标签:
上一篇简单描述了一下SequoiaDB的简单CRUD操作,本篇将讲述一下稍微高级点的功能。
部署在我机器上的集群环境,在经过创建名字为"foo"的cs,创建名字为"bar"的cl,以及插入一些数据之后,并没有删除掉,因此在本篇中会继续使用。
首先,我们先看看,在SequoiaDB的安装目录中的database目录里面,有那些文件:
~$ ls /opt/sequoiadb/database/data/11850
我们会发现有几个文件:foo.1.idx,foo.1.data
正好是我们创建的cs的名字。是不是巧合呢?
验证一下,依次做以下操作:
以上我不再写出操作,读者可以自己操作一下,有利于熟悉常用操作。
先删除Collection Space,执行:
> db.dropCS("foo")
然后在终端2下,查看一下文件:
~$ ls /opt/sequoiadb/database/data/11850
这个时候,我们发现foo.1.data和foo.1.idx文件没有了。
再回到终端1,重新创建名为“foo”的cs:db.createCS("foo")
切换到终端2,再次查看文件:
~$ ls /opt/sequoiadb/database/data/11850
这个时候,foo.1.data 和 foo.1.idx文件又有了。
因此,我们基本可以确定,一个cs对应一个.data文件和一个.idx文件;cl是data文件下的逻辑概念,相当于是关系数据库中的table。故在操作文件的时候,请谨慎,不是不得已,不要动这些*.data, *.idx 文件
上面算是一点积累,准备进入本篇的正题:
因为上面的操作删除掉了cs,然后重新创建了名为"foo"的cs(虽然名字一样,但是删除过一次,里面的内容已经没有了)。所以再次创建名为"bar"的cl。
再切换到终端1,创建cl:
> db.foo.createCL("bar")
先构造一些数据:
> docs = [
... {"name":"Milky", "age":24},
... {"name":"Jim", "age":23, "ip":"192.168.1.131"},
... {"name":"Tyle", "age":24, "phone":"10086"},
... {"name":"Tony","age":33 } ]
插入数据:
> db.foo.bar.insert( docs )
一、创建索引
有时候数据很多,但是想尽快查询到特定的数据,这个时候,就需要用到索引了。
在简历索引之前,先查询一下数据,并查看一下数据是通过普通扫描查询到的,还是通过索引扫描查询到的:
> db.foo.bar.find({"age": 24}).explain()
结果是:
{
"Name": "foo.bar",
"ScanType": "tbscan",
"IndexName": "",
"UseExtSort": false,
"NodeName": "Milky:11860",
"ReturnNum": 0,
"ElapsedTime": 0.000003,
"IndexRead": 0,
"DataRead": 0,
"UserCPU": 0,
"SysCPU": 0
}
然后创建一个索引:
> db.foo.bar.createIndex("ageIndex", {"age":1})
然后我们再执行:
> db.foo.bar.find({"age": 24}).explain()
结果是:
{
"Name": "foo.bar",
"ScanType": "ixscan",
"IndexName": "ageIndex",
"UseExtSort": false,
"NodeName": "Milky:11860",
"ReturnNum": 0,
"ElapsedTime": 0.000003,
"IndexRead": 0,
"DataRead": 0,
"UserCPU": 0,
"SysCPU": 0
}
由于数据量太小,查询耗时对比都不太明显。但是在两次对比结果的“ScanType”字段的值中能看出一个走的tbscan,一个走的ixscan。如果有时间,可以试着插入万条级别的数据,再次试试,耗时的对比会比较明显。
二、删除索引
这个就比较简单了。稍微演示一下:知道要删除的索引的名字是“ageIndex”,调用接口:
> db.foo.bar.dropIndex("ageIndex")
再执行:
> db.foo.bar.find({"age": 24}).explain()
结果是:
{
"Name": "foo.bar",
"ScanType": "tbscan",
"IndexName": "",
"UseExtSort": false,
"NodeName": "Milky:11860",
"ReturnNum": 0,
"ElapsedTime": 0.000003,
"IndexRead": 0,
"DataRead": 0,
"UserCPU": 0,
"SysCPU": 0
}
此时的ScanType字段的值变成了“tbscan”,说明这次的查询,没有走索引:索引删除成功。
一个好的索引,对dba来说,是一项牛逼的技能。关于如何创建一个高效的索引,已经超出本篇的范围,在此不做描述,请自行google学习。
三、记录条数计数
这个操作也是一个很简单明了的操作。
在以上操作的基础上,执行:
> db.foo.bar.count()
返回:
4
说明这个时候,cl中有四条数据(cl中的确是4条数据)。
四、聚集
在SQL中,聚集是一个简单的语法。而在没有SQL语句的NoSQL中,就是aggregate来大显神威了。
由于这块内容涉及到大量的匹配符等,我采用SequoiaDB官网给出的例子来演示:
先构造数据:
> tom = {
... "no":1000,
... "score":80,
... "interest":["basketball", "football"],
... "major":"计算机科学与技术",
... "dep":"计算机学院",
... "info":{
... "name":"Tom",
... "age":25,
... "gender":"男"
... }
... }
> sam = {
... "no":1000,
... "score":80,
... "interest":["music"],
... "major":"软件工程",
... "dep":"计算机学院",
... "info":{
... "name":"Sam",
... "age":22,
... "gender":"男"
... }
... }
> db.foo.bar.insert(tom)
> db.foo.bar.insert(sam)
然后执行:
> db.foo.bar.aggregate({"$match":{"no":1000}}, {"$group":{"_id":"$major", "Major":{"$first":"$major"}, "avg_age":{"$avg":"$info.age"}}})
输出结果:
{
"Major": "软件工程",
"avg_age": 22
}
{
"Major": "计算机科学与技术",
"avg_age": 25
}
详细请参考SequoiaDB官网信息中心>>参考手册>>SequoiaDB Javascript方法>>SdbCollection>>db.collectionspace.collection.aggregate。
PS:有朋友私下问我,官网点进去,很难找到对应的位置。因为SequoiaDB官网的文档无法定位到确切的位置,所以只能索引到信息中心位置。很多需要慢慢看,如果熟悉一些数据库常用术语的话,定位会快一点。可以去SequoiaDB的社区吐槽哈,他们的社区地址是:SequoiaDB社区。
五、切分
对于每一条,有热数据与冷数据的区分。对于热数据,需要频繁访问;对于冷数据,可能访问的几率会比较小。因此,热数据所在的磁盘性能可能会更好一点。如果把冷数据和热数据都存放在性能好的磁盘上,会占据磁盘空间,由于不常访问,浪费了资源。因此热数据和冷数据通常要分开存放。
这就是数据切分的由来了。
SequoiaDB的数据切分需要用到两个数据组,把冷的数据,切分到另外一个组上。
回顾第一篇部署集群环境的时候,已经就创建了一个数据组。在此,还需要创建另外一个组,组名叫“colddatagroup”。
部署步骤,请参考 SequoiaDB系列之一:SequoiaDB的安装、部署。
先附切分原理图一张:
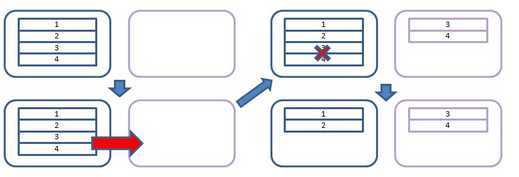
现在,要创建一个新的名为"total"的cs,并在这个cs上创建一个名为"age"的cl,这个cl的分区键类型是"age",分区类型是"range"的:
> db.createCS("total")
localhost:11810.total
Takes 0.193840s.
> db.total.createCL("age", {"ShardingKey":{"age":1}, "ShardingType":"range"})
localhost:11810.total.hot
Takes 3.288509s.
往这个cl中插入几条"age"的值不同的数据:
> docs = [
... {"age":20},
... {"age":21},
... {"age":22},
... {"age":23},
... {"age":50},
... {"age":60},
... {"age":62},
... {"age":68},
... {"age":79},
... {"age":85},
... {"age":90} ]
[object Object],[object Object],[object Object],[object Object],[object Object],[object Object],[object Object],[object Object],[object Object],[object Object],[object Object]
Takes 0.42086s.
插入数据:
> db.total.age.insert(docs) Takes 0.2119s.
然后定义一个规则,65岁之后的人,咱不管了,当冷数据处理。要把 age值 大于或等于65的,切分到colddatagroup组上。输入:
> db.total.age.split("datagroup", "colddatagroup", {"age":65}, {"age":100})
数据量很大的时候,这个操作耗时会有点长,耐心等待即可。
等待操作完成,我们需要检验一下是否真的切分了。
重新建立一个连接,这个连接比较特殊,因为这个连接是直接连接到某个数据节点上(还记得上一篇有一处提到的吗?生产环境下,不建议有这样操作)。
> node = new Sdb("Milky", 18800)
这个节点是colddatagroup数据组上的节点,也是我们切分之后,存放age大于或等于65的数据的数据组中的数据节点。
查看一下这个节点上有哪些cl:
> node.listCollections()
结果显示的cl,名字整好是datagroup数据组上,用于切分的源数据组的collection的名字。
查询一下:
> node.total.age.find()
结果输出:
{
"_id": {
"$oid": "54ba9abe74b1303560000044"
},
"age": 68
}
{
"_id": {
"$oid": "54ba9abe74b1303560000045"
},
"age": 79
}
{
"_id": {
"$oid": "54ba9ca374b1303560000048"
},
"age": 80
}
{
"_id": {
"$oid": "54ba9abe74b1303560000046"
},
"age": 85
}
{
"_id": {
"$oid": "54ba9abe74b1303560000047"
},
"age": 90
}
这些数据正是age字段的值,大于或者65的记录。
如果还有疑问,可以再次直接连接到datagroup的数据组中的节点上,查询源数据组中的记录,检查是否其中的数据,age字段的值是否小于65。
至此,本篇也到了末尾结束部分,感谢您的耐心阅读!
下一篇,将进入本系列的重点部分,简析SequoiaDB的架构。敬请期待!
=====>THE END<=====
SequoiaDB 系列之三 :SequoiaDB的高级功能
标签:
原文地址:http://www.cnblogs.com/tynia/p/sequoiadb03.html