标签:
本文主要介绍如何使用微软TTS语音引擎实现文本朗读,以及生成wav格式的声音文件。
1.语音引擎及语音库的安装
TTS(Text-To-Speech)是指文本语音的简称,即通过TTS引擎把文本转化为语音输出。
微软TTS语音引擎提供了Windows Speech SDK开发包供编程者使用。Windows Speech SDK包含语音合成SS引擎和语音识别SR引擎两种,语音合成引擎用于将文字转换成语音输出,语音识别引擎用于识别语音命令。
Windows Speech SDK可以在微软的官网上免费下载,下载地址为:http://www.microsoft.com/download/en/details.aspx?id=10121
在该下载界面中,选择下载SpeechSDK51.exe、SpeechSDK51LangPach.exe和sapi.chm 即可。其中,SpeechSDK51.exe是简体中文语音引擎,SpeechSDK51LangPach.exe是中文男生语音库,sapi.chm是SAPI(The Microsoft Speech API)帮助文档。
下载完成后,先安装语音引擎SpeechSDK51.exe,再安装中文语音库SpeechSDK51LangPach.exe。安装完成后,可以依次点击【开始】/【控制面板】/【语言】打开图1所示的语言属性对话框。在该对话框的“文字-语音转换”标签页下的“语音选择”中能够看到当前系统安装的全部可用的语音库。
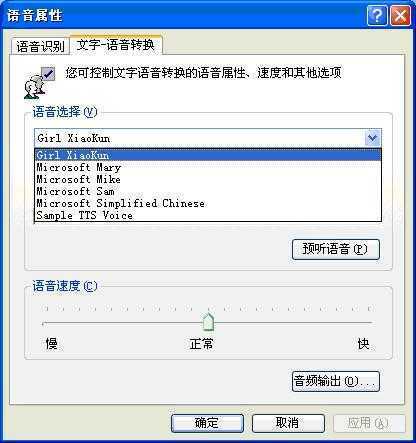
图1 语言属性对话框
2.ISpVoice接口的成员函数
文本朗读的功能主要是通过使用ISpVoice接口的成员函数来实现的。该接口的常用成员函数有如下一些:
(1)HRESULT Speak(LPCWSTR *pwcs, DWORD dwFlags, ULONG *pulStreamNumber); //朗读文本
(2)HRESULT Pause ( void); //暂停朗读
(3)HRESULT Resume ( void); //恢复朗读
(4)HRESULT SetRate( long RateAdjust); //设置朗读速度(取值范围:-10到10)
(5)HRESULT GetRate(long *pRateAdjust); //获取朗读速度
(6)HRESULT SetVoice(ISpObjectToken *pToken); //设置使用的语音库
(7)HRESULT GetVoice(ISpObjectToken** ppToken); //获取语音库
(8)HRESULT SetVolume(USHORT usVolume); //设置音量(取值范围:0到100)
(9)HRESULT GetVolume(USHORT *pusVolume); //获取音量
(10)HRESULT SetOutput(IUnknown *pUnkOutput,BOOL fAllowFormatChanges); //设置输出
(11)HRESULT SpeakStream(IStream *pStream, DWORD dwFlags, ULONG *pulStreamNumber); //朗读wav数据流
3.编程实例
了解了以上一些ISpVoice接口的成员函数之后,我们就可以开始编写程序来实现文本朗读,以及生成wav格式声音文件的功能了。
3.1环境配置
首先,我们需要将Windows Speech SDK开发包的头文件和库文件所在路径添加到编译器中,具体方法如下(这里以VC++6.0为例):
依次点击【工具】/【选项】,打开选项对话框,选择【目录】标签,在【路径】中加入“C:\Program Files\Microsoft Speech SDK 5.1\Include”和“C:\Program Files\Microsoft Speech SDK 5.1\Lib\i386”。如图2所示。
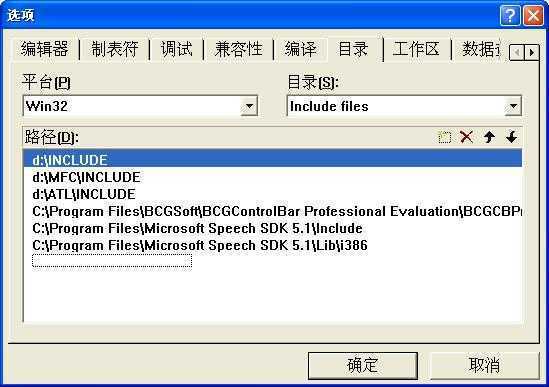
图2 选项对话框
其次,还需要在工程中包含TTS语音引擎头文件和库文件,具体如下:
1 #include <sapi.h> //包含TTS语音引擎头文件和库文件 2 #include <sphelper.h> 3 #pragma comment(lib, "sapi.lib")
3.2枚举语音库
枚举语音库需要使用到SpEnumTokens()函数,该函数原型如下:
1 inline HRESULT SpEnumTokens( 2 const WCHAR *pszCategoryId, 3 const WCHAR *pszReqAttribs, 4 const WCHAR *pszOptAttribs, 5 IEnumSpObjectTokens **ppEnum 6 );
其中,参数ppEnum是IEnumSpObjectTokens类型的指针,用于存储枚举得到的所有语音Token。IEnumSpObjectTokens的成员函数GetCount()用于得到语音Token的总个数,而成员函数Item()则用于得到具体的某一个语音Token。
如下的代码示例如何枚举得到的所有语音Token,并将得到的语音库的名字添加到下拉组合框控件中,具体实现如下:
1 /* 2 * 函数功能 : 初始化语言包选择组合框控件 3 * 备 注 : 4 * 作 者 : 博客园 依旧淡然 5 */ 6 void CTTSDemoDlg::InitVoicePackageSelComboxCtrl() 7 { 8 //初始化COM组件 9 if(FAILED(::CoInitialize(NULL))) 10 { 11 MessageBox("初始化COM组件失败!", "提示", MB_OK|MB_ICONWARNING); 12 return; 13 } 14 15 //枚举所有语音Token 16 if(SUCCEEDED(SpEnumTokens(SPCAT_VOICES, NULL, NULL, &m_pIEnumSpObjectTokens))) 17 { 18 //得到所有语音Token的个数 19 ULONG ulTokensNumber = 0; 20 m_pIEnumSpObjectTokens->GetCount(&ulTokensNumber); 21 22 //检测该机器是否安装有语音包 23 if(ulTokensNumber == 0) 24 { 25 MessageBox("该机器没有安装语音包!", "提示", MB_OK|MB_ICONWARNING); 26 return; 27 } 28 29 //将语音包的名字加入组合框控件 30 CString strVoicePackageName = _T(""); 31 CString strTokenPrefixText = _T("HKEY_LOCAL_MACHINE\\SOFTWARE\\Microsoft\\Speech\\Voices\\Tokens\\"); 32 for(ULONG i=0; i<ulTokensNumber; i++) 33 { 34 m_pIEnumSpObjectTokens->Item(i, &m_pISpObjectToken); 35 WCHAR* pChar; 36 m_pISpObjectToken->GetId(&pChar); 37 strVoicePackageName = pChar; 38 strVoicePackageName.Delete(0, strTokenPrefixText.GetLength()); 39 m_ComboxVoiceSel.InsertString(i, strVoicePackageName); 40 } 41 42 //设置默认的语音包选择 43 m_ComboxVoiceSel.SetCurSel(0); 44 } 45 }
通过以上的代码可以看到,首先,我们通过调用CoInitialize()函数完成了对COM组件的初始化。然后,我们调用SpEnumTokens()函数得到了m_pIEnumSpObjectTokens对象,该对象存储了枚举得到的所有语音Token。紧接着,我们调用GetCount()函数得到个数,并调用Item()函数得到具体的每一个语音Token对象m_pISpObjectToken。最后,我们通过调用m_pISpObjectToken对象的GetId()函数便能得到具体的某一个Token对象的ID,其形式为“HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Speech\Voices\Tokens\XXXXX”,去掉其前缀便能得到具体的语音库的名字了。
该实例运行效果如图3所示,点击“语音包选择”组合框下拉箭头,能够看到与图1中列出的语音包是一致的。
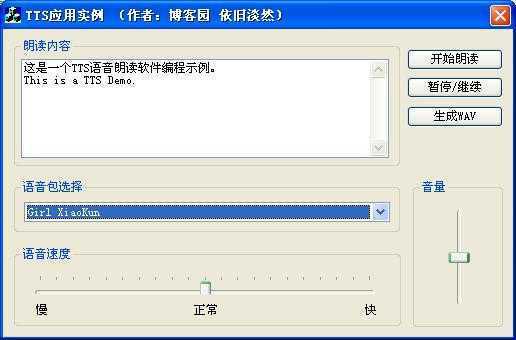
图3 TTS示例运行效果
3.3文本朗读
点击图3所示界面中的“开始朗读”按钮,能够根据当前所选择的语音包以及设定的语速和音量,对朗读内容编辑框中的内容进行朗读。其具体实现方法如下:
1 /* 2 * 函数功能 : 点击"开始朗读"按钮时,该函数被调用 3 * 备 注 : 4 * 作 者 : 博客园 依旧淡然 5 */ 6 void CTTSDemoDlg::OnButtonStartRead() 7 { 8 UpdateData(true); 9 10 //获取ISpVoice接口 11 if(FAILED(CoCreateInstance(CLSID_SpVoice, NULL, CLSCTX_INPROC_SERVER, IID_ISpVoice, (void**)&m_pISpVoice))) 12 { 13 MessageBox("获取ISpVoice接口失败!", "提示", MB_OK|MB_ICONWARNING); 14 return; 15 } 16 17 //设置语言 18 m_pIEnumSpObjectTokens->Item(m_ComboxVoiceSel.GetCurSel(), &m_pISpObjectToken); 19 m_pISpVoice->SetVoice(m_pISpObjectToken); 20 21 //设置播放速度 22 m_pISpVoice->SetRate(m_SliderVoiceSpeed.GetPos() - 10); 23 24 //设置音量大小 25 m_pISpVoice->SetVolume(100 - m_SliderVoiceSize.GetPos()); 26 27 //检测朗读内容是否为空 28 if(m_EditContent.IsEmpty()) 29 { 30 MessageBox("朗读内容不能为空!", "提示", MB_OK|MB_ICONWARNING); 31 return; 32 } 33 34 //开始进行朗读 35 m_pISpVoice->Speak(m_EditContent.AllocSysString(), SPF_ASYNC, NULL); 36 }
在以上代码中可以看到,使用了ISpVoice接口函数来完成语音库的选择、语速和音量大小的设定,以及通过调用Speak()函数进行文本朗读。
3.4生成WAV格式的声音文件
要将文本朗读的声音保存为WAV格式的声音文件,主要是通过调用ISpVoice接口函数GetOutputStream()和SetOutput()来实现的。
以下的代码段给出了实现该功能的示例:
1 //生成WAV文件 2 CComPtr<ISpStream> cpISpStream; 3 CComPtr<ISpStreamFormat> cpISpStreamFormat; 4 CSpStreamFormat spStreamFormat; 5 m_pISpVoice->GetOutputStream(&cpISpStreamFormat); 6 spStreamFormat.AssignFormat(cpISpStreamFormat); 7 HRESULT hResult = SPBindToFile("C:\\Documents and Settings\\Administrator\\桌面\\TEST\\test.wav", 8 SPFM_CREATE_ALWAYS, 9 &cpISpStream, 10 &spStreamFormat.FormatId(), 11 spStreamFormat.WaveFormatExPtr()); 12 if(SUCCEEDED(hResult)) 13 { 14 m_pISpVoice->SetOutput(cpISpStream, TRUE); 15 m_pISpVoice->Speak(m_EditContent.AllocSysString(), SPF_DEFAULT, NULL); 16 MessageBox("生成WAV文件成功!", "提示", MB_OK); 17 } 18 else 19 { 20 MessageBox("生成WAV文件失败!", "提示", MB_OK|MB_ICONWARNING); 21 }
【VC++技术杂谈004】使用微软TTS语音引擎实现文本朗读
标签:
原文地址:http://www.cnblogs.com/menlsh/p/4222408.html