标签:
---恢复内容开始---

如列表,元组或者字典都是容器
属性,对象被实例化时,对象内部被赋有的值称之为对象的属性-->给对象内部变量所赋的值,那么这个对象内部变量的名称就叫属性
两个对象的比较
1值比较,对象中的数据是否相同
2身份比较:两个变量所引用的对象是否相同
3类型比较: 所属的类是否相同
核心数据类型
数字 int.long.float.complex ,bool
字符 str,unicode
列表 list
字典 dict
元祖 tuple
文件 file
其他类型 集合(set)frozenset。类类型,NONe
其他文件类工具 pipes,fifos,sockers
如果我们期望在类型之中转换
str(),repr(),或format();
这三个内置函数,可以将非字符数据转换为字符
这三个有什么区别?
str与print结果相同
我目前猜测repre有整理的功能(比如里面可以接类),而str只能针对某个具体的值
也有说repr是针对编译器,而str是针对人
format(age)
同样还有int float等将其转换为整数
list()将字串转换成列表
把字串中每一个字符当做一个元素
tuple(s)将字串转换成元祖
set将 set(s)
集合可以去掉字符串中的重复元素,并进行排序

将字串s转换为不可变集合
frozenset(s)
chr(num)
c1 = chr()
ord(x)将字符转换为整数值
hex(x)将帧数转换为16进制字串
oct(x) 10
bin(x) 2
数字类型(为不可变类型)
Python的数字字面量,布尔型,整数,浮点数,复数:
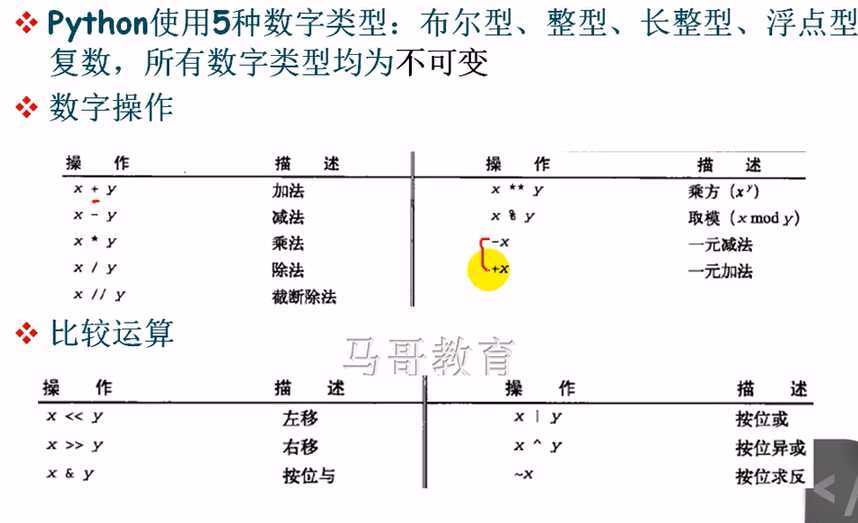
其中次方是**
比如1 **3 是1的三次方
序列类型
如下

all检查字串的每一位是否为true
index (‘需要寻找的字符串’,start位置,end位置)

maxreplace 替换几次
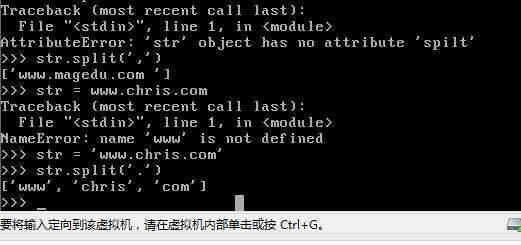
将字符串划分成序列
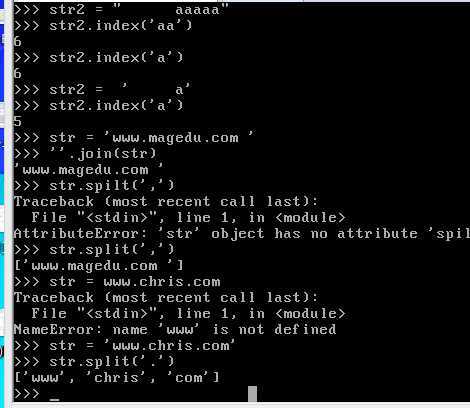
如果要使用Unicode编码,则在字符之前用字符u进行标示
文档字串: 模块类或函数的第一条语句是字符串的话可以
printname._doc_ 有括号标示调用函数,没有标示引用函数的类,()标示调用运算符
文本与代码段的缩进程度必须一样

切片运算,切片后的结果会生成新的对象
在使用切片时,负数有什么用
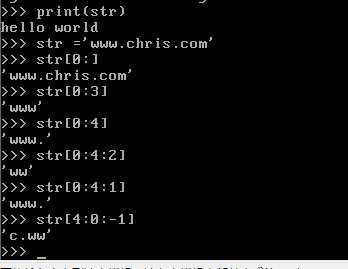
以上,便于理解切片
既然如此我们在索引中使用负数也不足为奇了
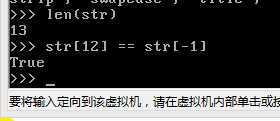
正索引与负索引的绝对值之和为字段长度
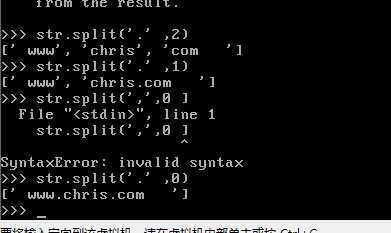
split后面跟的数字似乎为展开为序列后元素的个数
列表类型的方法
容器类型
任意对象的有序集合,通过索引访问其中的对象,可变对象
异构,可以嵌套
因为是可变对象
所以指出原处修改
列表如何修改
比如说列表如下 l2 = [ 1,32,3,‘xyz‘,5]
l2[1:3] = [32,3]
若 l2[1:3] = []
则l2 [1,‘xyz‘,5]
这与l2.del(l2[1:3])相同
append追加类似于队列
它甚至可以追加列表
count统计指定值所出现的个数
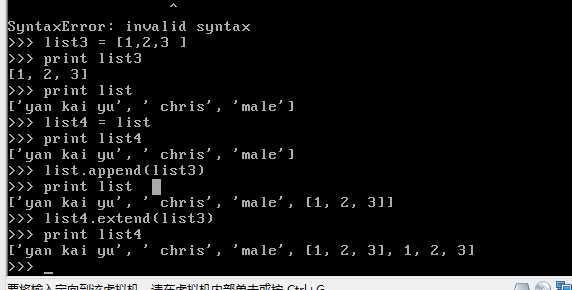
append 与 extend的异同
这里可能会引起歧义,注意到list4的结果是基于list之后的 他们引用的是同一块对象内存
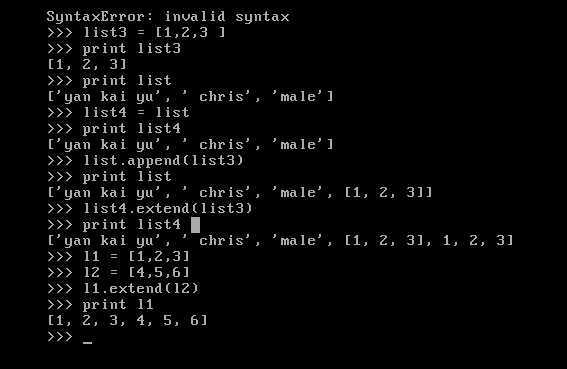
如下,此为pop与index的含义
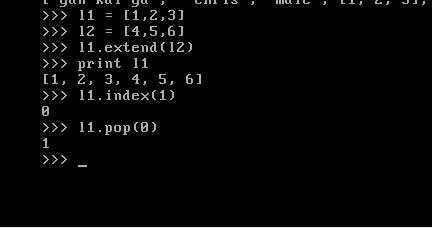
同时,我们需要注意到pop弹出之后,原有序列会少一个
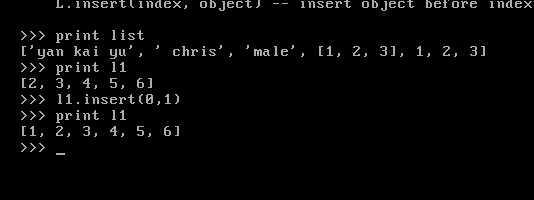
如此便是index的意思在指定索引的前面插入值
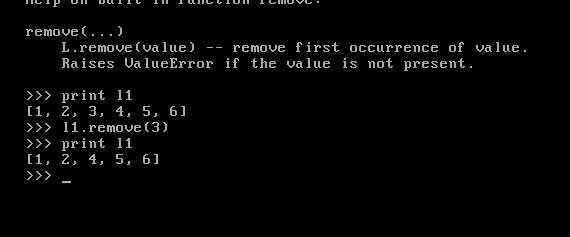
此为remove的用法(但是我们需要注意到我们只能删除掉列表中的第一个3
reverse()直接倒过来
以下,为sort()reverse()的作用
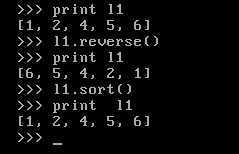
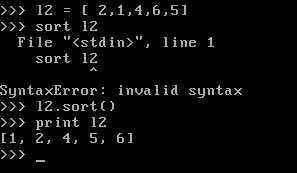
reverse()或者sort()在原处修改,不返回任何结果
l1+l2返回一个新的列表 不会修改原来的列表的内容
同理 str+str
或者str *3
你也懂得!
in 容器返回布尔值
自然也有mot in
用法obj in container
或者obj not in conrainer
列表切片级别的修改效果与extend相同都会修改元素
range 可以生成一个列表
可以类似于bashshell一样实现类似于循环一样的遍历
如何复制一个列表但是与其指的同一个内存对象呢?
l1 = l2[:】
或者引入copy模块
l2 = copy.deepcopy(l1)
否则 l2 = l1只是浅copy
元组
()
任意对象的有序集合,通过索引访问其中的元素,不可变对象,长度固定
因此
.index
sort()
同样也可以进行分片操作
元组中最后一个元素的逗号可有可无
定义元组时可以把小括号省略掉
同理相加可以返回出一个新元组
同理t3* 3
也一样 in not in 在元组中也可以 返回布尔值
如何“修改”元组?
由于元组是异构的,如果元组中包含了可变对象的元素,则可以被修改

字典dict
关联数组或者散列表
通过键实现元素存取 : 无序集合,可变类型容器,长度可变,异构,嵌套
{key1:value}
{}空字典
.clear()
清空字典
复制字典 d2=d1.copy()
get返回指定键所对应的值
不存在则为空
d1.has_key顾名思义
d1.items()将d1中的所有键与值以二元组的形式展现为列表
若d1.items() 得出的结果是一个拥有两个元素的列表
那么元素解包a1,a2 = d1.items()
则a1 为以上列表的第一个元素a2为第二个依次类推
如此叫做解包,否则会抛出异常
而字典解包保存的不是 ‘key‘:value而是‘key‘并且还不是左右一一对应的
keys()返回为键列表
values()返回值列表
pop()函数选择一个键,弹出该键与其值
popitem()随机弹出去一个
update()合并,类似于列表的extend
更新如果有冲突则会覆盖原有键
i1 = d1.iteritems()
返回迭代器对象 i1就是一个迭代器
i1.next()遍历对象中的每一个元素
i2 = d1.keyitems()
d2=dict(name=‘jerry‘,age=22,gender=‘m‘)
字典的键必须是可哈希的 不能是字典等
类:数据+方法
其中,数据是类在初始化对象(实例化)的时候形成的
函数名是指向内存中的一段函数体的对象
调用-->执行函数对象或者方法对象的一段代码
每一个类都有一个内置的对象名
貌似字典所得到的顺序是反的
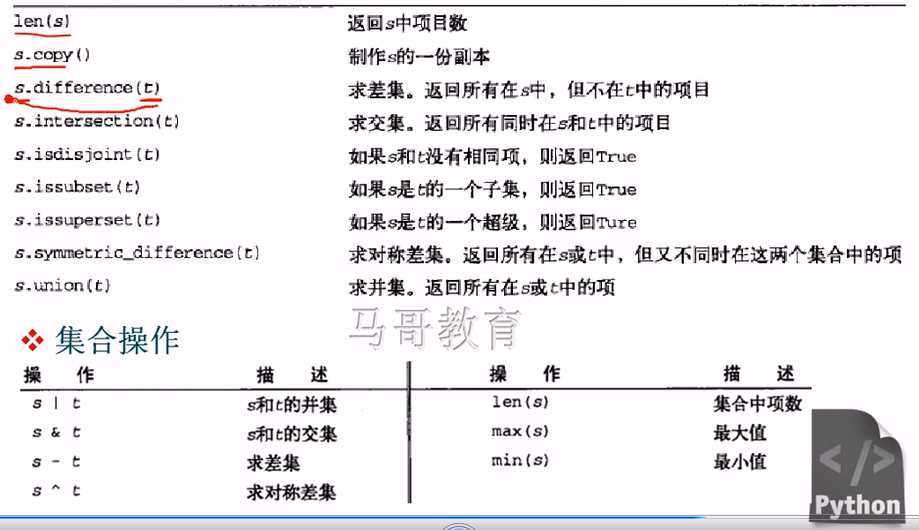
集合:一组无序排列的可哈希的值
集合关系测试:
成员关系测试 in not in
迭代
不支持 索引,元素获取,切片
集合的类型: set () , frozenset()
没有特定语法 只能通过工厂函数创建
s1 = set([1,2,3])
其内部必须要是可迭代对象
每个对象都有引用计数,修改引用名,或者放到某个容器中去都会更改引用计数
import sys
sys.getrefcount(a)获得引用计数
del一个对对象的引用,会减少对对象的引用
深复制可以使用copy中的deepcopy来进行
python中的所有对象都是”第一类“
这意味着使用标示符命名的所有对象都具有相同状态,于是,能够命名的所有对象都可以直接当数据进行处理

可变序列的操作
s1[index]=value
s1[i:j=value
del s1[i:j]
表达式和语句
Python中的常用的表达式操作符
+ — * / %
逻辑运算
x or y x and y not x
成员关系运算
x in y x not in y
对象实例测试
x is y
比较运算
x < y x > y x<=y
位运算
x | y ,x&y ,x^y
一元运算
-x +x ~x(按位取反)
幂运算 x**Y
索引和分片
调用
取属性.运算
python 三元选择表达式
x if y else z
相当于 if y
then x
else z
匿名函数 lambada args:expression
运算优先级

python中的语句
赋值语句
调用
print 打印对象
if/elif/else 条件判断
for/else 序列迭代
while/else普通循环
pass :占位符
break:
continue
def
return
yield
global 命名空间
raise触发异常
import
from模块属性访问
try except /finaly
del
assert 调试检查
with/as环境管理器
赋值语句 import,from.def
class
def
for
元组和列表分解赋值 此时等于号的左边实际上是一个元组
增强赋值 : +=, *=, 、/=

不同类型比较 ==的结果直接就是False
即使一样比如 x = 3
y = 3 虽然都是3 但是还可能不是同一个对象
非0与非空为假 空为假
比较相等测试会递归的应用于数据结构中
组合条件测试
x and y
x or y
if测试的语法结构
格式化
循环机制及应用场景 

while 循环中
如果不想让x换行显示,那么我们添加一个逗号
break 跳出最内层的循环
continue 结束本次循环

---恢复内容结束---
标签:
原文地址:http://www.cnblogs.com/clearlove/p/4230431.html