标签:
当我们在浏览器中输入"www.google.com"的时候,首先会请求DNS服务器对域名进行解析成都应的IP地址,然后根据这个IP地址在互联网上找到谷歌的服务器,向这个服务器发送一个"get"请求,有这个服务器决定返回数据资源给请求的用户(在服务器端可能还会存在其他复杂的业务逻辑,服务器端有很多机器的话,需要考虑负载均衡,由哪一台服务器对资源进行回复,请求的文件是存储在静态文件中还是存储在分布式缓存中或者是数据库中,当数据返回服务器时,会发现该请求包含有一些静态资源(CSS文件、JS文件、图片文件)等又会发起HTTP请求,而这些请求又很可能是在CDN上,那么CDN又会处理这些请求。
所有的请求都是通过URL(统一资源定位符)来进行定位的。
通常我们的请求是借助浏览器发送的,实际上我们可以自己模拟HTTP的请求。建立HTTP请求的过程实际上就是建立socket链接的过程,
(1) connect -> 根据域名地址和HTTP默认的80端口建立socket链接;
(2) send -> 客户端发送符合HTTP协议格式的数据(outputStream.write);
(3) receive -> 服务器等待inputStream.read返回数据
(4) close -> 客户端和服务器断开连接
知道了以上的过程,我们就可以很轻松的模拟浏览器发出一个HTTP协议,这方面的工具包有很多,例如HttpClient就是一个封装好的工具包,下面是利用该包进行调用的一个实例
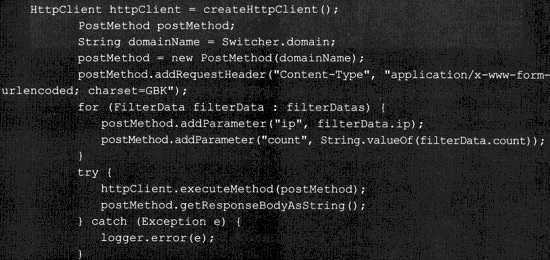
当然,我们还可以利用Linux下的curl + url 来模拟一个请求
HTTP协议的重要性不再重述,下面是HTTP协议的各个部分:

浏览器缓存机制是一个比较重要的机制,当我们访问一些静态文件,比如JS文件,CSS文件,图片文件时通过缓存,可以减少和服务器连接的次数,提高浏览的速度。
在浏览器端,按 ctrl +F5的组合键会要求浏览器直接向目标服务器发送请求,而不会使用浏览器缓存中的数据,其次,即使请求到服务器,我们获得的也有可能是服务器缓存的数据,为了获得最新的数据,必须通过HTTP协议来进行控制,方法就是在浏览器请求头中添加 Pragme:no-cache 和 Cache-Control:no-cache
HTTP head中有一些字段,可以控制浏览器请求的数据是否缓存的或者是最新的。

DNS域名解析的过程大致可以分为10个步骤:
当我们在浏览器输入"www.google.com”并按下 enter时,大致过程为:
(1)浏览器检查缓存中有没有www.google.com解析过的IP地址,如果缓存中有这个数据,解析过程就会停止。需要注意的是浏览器缓存的大小和时间都是有限制的,通常为几分钟到几小时。浏览器被缓存的时间可以通过TTL属性来设置。如果被设置的时间太长,一旦浏览器解析的域名的IP地址有变,就会访问不到,如果太短,则每次都需要访问域名服务器。
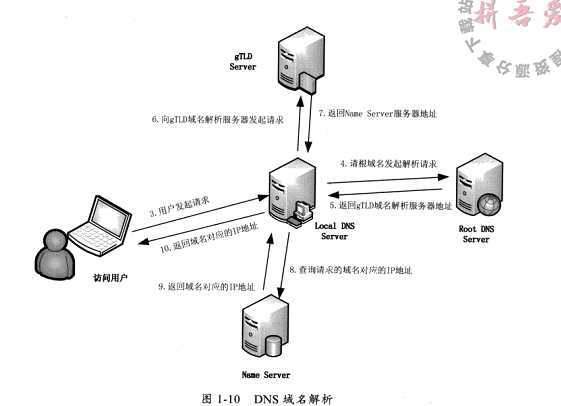
(2)一旦本地的浏览器缓存中没有数据,则浏览器会到操作系统下的hosts文件中检查是否有该域名的解析。
(3)如果本地没有的话,就需要请求本地域名服务器了,怎样才能知道域名服务器的地址呢(网络配置),
(4)如果本地仍没有的话,就需要请求根域名服务器,全球只有13台左右。
..........
通过nslookup指令可以查看域名的解析过程,通过ipconfig/flushdns可以将缓存在本地的DNS清除
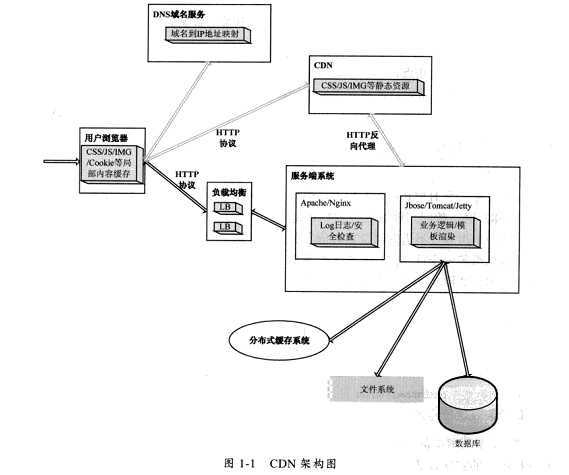
CDN成为内容分布网络(Content-delivery-Network),它是构建在Internent上的先进的流量分配网络。其目的是通过在现有的Internet上增加一层新的网络架构,将网站的内容发布到最接近用户的网络边缘,使得用户可以就近获得多需要的资源,可以说,CDN = 镜像(mirror) + 缓存(cache) + 负载均衡(GSLB)。目前,CDN都是以缓存网站中的静态数据为主;用户从主站服务器上下载动态内容后再到CDN上下载静态文件
一、CDN架构:
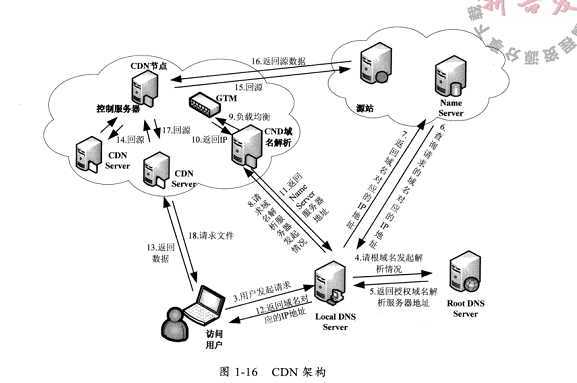
CDN 的实现要考虑负载均衡,而负载均衡的又包括DNS解析负载均衡,集群的负载均衡以及操作系统的负载均衡,内容比较多......
关键字: CDN、负载均衡、浏览器缓存
参考: 《深入分析Java web技术内幕》
标签:
原文地址:http://www.cnblogs.com/CBDoctor/p/4232326.html