个类型是XPathEvaluator和XPathResult
XPathEvaluator用于在特定的上下文中对XPath表达式求值。它主要有以下方法:

主要讲一个evaludate方法各个参数的含义
expression:XPath表达式
context:上下文节点
nsresolver:命名空间求解器
type:返回结果的类型
result:保存结果的 XPathResult对象

看Demo示例:
var xmldom = (new DOMParser()).parseFromString("<employees><employee title=\"Software Engineer\"><name>Nicholas C. Zakas</name></employee><employee title=\"Salesperson\"><name>Jim Smith</name></employee></employees>", "text/xml"); var serializer = new XMLSerializer(); var result = xmldom.evaluate("employee/name", xmldom.documentElement, null, XPathResult.ORDERED_NODE_ITERATOR_TYPE, null); //XPathResult.ORDERED_NODE_ITERATOR_TYPE 为最常用的结果类型 var message = ""; var count = 0; var element = result.iterateNext(); while (element) { message += serializer.serializeToString(element) + "\n"; count++; element = result.iterateNext();//必须使用iterateNext方法从节点中取得匹配的节点 } message = "There are " + count + " matching nodes.\n" + message; alert(message);
var xmldom = (new DOMParser()).parseFromString("<employees><employee title=\"Software Engineer\"><name>Nicholas C. Zakas</name></employee><employee title=\"Salesperson\"><name>Jim Smith</name></employee></employees>", "text/xml"); var serializer = new XMLSerializer(); var result = xmldom.evaluate("employee/name", xmldom.documentElement, null, XPathResult.ORDERED_NODE_SNAPSHOT_TYPE, null); //XPathResult.ORDERED_NODE_SNAPSHOT_TYPE 快照结果类型 var message = "There are " + result.snapshotLength + " matching nodes.\n"; var count = 0; if (result != null){ for (var i = 0; i < result.snapshotLength; i++) { //如果是快照结果类型,则必须使用snapshotItem方法和snapshotLength属性 message += serializer.serializeToString(result.snapshotItem(i)) + "\n"; } } alert(message);
var xmldom = (new DOMParser()).parseFromString("<employees><employee title=\"Software Engineer\"><name>Nicholas C. Zakas</name></employee><employee title=\"Salesperson\"><name>Jim Smith</name></employee></employees>", "text/xml"); var serializer = new XMLSerializer(); var result = xmldom.evaluate("employee/name", xmldom.documentElement, null, XPathResult.FIRST_ORDERED_NODE_TYPE, null); //XPathResult.FIRST_ORDERED_NODE_TYPE 返回第一个匹配的节点 if (result != null){ alert(serializer.serializeToString(result.singleNodeValue));//通过singleNodeValue属性获得其值 }
var xmldom = (new DOMParser()).parseFromString("<employees><employee title=\"Software Engineer\"><name>Nicholas C. Zakas</name></employee><employee title=\"Salesperson\"><name>Jim Smith</name></employee></employees>", "text/xml"); var result = xmldom.evaluate("employee/name", xmldom.documentElement, null, XPathResult.BOOLEAN_TYPE, null); alert(result.booleanValue);
var xmldom = (new DOMParser()).parseFromString("<employees><employee title=\"Software Engineer\"><name>Nicholas C. Zakas</name></employee><employee title=\"Salesperson\"><name>Jim Smith</name></employee></employees>", "text/xml"); var result = xmldom.evaluate("count(employee/name)", xmldom.documentElement, null, XPathResult.NUMBER_TYPE, null); alert(result.numberValue);
var xmldom = (new DOMParser()).parseFromString("<employees><employee title=\"Software Engineer\"><name>Nicholas C. Zakas</name></employee><employee title=\"Salesperson\"><name>Jim Smith</name></employee></employees>", "text/xml"); var result = xmldom.evaluate("employee/name", xmldom.documentElement, null, XPathResult.STRING_TYPE, null); alert(result.stringValue);
处理命名空间的两种方法:
看代码:
var xmldom = (new DOMParser()).parseFromString("<?xml version=\"1.0\"?><wrox:books xmlns:wrox=\"http://www.wrox.com/\"><wrox:book><wrox:title>Professional JavaScript for Web Developers</wrox:title><wrox:author>Nicholas C. Zakas</wrox:author></wrox:book><wrox:book><wrox:title>Professional Ajax</wrox:title><wrox:author>Nicholas C. Zakas</wrox:author><wrox:author>Jeremy McPeak</wrox:author><wrox:author>Joe Fawcett</wrox:author></wrox:book></wrox:books>", "text/xml"); var nsresolver = xmldom.createNSResolver(xmldom.documentElement); var result = xmldom.evaluate("wrox:book/wrox:author", xmldom.documentElement, nsresolver, XPathResult.ORDERED_NODE_SNAPSHOT_TYPE, null); alert(result.snapshotLength);
var xmldom = (new DOMParser()).parseFromString("<?xml version=\"1.0\"?><wrox:books xmlns:wrox=\"http://www.wrox.com/\"><wrox:book><wrox:title>Professional JavaScript for Web Developers</wrox:title><wrox:author>Nicholas C. Zakas</wrox:author></wrox:book><wrox:book><wrox:title>Professional Ajax</wrox:title><wrox:author>Nicholas C. Zakas</wrox:author><wrox:author>Jeremy McPeak</wrox:author><wrox:author>Joe Fawcett</wrox:author></wrox:book></wrox:books>", "text/xml"); var nsresolver = function(prefix){ switch(prefix){ case "wrox": return "http://www.wrox.com/"; } }; var result = xmldom.evaluate("wrox:book/wrox:author", xmldom.documentElement, nsresolver, XPathResult.ORDERED_NODE_SNAPSHOT_TYPE, null); alert(result.snapshotLength);
用demo示例说话:
demo中用到的xml文件:
<?xml version="1.0"?> <employees> <employee title="Software Engineer"> <name>Nicholas C. Zakas</name> </employee> <employee title="Salesperson"> <name>Jim Smith</name> </employee> </employees>
var xmldom = createDocument(); xmldom.async = false; xmldom.load("employees.xml"); var names = xmldom.documentElement.selectNodes("employee/name"); var message = "There are " + names.length + " matching nodes.\n"; for (var i=0, len=names.length; i < len; i++) { message += names[i].xml + "\n"; } alert(message);
var xmldom = createDocument(); xmldom.loadXML("<?xml version=\"1.0\"?><wrox:books xmlns:wrox=\"http://www.wrox.com/\"><wrox:book><wrox:title>Professional JavaScript for Web Developers</wrox:title><wrox:author>Nicholas C. Zakas</wrox:author></wrox:book><wrox:book><wrox:title>Professional Ajax</wrox:title><wrox:author>Nicholas C. Zakas</wrox:author><wrox:author>Jeremy McPeak</wrox:author><wrox:author>Joe Fawcett</wrox:author></wrox:book></wrox:books>"); xmldom.setProperty("SelectionNamespaces", "xmlns:wrox=‘http://www.wrox.com/‘");//在IE下如果要设置命名空间的话 则需要这样 var result = xmldom.documentElement.selectNodes("wrox:book/wrox:author"); alert(result.length);
/* *@desc:公共函数 利用xpath在规定的命名空间和上下文中选择单个节点 *@param--context:上下文 *@param--expression:xpath表达式 *@param--namespaces:命名空间 */ function selectSingleNode(context, expression, namespaces) { var doc = (context.nodeType != 9 ? context.ownerDocument : context);//doc变量保存对xml文档的引用 if (typeof doc.evaluate != "undefined") {//检测文档中是否存在evaluate方法 也就是是否支持DOM3级XPath var nsresolver = null;//初始化 if (namespaces instanceof Object) {//检测传入的namespaces对象 nsresolver = function (prefix) {//如果提供了命名空间 将其设置为一个函数 return namespaces[prefix];//返回命名空间的URI }; } var result = doc.evaluate(expression, context, nsresolver, XPathResult.FIRST_ORDERED_NODE_TYPE, null);//在确定是节点之后再返回该结果 return (result !== null ? result.singleNodeValue : null); } else if (typeof context.selectSingleNode != "undefined") {//code for IE 检查context节点中是否存在selectSingleNode方法 //create namespace string if (namespaces instanceof Object) {//有选择的构建命名空间信息 var ns = ""; for (var prefix in namespaces) {//如果传入了namespaces对象 迭代其属性并以适应格式创建一个字符串 if (namespaces.hasOwnProperty(prefix)) {//确保 对Object.prototype的任何修改不会影响到当前函数 ns += "xmlns:" + prefix + "=‘" + namespaces[prefix] + "‘ "; } } doc.setProperty("SelectionNamespaces", ns); } return context.selectSingleNode(expression);//返回结果 } else { throw new Error("No XPath engine found.");//找不到Xpath处理引擎 } } /* *@desc:公共函数 利用xpath在规定的命名空间和上下文中选择满足条件的结果集 *@param--context:上下文 *@param--expression:xpath表达式 *@param--namespaces:命名空间 */ function selectNodes(context, expression, namespaces) { var doc = (context.nodeType != 9 ? context.ownerDocument : context); if (typeof doc.evaluate != "undefined") { var nsresolver = null; if (namespaces instanceof Object) { nsresolver = function (prefix) { return namespaces[prefix]; }; } var result = doc.evaluate(expression, context, nsresolver, XPathResult.ORDERED_NODE_SNAPSHOT_TYPE, null);//使用有序快照结果类型 如果没有找到匹配项的情况下返回一个数组 var nodes = new Array(); if (result !== null) { for (var i = 0, len = result.snapshotLength; i < len; i++) { nodes.push(result.snapshotItem(i)); } } return nodes; } else if (typeof context.selectNodes != "undefined") {//code for IE //create namespace string if (namespaces instanceof Object) { var ns = ""; for (var prefix in namespaces) { if (namespaces.hasOwnProperty(prefix)) { ns += "xmlns:" + prefix + "=‘" + namespaces[prefix] + "‘ "; } } doc.setProperty("SelectionNamespaces", ns); } var result = context.selectNodes(expression);//IE下返回一个NodeList var nodes = new Array(); for (var i = 0, len = result.length; i < len; i++) { nodes.push(result[i]); } return nodes;//确保都返回数组类型 } else { throw new Error("No XPath engine found."); } }
可能说起XSLT,大家都不知道所云为何物,先看一个简单的示例,看效果再说理论。
demo中用的的employees.xml文件代码如下:
<?xml version="1.0"?> <employees> <employee title="Software Engineer"> <name>Nicholas C. Zakas</name> </employee> <employee title="Salesperson"> <name>Jim Smith</name> </employee> </employees>
demo中用的的employees.xslt文件代码如下:
<?xml version="1.0"?> <xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform"> <xsl:output method="html" /> <xsl:template match="/"> <ul> <xsl:apply-templates select="*" /> </ul> </xsl:template> <xsl:template match="employee"> <li> <xsl:value-of select="name" />, <em> <xsl:value-of select="@title" /> </em> </li> </xsl:template> </xsl:stylesheet>
示例demo的js文件如下所示:
window.onload = function () { var xmldom = createDocument(); var xsltdom = createDocument(); xmldom.async = false; xsltdom.async = false; xmldom.load("employees.xml");//加载一个xml的DOM文档 xsltdom.load("employees.xslt");//加载一个XSLT样式表的DOM文档 var result = xmldom.documentElement.transformNode(xsltdom);//result 保存一个转换之后得去的字符串 var div = document.getElementById("divResult"); div.innerHTML = result; }
页面中看到的效果如下图所示:
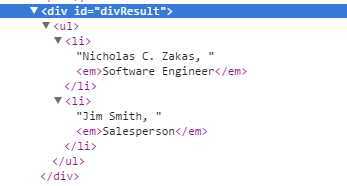
再来看一个复杂一点儿的例子:
所用到的employees2.xslt文件如下所示:
<?xml version="1.0"?> <xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform"> <xsl:output method="html" /> <xsl:param name="message" /> <xsl:template match="/"> <ul> <xsl:apply-templates select="*" /> </ul> <p>Message: <xsl:value-of select="$message" /></p> </xsl:template> <xsl:template match="employee"> <li><xsl:value-of select="name" />, <em><xsl:value-of select="@title" /></em></li> </xsl:template> </xsl:stylesheet>
页面js文件如下所示:
/* *@desc:创建线程安全的XML文档 */ function createThreadSafeDocument() { if (typeof arguments.callee.activeXString != "string") { var versions = ["MSXML2.FreeThreadedDOMDocument.6.0", "MSXML2.FreeThreadedDOMDocument.3.0", "MSXML2.FreeThreadedDOMDocument"]; for (var i = 0, len = versions.length; i < len; i++) { try { var xmldom = new ActiveXObject(versions[i]); arguments.callee.activeXString = versions[i]; return xmldom; } catch (ex) { //skip } } } return new ActiveXObject(arguments.callee.activeXString); } /* *@desc:创建XSLT模板 */ function createXSLTemplate() { if (typeof arguments.callee.activeXString != "string") { var versions = ["MSXML2.XSLTemplate.6.0", "MSXML2.XSLTemplate.3.0", "MSXML2.XSLTemplate"], i, len; for (i = 0, len = versions.length; i < len; i++) { try { var template = new ActiveXObject(versions[i]); arguments.callee.activeXString = versions[i]; return template } catch (ex) { //skip } } } return new ActiveXObject(arguments.callee.activeXString); } window.onload = function () { var xmldom = createDocument(); var xsltdom = createThreadSafeDocument(); xmldom.async = false; xsltdom.async = false; xmldom.load("employees.xml"); xsltdom.load("employees2.xslt"); var template = createXSLTemplate(); template.stylesheet = xsltdom; var processor = template.createProcessor(); processor.input = xmldom;//必须将要转换的节点指定给input属性 processor.addParameter("message", "Hello World!"); processor.transform();//调用transform方法即可执行转换并将结果作为字符串保存在output属性中 var div = document.getElementById("divResult"); div.innerHTML = processor.output; }
IE页面显示的结果如下图所示:

window.onload = function () { //use XHR to load //加载两个文件 一个是基于xml 一个是基于xslt var xmlhttp = new XMLHttpRequest(); xmlhttp.open("get", "employees.xml", false); xmlhttp.send(null); var xmldom = xmlhttp.responseXML; xmlhttp = new XMLHttpRequest(); xmlhttp.open("get", "employees.xslt", false); xmlhttp.send(null); var xsltdom = xmlhttp.responseXML; //创建一个XSLTProcessor对象 var processor = new XSLTProcessor(); processor.importStylesheet(xsltdom);//使用importStylesheet指定XSLT //执行转换 var result = processor.transformToDocument(xmldom); //如果想返回一个完整的DOM对象 //var fragment = processor.transformToFragment(xmldom, document);//如果想得到一个文档片段对象 //transformToFragment方法接受的参数 要转换的XML DOM var div = document.getElementById("divResult"); var xml = (new XMLSerializer()).serializeToString(result); alert(xml); div.innerHTML = xml; }
/* *@desc跨浏览器使用xslt的转换 *param--context:要执行转换的上下文节点 *param--xslt:xslt文档对象 */ function transform(context, xslt){ if (typeof XSLTProcessor != "undefined") {//code for Mozilla, Firefox, Opera, etc. var processor = new XSLTProcessor(); processor.importStylesheet(xslt); var result = processor.transformToDocument(context); return (new XMLSerializer()).serializeToString(result);//将返回的结果序列化为字符串 } else if (typeof context.transformNode != "undefined") {//code for IE return context.transformNode(xslt); } else { throw new Error("No XSLT processor available."); } }
页面的js文件如下:
window.onload = function () { //use XHR to load var xmlhttp = new XMLHttpRequest(); xmlhttp.open("get", "employees.xml", false); xmlhttp.send(null); var xmldom = xmlhttp.responseXML; xmlhttp = new XMLHttpRequest(); xmlhttp.open("get", "employees.xslt", false); xmlhttp.send(null); var xsltdom = xmlhttp.responseXML; var result = transform(xmldom, xsltdom); document.getElementById(‘divResult‘).innerHTML = result; }
页面的HTML结构图如下所示:
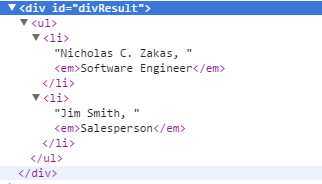
忽然发现这个太难理解了,不过挺实用的。
标签:
原文地址:http://www.cnblogs.com/elegance/p/4220707.html