标签:
网络内容总结(感谢原创)
1、前言简介
? CPU
? 内存
? 磁盘I/O带宽
? 网络I/O带宽
子系统之间相互依存,任何一个子系统的负载过度都能导致其他子系统出现问题,例如:
* 大量的 page-in IO 请求可能导致内存队列被塞满
* 网卡的巨量吞吐可能导致 CPU 资源耗尽
* 系统尝试保持释放内存队列时可能耗尽 CPU 资源
* 来自内存的大量磁盘写入请求可能导致 CPU 资源和 IO 通道耗尽
性能调优的前提是找出系统瓶颈之所在, 尽管问题看似由某个子系统所导致, 然而这很可能是另外一个子系统的过载所引起的。
2. 程序应用级
为了明白从何处开始着手调整性能瓶颈, 弄清被分析系统的性能表现是首要任务。 任何系统的应用常可分为以下两类:
1) IO 限制型——一个 IO 限制型的应用需要大量的内存和基础存储设备占用。 因其需要大量的数据读写请求,此类应用对 CPU 和网络需求不高(除非存储系统在网络上) 。
IO 限制型应用使用 CPU 资源来进行 IO 操作且常进入睡眠状态。 数据库应用常被认为属于此类。
2)CPU 限制型——一个 CPU 限制型应用需要大量的 CPU 资源,来进行批量的处理或大量的计算。大容量 web 服务,mail 服务,以及任何类型的渲染服务都被归到此类。
判断一个系统是否有性能问题的唯一途径是弄清楚对系统的期望是神马, 需求的性能是神马, 应该得到的数据是神马?而为了建立这些信息的唯一途径是为系统建立一个基准。 在性能可接受的状态下必须为系统建立统计信息,这样就可以在性能不可接受时进行对比。
|
影响性能因素 |
评判标准 |
||
|
好 |
坏 |
糟糕 |
|
|
CPU |
user% + sys%< 70% |
user% + sys%= 85% |
user% + sys% >=90% |
|
内存 |
Swap In(si)=0 Swap Out(so)=0 |
Per CPU with 10 page/s |
More Swap In & Swap Out |
|
磁盘 |
iowait % < 20% |
iowait % =35% |
iowait % >= 50% |
其中:
%user:表示CPU处在用户模式下的时间百分比。
%sys:表示CPU处在系统模式下的时间百分比。
%iowait:表示CPU等待输入输出完成时间的百分比。
swap in:即si,表示虚拟内存的页导入,即从SWAP DISK交换到RAM
swap out:即so,表示虚拟内存的页导出,即从RAM交换到SWAP DISK。

1.常用系统命令
Vmstat、sar、iostat、netstat、free、ps、top等
2.常用组合方式
? 用vmstat、sar、iostat检测是否是CPU瓶颈
? 用free、vmstat检测是否是内存瓶颈
? 用iostat检测是否是磁盘I/O瓶颈
? 用netstat检测是否是网络带宽瓶颈
Linux性能评估与优化:
cpu,内存,IO, 网络
2、负载:整体性能评估
系统整体性能评估(uptime命令/top)
[root@web1 ~]# uptime
16:38:00 up 118 days, 3:01, 5 users, load average: 1.22, 1.02, 0.91
这里需要注意的是:load average这个输出值,这三个值的大小一般不能大于系统CPU的个数,例如,本输出中系统有8个CPU,如果load average的三个值长期大于8时,说明CPU很繁忙,负载很高,可能会影响系统性能,但是偶尔大于8时,倒不用担心,一般不会影响系统性能。相反,如果load average的输出值小于CPU的个数,则表示CPU还有空闲的时间片,比如本例中的输出,CPU是非常空闲的。
Load:top
系统负载指运行队列的平均长度,也就是等待CPU的平均进程数。Load越高说明系统响应越慢,如果load是0,代表进程不需要等待,立刻就能获得cpu运行。可以通过查询文件/proc/loadavg获取系统在前一分钟、前五分钟和前十五分钟的平均负载以及当前运行的进程、系统的进程数和上一次调度运行的进程。
justin@junjun:/proc$ cat/proc/loadavg
0.71 0.70 0.63 1/403 5111
在linux系统中,也可直接通过命令行 “w”或者“uptime”查看,如下:
16:10:22 up 1 day, 4:18, 3 users, load average: 0.34, 0.50, 0.52
USER TTY FROM LOGIN@ IDLE JCPU PCPU WHAT
justin tty7 :0 Tue11 28:19m 10:15 0.22s gnome-session
justin pts/0 :0.0 Tue11 28:17m 2:22 0.00s /bin/bash./jettyctl.sh
justin pts/1 :0.0 16:08 0.00s 0.17s 0.00s w
cpu usage:
系统的CPU使用率。
可以用“top”命令动态的显示当前系统进程用户的使用情况。
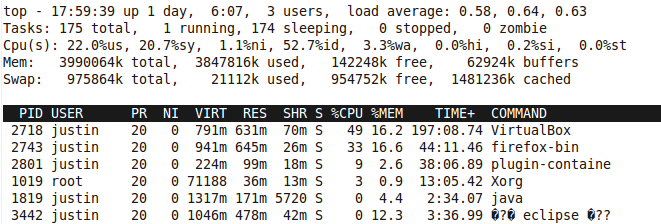
前五行是系统整体的统计信息。
第一行是任务队列信息,同 uptime 命令的执行结果。其内容如下:当前时间;系统运行时间,格式为时:分;当前登录用户数;系统负载,即任务队列的平均长度。
第二、三行为进程和CPU的信息。当有多个CPU时,这些内容可能会超过两行。
内容如下:Tasks: 175 total进程总数;1 running正在运行的进程数;174 sleeping睡眠的进程数;0 stopped停止的进程数;0 zombie僵尸进程数
Cpu(s):22.0% us用户空间占用CPU百分比
20.7%sy内核空间占用CPU百分比
1.1%ni用户进程空间内改变过优先级的进程占用CPU百分比
52.7%id空闲CPU百分比
3.3%wa等待输入输出的CPU时间百分比
0.0%hi
0.2%si swap in,表示虚拟内存的页导入,即从SWAPDISK交换到RAM
0.0%st swap out,表示虚拟内存的页导出,即从RAM交换到SWAPDISK。
PR:操作系统给进程的安排的优先级。这个值标示进程调度器分配给进程的时间片长度。单位是时钟个数。如果一个Linux系统的时间片是10ms,那么PID是2718的进程在执行了200ms后,才会进行进程切换。
RES:进程占用的物理内存大小
VIRT:物理内存+虚拟内存。
吞吐率:
服务器单位时间内处理的请求数,一般用来描述并发能力,当然谈吞吐率的前提是并发用户数。不同的并发用户数下,吞吐率自然大不相同。单位是“请求数/秒”。吞吐量分为网络吞吐量和事务吞吐量,当作为事务吞吐量时,采用TPS来衡量。目前线上环境Apache没有mod_status模块,不能很方便的查询。
TPS:
服务器每秒处理的事务数。PV在性能测试中的表现形式是以TPS来体现的,两者有一个转换公式,如下:
TPS平均值 =((PV*80%)/(24*60*60*40%))/服务器数量 = pv/s
TPS峰值 =(((PV*80%)/(24*60*60*40%))*1.6) /服务器数量= pv/s ,这个和我们经常说的“2-8原则”贴近。
一般的,评价系统性能均以每秒钟完成的技术交易的数量来衡量。系统整体处理能力取决于处理能力最低模块的TPS 。应用系统的处理能力一般要求在10-100左右。
3、CPU性能评估
CPU 利用率很大部分取决于试图访问它的资源, 内核拥有一个管理两种资源的调度器:线程(单或多)和中断。调度器给予不同资源以不同的优先级,以下由优先级从高到低:
1) 中断——设备通知内核它们处理完成。例如网卡发送一个数据包或硬盘驱动器提供一次 IO 请求
为了弄明白内核是如何管理不同的资源的,几个关键概念需要提及一下: context switches,run queues,utilization。
Context Switches(上下文切换):
大多数处理器在同一时间只能处理一个进程或线程,多线程处理器可同时处理 n 个线程。然而,linux 内核把多核处理器的各个核心当做独立核心。例如,内核把一个双核的处理当做两个独立处理器。
一个标准的内核可同时处理 50 到 50000 个进程, 在只有一颗 CPU 的情况下, 内核必须调度和平衡这些进程和线程。 每个线程在处理器上都拥有一个时间分配单元, 当一个线程超过自己的时间单元或被更高优先级的程序抢占时, 此线程及被传回队列而此时更高优先级的程序将在处理器上执行。这种线程间的切换操作即是上下文切换。
运行队列
每个 CPU 维持着一个线程的运行队列, 理论上, 调度器应该是不断地运行和执行线程。线程要么处于睡眠状态,要么处于可运行状态。假如 CPU 子系统处于高负载状态,那么内核调度器罢工是有可能的, 其结果将导致可运行状态的进程开始阻塞运行队列。 运行队列越大,执行进程所花费的时间也越长。
一个很流行的术语叫“load(负载) ”经常被用来描述运行队列的状态,系统负载是由正在执行的进程和 CPU 运行队列中的进程的结合,如果有 2 个线程正在一个双核系统中执行且4 个正在运行队列中, 那么负载数即是 6, 像 top 等工具可查看过去 1,5,15 分钟的负载均值。
CPU 利用率
CPU 利用率被定义为 CPU 使用的百分比, CPU 如何被利用是衡量一个系统的重要标准。多数性能监测工具把 CPU 利用分为以下几个类型:
* 用户时间——CPU 花在执行用户空间进程的时间百分比
* 系统时间——CPU 花在执行内核进程和中断的时间百分比
* IO 等待——CPU 花在等待 IO 请求完成的时间百分比
* IDLE——CPU 的空闲时间百分比
vmstat 工具的低开销使得它可以在一个高负载的系统上持续运行,它有两种工作模式:均值模式和采样模式。采样模式如下:
该命令可以显示关于系统各种资源之间相关性能的简要信息,这里我们主要用它来看CPU一个负载情况。
下面是vmstat命令在某个系统的输出结果:
[root@node1 ~]# vmstat 2 3
procs -----------memory---------- ---swap-- -----io---- --system-- -----cpu------
r b swpd free buff cache si so bi bo in cs us sy id wa st
0 0 0 162240 8304 67032 0 0 13 21 1007 23 0 1 98 0 0
0 0 0 162240 8304 67032 0 0 1 0 1010 20 0 1 100 0 0
0 0 0 162240 8304 67032 0 0 1 1 1009 18 0 1 99 0 0
Procs
r:运行和等待cpu时间片的进程数,这个值如果长期大于系统CPU的个数,说明CPU不足,需要增加CPU。
b:在等待资源的进程数,比如正在等待I/O、或者内存交换等。
Memory
swpd: 虚拟内存使用情况,单位:KB
free: 空闲的内存,单位KB
buff: 被用来做为缓存的内存数,一般对块设备的读写才需要缓冲,单位:KB
cache:表示page cached的内存数量,一般作为文件系统cached,频繁访问的文件都会被cached,如果cache值较大,说明cached的文件数较多,如果此时IO中bi比较小,说明文件系统效率比较好。
Swap
si: 从磁盘交换到内存的交换页数量,单位:KB/秒
so: 从内存交换到磁盘的交换页数量,单位:KB/秒
I/O
bi: 发送到块设备的块数,单位:块/秒
bo: 从块设备接收到的块数,单位:块/秒
System
in: 每秒的中断数,包括时钟中断。
cs: 每秒的环境(上下文)切换次数
cpu
us:用户进程消耗的CPU 时间百分比。us的值比较高时,说明用户进程消耗的cpu时间多,但是如果长期大于50%,就需要考虑优化程序或算法。
sy:内核进程消耗的CPU时间百分比。Sy的值较高时,说明内核消耗的CPU资源很多。
根据经验,us+sy的参考值为70%,如果us+sy大于 70%说明可能存在CPU资源不足。
注意:
1)如果 r (run queue 运行队列中的进程数)经常大于 4 ,且id经常少于40,表示cpu的负荷很重。
2)如果si,so 长期不等于0,表示内存不足。
3)如果disk 经常不等于0, 且在 b中的队列大于3, 表示 io性能不好。
4)其拥有很高的中断数 (in) 和很低的上下文切换数, 这说明可能有单个进程在进行大量的硬件资源请求。
5)运行队列数刚好达到可接受的上限值,且出现超过上限值的情况。
如果你的系统有多个处理器核心,你就可以使用 mpstat 工具来监测每个核心。linux 内核把一个双核处理器当做 2 个 CPU,所以一个拥有 2 颗双核心的系统将被视为 4CPU。
# mpstat –P ALL 1
10:48:59 PM CPU %usr %nice %sys %iowait %irq %soft %steal %guest %idle
10:48:59 PM all 0.32 0.00 0.22 0.07 0.01 0.01 0.00 0.00 99.37
sar功能很强大,可以对系统的每个方面进行单独的统计,但是使用sar命令会增加系统开销,不过这些开销是可以评估的,对系统的统计结果不会有很大影响。
下面是sar命令对某个系统的CPU统计输出:
[root@webserver ~]# sar -u 3 5
Linux 2.6.9-42.ELsmp (webserver) 11/28/2008 _i686_ (8 CPU)
11:41:24 AM CPU %user %nice %system %iowait %steal %idle
11:41:27 AM all 0.88 0.00 0.29 0.00 0.00 98.83
11:41:30 AM all 0.13 0.00 0.17 0.21 0.00 99.50
11:41:33 AM all 0.04 0.00 0.04 0.00 0.00 99.92
11:41:36 AM all 90.08 0.00 0.13 0.16 0.00 9.63
11:41:39 AM all 0.38 0.00 0.17 0.04 0.00 99.41
Average: all 0.34 0.00 0.16 0.05 0.00 99.45
对上面每项的输出解释如下:
l %user列显示了用户进程消耗的CPU 时间百分比。
l %nice列显示了运行正常进程所消耗的CPU 时间百分比。
l %system列显示了系统进程消耗的CPU时间百分比。
l %iowait列显示了IO等待所占用的CPU时间百分比
l %steal列显示了在内存相对紧张的环境下pagein强制对不同的页面进行的steal操作 。
l %idle列显示了CPU处在空闲状态的时间百分比。
具体参考:LinuxCPU利用率计算原理及内核实现(http://ilinuxkernel.com/?p=333)
问题
1.你是否遇到过系统CPU整体利用率不高,而应用缓慢的现象?
在一个多CPU的系统中,如果程序使用了单线程,会出现这么一个现象,CPU的整体使用率不高,但是系统应用却响应缓慢,这可能是由于程序使用单线程的原因,单线程只使用一个CPU,导致这个CPU占用率为100%,无法处理其它请求,而其它的CPU却闲置,这就导致了整体CPU使用率不高,而应用缓慢现象的发生。
CPU 的性能监测包含以下部分:
* 1)检查系统运行队列并确保每个核心上不超过 3 个可运行进程
* 2)确保 CPU 利用率的用户时间和系统时间在 70/30 之间
* 3)当 CPU 花费更多的时间在 system mode 上时,更有可能是因过载而试图重新调度优先级
* 4)运行 CPU 限制型应用比 IO 限制型应用更易出现性能瓶颈
4、内存性能评估
虚拟内存是使用磁盘作为 RAM 的扩充使得可用内存的有效大小得到相应增加。 内核会将当前内存中未被使用的块的内容写入硬盘以此来腾出内存空间。 当上面的内容再次需要被用到时,它们将被重新读入内存。这些对用户完全透明;在 linux 下运行的程序只会看到有大量内存空间可用而不会去管它们的一部分时不时的从硬盘读取。 当然, 硬盘的读写操作速度比内存慢上千倍, 所以这个程序的运行速度也不会很快。 这个被用作虚拟内存的硬盘空间
呗称作交换空间(swap space) 。
虚拟内存被分成页,在 X86 架构下的每个虚拟内存页大小为 4KB,
当内核由内存向磁盘读写数据时,是以页为单位。内核会把内存页写入 swap 空间和文件系统。
盘读写数据时,是以页为单位。内核会把内存页写入 swap 空间和文件系统。
2)内核内存分页
内存分页是一个常见的动作, 不能和内存交换相混淆。 内存分页是在正常间隔下同步内存中信息至磁盘的过程。 随着时间的增长, 应用会不断耗尽内存, 有时候内核必须扫描内存并回收被分配给其他应用的空闲页面。
3)页帧回收算法(PFRA)
PFRA 负责回收内存。PFRA 根据页类型来判断是否被回收,内存页有以下类型:
* 不可被回收——locked,kernel,reserved 被锁、内核、保留页
* 可交换——无名内存页
* 可同步——被磁盘同步的页面
* 可丢弃——静态页,废弃页
除了不可被回收类型外其他均可被 PFRA 回收。PFRA 具有两个主要功能,一个是 kswapd内核进程,一个是“Low On Memory Reclaiming”功能。
4)kswapd
kswapd 守护进程负责确保内存保持可用空闲空间。它监测内核中的 pages_high 和pages_low 标记,如果空闲内存空间值小于 pages_low 值,kswwapd 进程开始扫描并尝试每次回收 32 个页面,如此重复直至空闲内存空间大于 pages_high 值。
kswapd 进程履行以下操作:
* 假如页面未改变,它将该页面放入 free list。
* 假如页面发生改变且被文件系统回写,它将页面内容写入磁盘。
* 假如页面发生改变且未被文件系统回写(无名页) ,它将页面内容写入 swap 设备。
5)pdflush 内核分页
pdflush 守护进程负责同步所有与文件系统相关的页面至磁盘,换句话说,就是当一个文件在内存中发生改变,pdflush 守护进程就将其回写进磁盘。
当内存中的脏页面数量超过 10% 时 pdflush 守护进程开始回写,这个动作与内核的vm.dirty_background_ratio 参数值有关。
# sysctl -n vm.dirty_background_ratio10
多数情况下 pdflush 守护进程与 PFRA 之间是相互独立的。除了常规的回收动作之外,当内核调用 LMR 算法时,LMR 将强制 pdflush 进行脏页面回收。
free是监控linux内存使用状况最常用的指令,看下面的一个输出:
[root@webserver ~]# free -m
total used free shared buffers cached
Mem: 8111 7185 926 0 243 6299
-/+ buffers/cache: 643 7468
Swap: 8189 0 8189
一般有这样一个经验公式:应用程序可用内存/系统物理内存>70%时,表示系统内存资源非常充足,不影响系统性能,应用程序可用内存/系统物理内存<20%时,表示系统内存资源紧缺,需要增加系统内存,20%<应用程序可用内存/系统物理内存<70%时,表示系统内存资源基本能满足应用需求,暂时不影响系统性能。
vmstat 命令除了报告 CPU 的情况外还能查看虚拟内存的使用情况,vmstat 输出的以下区域与虚拟内存有关
[root@node1 ~]# vmstat 2 3
procs -----------memory---------- ---swap-- -----io---- --system-- -----cpu------
r b swpd free buff cache si so bi bo in cs us sy id wa st
0 0 0 162240 8304 67032 0 0 13 21 1007 23 0 1 98 0 0
0 0 0 162240 8304 67032 0 0 1 0 1010 20 0 1 100 0 0
0 0 0 162240 8304 67032 0 0 1 1 1009 18 0 1 99 0 0
memory
swpd列表示切换到内存交换区的内存数量(以k为单位)。如果swpd的值不为0,或者比较大,只要si、so的值长期为0,这种情况下一般不用担心,不会影响系统性能。
free列表示当前空闲的物理内存数量(以k为单位)
buff列表示buffers cache的内存数量,一般对块设备的读写才需要缓冲。
cache列表示page cached的内存数量,一般作为文件系统cached,频繁访问的文件都会被cached,如果cache值较大,说明cached的文件数较多,如果此时IO中bi比较小,说明文件系统效率比较好。
swap
si列表示由磁盘调入内存,也就是内存进入内存交换区的数量。
so列表示由内存调入磁盘,也就是内存交换区进入内存的数量。
一般情况下,si、so的值都为0,如果si、so的值长期不为0,则表示系统内存不足。需要增加系统内存。
例如大规模IO写入:
vmstat 3
procs memory swap io system cpu
r b swpd free buff cache si so bi bo in cs us sy id wa
3 2 809192 261556 79760 886880 416 0 8244 751 426 863 17 3 6 75
0 3 809188 194916 79820 952900 307 0 21745 1005 1189 2590 34 6 12 48
0 3 809188 162212 79840 988920 95 0 12107 0 1801 2633 2 2 3 94
1 3 809268 88756 79924 1061424 260 28 18377 113 1142 1694 3 5 3 88
1 2 826284 17608 71240 1144180 100 6140 25839 16380 1528 1179 19 9 12 61
2 1 854780 17688 34140 1208980 1 9535 25557 30967 1764 2238 43 13 16 28
0 8 867528 17588 32332 1226392 31 4384 16524 27808 1490 1634 41 10 7 43
4 2 877372 17596 32372 1227532 213 3281 10912 3337 678 932 33 7 3 57
1 2 885980 17800 32408 1239160 204 2892 12347 12681 1033 982 40 12 2 46
5 2 900472 17980 32440 1253884 24 4851 17521 4856 934 1730 48 12 13 26
1 1 904404 17620 32492 1258928 15 1316 7647 15804 919 978 49 9 17 25
4 1 911192 17944 32540 1266724 37 2263 12907 3547 834 1421 47 14 20 20
1 1 919292 17876 31824 1275832 1 2745 16327 2747 617 1421 52 11 23 14
5 0 925216 17812 25008 1289320 12 1975 12760 3181 772 1254 50 10 21 19
0 5 932860 17736 21760 1300280 8 2556 15469 3873 825 1258 49 13 24 15
通过以上数据可得出以下结果:
* 大量的数据从磁盘读入内存(bi) ,因 cache 值在不断增长
* 尽管数据正不断消耗内存,空闲空间仍保持在 17M 左右
* buff 值正不断减少,说明 kswapd 正不断回收内存
* swpd 值不断增大,说明 kswapd 正将脏页面内容写入交换空间(so)
5、磁盘i/o性能评估
l 熟悉RAID存储方式,可以根据应用的不同,选择不同的RAID方式。
l 尽可能用内存的读写代替直接磁盘I/O,使频繁访问的文件或数据放入内存中进行操作处理,因为内存读写操作比直接磁盘读写的效率要高千倍。
l 将经常进行读写的文件与长期不变的文件独立出来,分别放置到不同的磁盘设备上。
l 对于写操作频繁的数据,可以考虑使用裸设备代替文件系统。
使用裸设备的优点有:
ü 数据可以直接读写,不需要经过操作系统级的缓存,节省了内存资源,避免了内存资源争用。
ü 避免了文件系统级的维护开销,比如文件系统需要维护超级块、I-node等。
ü 避免了操作系统的cache预读功能,减少了I/O请求。
使用裸设备的缺点是:
ü 数据管理、空间管理不灵活,需要很专业的人来操作。
磁盘 IO 子系统是 linux 系统里最慢的部分,这是由于其与 CPU 相比相去甚远,且依赖于物理式工作(转动和检索) 。如果将读取磁盘和读取内存所花费的时间转换为分秒,那么他们之间的差距是 7 天和 7 分钟,所以 linux 内核尽量少的进行磁盘操作是至关重要的。以下部分将描述下内核处理数据从磁盘到内存和从内存到磁盘的不同方式。
1)数据读写——内存页面
linux 内核将磁盘 IO 分为页面进行操作, 大多数 linux 系统中默认页面大小为 4K, 即以4K 为单位进行磁盘和内存间的读写操作。我们可以使用 time 命令来查找页面大小:
# /usr/bin/time -v date
......
Page size (bytes): 4096
2)主要页错误(Major Page Faults)和次要页错误(Minor PageFaults)
linux 和大多数 UNIX 系统一样,使用虚拟内存层来映射物理地址空间,这种映射在某种意义上是说当一个进程开始运行,内核仅仅映射其需要的那部分,内核首先会搜索 CPU缓存和物理内存,如果没有找到内核则开始一次 MPF, 一次 MPF 即是一次对磁盘子系统的请求,它将数据页从磁盘和缓存读入 RAM。一旦内存页被映射到高速缓冲区,内核便会试图使用这些页,被称作 MnPF,MnPF 通过重复使用内存页而缩短了内核时间。
在下面示例中,time 命令显示了当一个程序启动的时候产生了多少 MPF 和 MnPF,在第一次启动的时候产生了很多 MPF:
# /usr/bin/time -v evolution
......
Major (requiring I/O) page faults: 163
Minor (reclaiming a frame) page faults: 5918
......
第二次启动的时候 MPF 消失因为程序已经在内存中:
# /usr/bin/time -v evolution
......
Major (requiring I/O) page faults: 0
Minor (reclaiming a frame) page faults: 5581
......
3)文件缓冲区
文件缓冲区可使内核减少对 MPFs 和 MnPFs 的使用, 随着系统不断地 IO 操作, 缓冲区会随之增大, 直至内存空闲空间不足并开始回收, 最终结果是系统管理员们开始关心这个事实,但这只是系统正在很好的使用缓冲空间而已。
下面的输入来自/proc/meminfo 文件:
# cat /proc/meminfo
MemTotal: 2075672 kB
MemFree: 52528 kB
Buffers: 24596 kB
Cached: 1766844 kB
......
以上显示系统拥有 2G 内存, 当前有 52MB 空闲空间, 24MB 的 buffer 供应磁盘写操作, 1.7GB的 cache 由磁盘读入内存。内核通过 MnPF 机制来使用这些东东,光这些数据还不足以说明系统出现瓶颈。
4)内存页面分类
在 linux 内核中有 3 种内核页:
* 读取页面——从磁盘读入(MPF)的只读页面,这些页面存在于缓冲区中包括不可改变的静态文件,二进制文件和库文件。内核会因需求而不断地将他们读入内存,如
果内存变得不够用,内核会将他们“窃取”至空闲列表,这将导致某个应用通过 MPF将它们重新加载至内存。
* 脏页面——在内存中被内核修改的页面,它们将被 pdflush 守护进程回写至磁盘, 当内存不够用时,kswapd 进程也会和 pdflush 一道进行回写以释放更多内存空间。
* 无名页面——它们属于某个进程,但是没有任何文件或后端存储与之关联,它们不能被回写进磁盘,当内存不够用时 kswapd 守护进程会将它们写入交换空间直至 RAM
释放出来。
5)数据页面磁盘回写
应用可能直接调用 fsync()或 sync()系统调用将脏页面回写入磁盘, 这些系统调用会直接请求至 I/O 调度器。如果一个应用不调用它们,则 pdflush 守护进程会时不时地进行页面回写操作。
计算每秒 IO 量:
每一次向磁盘的 IO 请求都会花费一定时间,这主要是因为磁盘必须旋转,磁头必须检索。磁盘的旋转通常被称为“旋转延迟(rotational delay)” (RD) ,磁头的移动杯称为“磁盘
检索(disk seek)” (DS) 。因此每次 IO 请求的时间由 DS 和 RD 计算得来,磁盘的 RD 由驱动气的转速所固定,一 RD 被为磁盘一转的一半,计算一块 10000 转磁盘的 RD 如下:
1. 算出每转的秒数:60 秒/10000 转 = 0.006 秒/转
2. 转换为毫秒: 0.006*1000 毫秒 = 6 毫秒
3. 算出 RD 值: 6/2 = 3 毫秒
4. 加上平均检索时间:3+3 = 6 毫秒
5. 加上内部转移等待时间: 6+2 = 8 毫秒
6. 算出一秒的 IO 数:1000 毫秒/8 毫秒 = 125 次/秒(IOPS)
在一块万转硬盘上应用每请求一次 IO 需要 8 毫秒,每秒可提供 120 到 150 次操作。
[root@webserver ~]# iostat -d 2 3
Linux 2.6.9-42.ELsmp (webserver) 12/01/2008 _i686_ (8 CPU)
Device: tps Blk_read/s Blk_wrtn/s Blk_read Blk_wrtn
sda 1.87 2.58 114.12 6479462 286537372
Device: tps Blk_read/s Blk_wrtn/s Blk_read Blk_wrtn
sda 0.00 0.00 0.00 0 0
Device: tps Blk_read/s Blk_wrtn/s Blk_read Blk_wrtn
sda 1.00 0.00 12.00 0 24
对上面每项的输出解释如下:
tps平均每秒钟的IO请求次数
Blk_read/s表示每秒读取的数据块数。
Blk_wrtn/s表示每秒写入的数据块数。
Blk_read表示读取的所有块数。
Blk_wrtn表示写入的所有块数。
? 可以通过Blk_read/s和Blk_wrtn/s的值对磁盘的读写性能有一个基本的了解,如果Blk_wrtn/s值很大,表示磁盘的写操作很频繁,可以考虑优化磁盘或者优化程序,如果Blk_read/s值很大,表示磁盘直接读取操作很多,可以将读取的数据放入内存中进行操作。
? 对于这两个选项的值没有一个固定的大小,根据系统应用的不同,会有不同的值,但是有一个规则还是可以遵循的:长期的、超大的数据读写,肯定是不正常的,这种情况一定会影响系统性能。
通过“sar –d”组合,可以对系统的磁盘IO做一个基本的统计,请看下面的一个输出:
[root@webserver ~]# sar -d 2 3
Linux 2.6.9-42.ELsmp (webserver) 11/30/2008 _i686_ (8 CPU)
11:09:33 PM DEV tps rd_sec/s wr_sec/s avgrq-sz avgqu-sz await svctm %util
11:09:35 PM dev8-0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
11:09:35 PM DEV tps rd_sec/s wr_sec/s avgrq-sz avgqu-sz await svctm %util
11:09:37 PM dev8-0 1.00 0.00 12.00 12.00 0.00 0.00 0.00 0.00
11:09:37 PM DEV tps rd_sec/s wr_sec/s avgrq-sz avgqu-sz await svctm %util
11:09:39 PM dev8-0 1.99 0.00 47.76 24.00 0.00 0.50 0.25 0.05
Average: DEV tps rd_sec/s wr_sec/s avgrq-sz avgqu-sz await svctm %util
Average: dev8-0 1.00 0.00 19.97 20.00 0.00 0.33 0.17 0.02
需要关注的几个参数含义:
await表示平均每次设备I/O操作的等待时间(以毫秒为单位)。
svctm表示平均每次设备I/O操作的服务时间(以毫秒为单位)。
%util表示一秒中有百分之几的时间用于I/O操作。
对以磁盘IO性能,一般有如下评判标准:
正常情况下svctm应该是小于await值的,而svctm的大小和磁盘性能有关,CPU、内存的负荷也会对svctm值造成影响,过多的请求也会间接的导致svctm值的增加。
await值的大小一般取决与svctm的值和I/O队列长度以及I/O请求模式,如果svctm的值与await很接近,表示几乎没有I/O等待,磁盘性能很好,如果await的值远高于svctm的值,则表示I/O队列等待太长,系统上运行的应用程序将变慢,此时可以通过更换更快的硬盘来解决问题。
%util项的值也是衡量磁盘I/O的一个重要指标,如果%util接近100%,表示磁盘产生的I/O请求太多,I/O系统已经满负荷的在工作,该磁盘可能存在瓶颈。长期下去,势必影响系统的性能,可以通过优化程序或者通过更换更高、更快的磁盘来解决此问题。
6、网络性能评估
网络是所有子系统中最难监测的一个, 因为网络比较抽象, 在监测时有很多在系统可控制之外的因素如延迟,冲突,拥塞和丢包等对监测产生影响。下面将讨论的是以太网、IP、TCP 的性能监测。
1)以太网配置设定
除非有明确的设定, 所有以太网的速度都是自动协商的, 这很大程度上是由于历史原因造成的,早些时候一个网络里经常有不同网速和双工模式的网络设备。
大多数企业以太网是 100BaseTX 或 1000BaseTX,可以使用 ethtool 工具来判断一个系统的网速。
下面的示例中一个拥有 100BaseTX 网卡的机器工作在 10BaseTX 下:
# ethtool eth0
Settings for eth0:
Supported ports: [ TP MII ]
Supported link modes: 10baseT/Half 10baseT/Full
100baseT/Half 100baseT/Full
Supports auto-negotiation: Yes
Advertised link modes: 10baseT/Half 10baseT/Full
100baseT/Half 100baseT/Full
Advertised auto-negotiation: Yes
Speed: 10Mb/s
Duplex: Half
Port: MII
PHYAD: 32
Transceiver: internal
Auto-negotiation: on
Supports Wake-on: pumbg
Wake-on: d
Current message level: 0x00000007 (7)
Link detected: yes
下面将其强制设定为 100BaseTX 模式:
# ethtool -s eth0 speed 100 duplex full autoneg off
# ethtool eth0
Settings for eth0:
Supported ports: [ TP MII ]
Supported link modes: 10baseT/Half 10baseT/Full
100baseT/Half 100baseT/Full
Supports auto-negotiation: Yes
Advertised link modes: 10baseT/Half 10baseT/Full
100baseT/Half 100baseT/Full
Advertised auto-negotiation: No
Speed: 100Mb/s
2)网络吞吐量监测
监测网络吞吐量最好的办法是在两个系统之间发送流量并统计其延迟和速度。
3)使用 iptraf 监测本地吞吐量
iptraf 工具可提供以太网卡的吞吐量情况:
# iptraf -d eth0
上面的数据显示被测试系统正以 61mbps(7.65M)频率发送数据,相比于 100mbps 网络这有点低。
4)使用 netperf 监测远端吞吐量
与 iptraf 的动态监测不一样的是 netperf 使用可控方式测试网络, 这一点对测试一个客户端到一个高负载服务器之间的吞吐量很有帮助,netperf 工具是以 C/S 模式运行。
首先需要在服务器上运行 netperf 服务端:
server# netserver
Starting netserver at port 12865
Starting netserver at hostname 0.0.0.0 port 12865 and family AF_UNSPEC
netperf 可以执行多种测试,最基本的是标准测试:
输出显示吞吐量在 89mbps 左右,服务器和客户端在同一网段。从一个 10 跳的 54G 无线网进行测试只能达到 14mbps 左右:
client# netperf -H 192.168.1.215 -l 30
TCP STREAM TEST from 0.0.0.0 (0.0.0.0) port 0 AF_INET to
192.168.1.215 (192.168.1.215) port 0 AF_INET
Recv Send
Send
Socket Socket Message Elapsed
Size Size
Size Time
Throughput
bytes bytes
bytes secs.
10^6bits/sec
87380 16384
16384 30.10
14.09
从 50 跳距离局域网测试:
# netperf -H 192.168.1.215 -l 30
TCP STREAM TEST from 0.0.0.0 (0.0.0.0) port 0 AF_INET to
192.168.1.215 (192.168.1.215) port 0 AF_INET
Recv Send Send
Socket Socket
Message Elapsed
Size Size SizeTimeThroughput
bytes bytes bytessecs.10^6bits/sec
87380 16384 1638430.645.05
从外网测试:
# netperf -H litemail.org -p 1500 -l 30
litemail.org (72.249.104.148) port 0 AF_INET
Recv Send Send
Socket Socket
Message Elapsed
Size Size SizeTimeThroughput
bytes bytes bytessecs.10^6bits/sec
87380 16384 1638431.580.93
另外一个有用的测试模式是测试 TCP 请求应答速率, 其原理是建立一个 TCP 连接并发送多个请求:
client# netperf -t TCP_RR -H 192.168.1.230 -l 30
TCP REQUEST/RESPONSE TEST from 0.0.0.0 (0.0.0.0) port 0 AF_INET
to 192.168.1.230 (192.168.1.230) port 0 AF_INET
Local /Remote
Socket Size Request Resp. ElapsedTrans.
Send Recv SizeSizeTimeRate
bytes Bytes bytesbytessecs.per sec
16384 87380 1130.00 4453.80
16384 87380
数据显示网络可支持 4453 左右的 psh/ack 每秒,因为发送包的大小只有 1k。下面使用 2k的请求和 32k 的应答:
client# netperf -t TCP_RR -H 192.168.1.230 -l 30 -- -r 2048,32768
TCP REQUEST/RESPONSE TEST from 0.0.0.0 (0.0.0.0) port 0 AF_INET to
192.168.1.230 (192.168.1.230) port 0 AF_INET
Local /Remote
Socket Size RequestResp.ElapsedTrans.
Send Recv SizeSizeTimeRate
bytes Bytes bytesbytessecs.per sec
16384 87380 20483276830.00222.37
16384 87380
可以看到速率已经降到 222 左右。
/////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////
(1)通过ping命令检测网络的连通性
(2)通过netstat –i组合检测网络接口状况
(3)通过netstat –r组合检测系统的路由表信息
(4)通过sar –n组合显示系统的网络运行状态
l netstat -antl 查看所有tcp status:
注意:可以通过netstat查看是否timewait过多的情况,导致端口不够用,在短连接服务中且大并发情况下,要不系统的net.ipv4.tcp_tw_reuse、net.ipv4.tcp_tw_recycle两个选项打开,允许端口重用。具体这两个属性如何用,移步线上/etc/sysctl.conf文件配置,有注释。
sar查看网卡性能:sar -n DEV 1 100
Linux 2.6.32-431.20.3.el6.x86_64 (iZ25ug3hg9iZ) 09/18/2014 _x86_64_ (4 CPU)
04:01:23 PM IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s
04:01:24 PM lo 0.00 0.00 0.00 0.00 0.00 0.00 0.00
04:01:24 PM eth0 4.04 0.00 0.16 0.00 0.00 0.00 0.00
04:01:24 PM eth1 26.26 0.00 1.17 0.00 0.00 0.00 0.00
各列含义:
IFACELAN接口
rxpck/s每秒钟接收的数据包
txpck/s每秒钟发送的数据包
rxbyt/s每秒钟接收的字节数
txbyt/s每秒钟发送的字节数
rxcmp/s每秒钟接收的压缩数据包
txcmp/s每秒钟发送的压缩数据包
rxmcst/s每秒钟接收的多播数据包
其实中间的IFACELAN bond0是虚拟设备。在RH中,多个物理网卡帮定为一个逻辑bonding设备,通过把多个物理网卡帮定为一个逻辑设备,可以实现增加带宽吞吐量,提供冗余。如何进行虚拟化和模式选择,请参考下面两篇文章。
7、监控利器
dstat是一个用来替换vmstat,iostat netstat,nfsstat和ifstat这些命令的工具, 是一个全能系统信息统计工具.它是由Python编写的, 与sysstat相比,dstat是以一个彩色的界面动态显示,这样数据比较显眼,容易观察,一目了然; 而且dstat支持即时刷新,可以使用相关参数指定显示哪些内容!下后会有说明。下面开始进入dstat的神秘世界!!!!!!!!!!!!!!官方站点:http://dag.wieers.com/home-made/dstat/#download
nginx+php-fpm的并发处理能力计算:
php-fpm进程执行时间=t ms
服务器cpu函数=n
并发执行能力qps= 1s/t * 1000 *n.
如果平均php-fpm进程执行时间10ms, cpu=4核。 并发处理能力=1/10 × 1000 ×4= 400.
QPS = req/sec = 请求数/秒
【QPS计算PV和机器的方式】
QPS统计方式 [一般使用 http_load 进行统计]
QPS = 总请求数 / ( 进程总数 * 请求时间 )
QPS: 单个进程每秒请求服务器的成功次数
单台服务器每天PV计算
公式1:每天总PV = QPS * 3600 * 6
公式2:每天总PV = QPS * 3600 * 8
服务器计算
服务器数量 = ceil( 每天总PV / 单台服务器每天总PV )
【峰值QPS和机器计算公式】
原理:每天80%的访问集中在20%的时间里,这20%时间叫做峰值时间
公式:( 总PV数 * 80% ) / ( 每天秒数 * 20% ) = 峰值时间每秒请求数(QPS)
机器:峰值时间每秒QPS / 单台机器的QPS = 需要的机器
问:每天300w PV 的在单台机器上,这台机器需要多少QPS?
答:( 3000000 * 0.8 ) / (86400 * 0.2 ) = 139 (QPS)
问:如果一台机器的QPS是58,需要几台机器来支持?
答:139 / 58 = 3
注意:如果 r经常大于 4 ,且id经常少于40,表示cpu的负荷很重。
如果si,so 长期不等于0,表示内存不足。
如果disk 经常不等于0, 且在 b中的队列大于3, 表示 io性能不好。
标签:
原文地址:http://blog.csdn.net/hguisu/article/details/39373311

