标签:
---恢复内容开始---
过滤器是一个驻留在服务器端的Web组建,可以截取客户端和资源之间的请求和响应信息。Web过滤器是不能直接处理客户端请求,返回客户端数据的!
举例来说:当我们登录CSDN或邮箱的时候,输入应用名和密码就可以进入我们请求的页面,当我们点击退出后,下一次进入时需要重新输入登录用户名与密码。这是过滤器应用的一个场景。
我们需要了解:
1、过滤器的工作原理
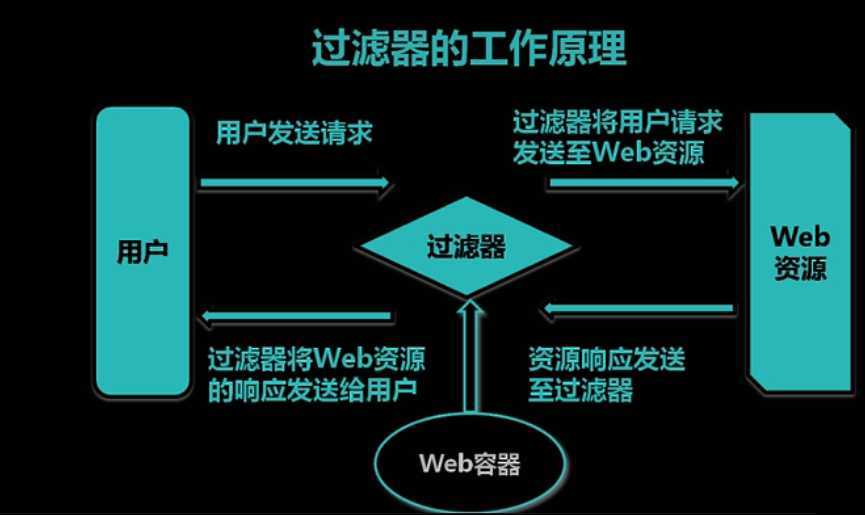
上面的图简单说明了过滤器在客户端和服务器之间的作用。
2、过滤器的生命周期
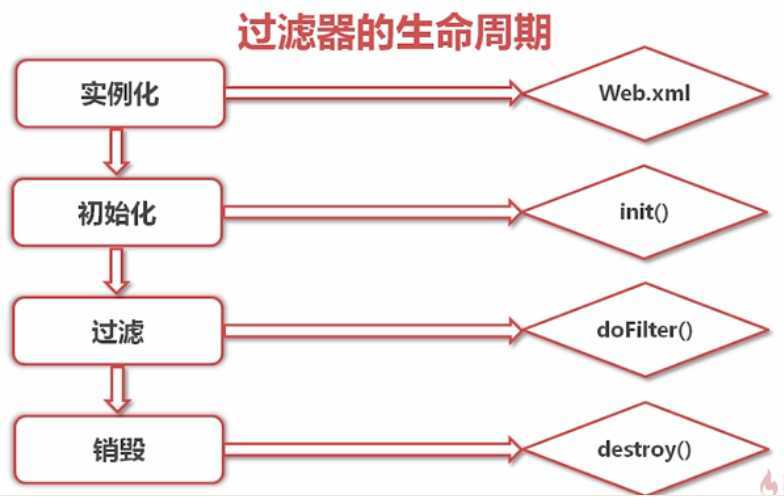
Web容器启动的时候,会加载web.xml并执行一次init()函数,然后每次客户端的请求都会执行doFilter()函数,最后当容器关闭的时候会执行destroy()函数

上面显示的是一个Web应用程序的结构,所有的Webroot中的内容都是Web的内容,Web-INF下所有的资源都不能直接被url访问,其他的文件,用户可以通过url访问。
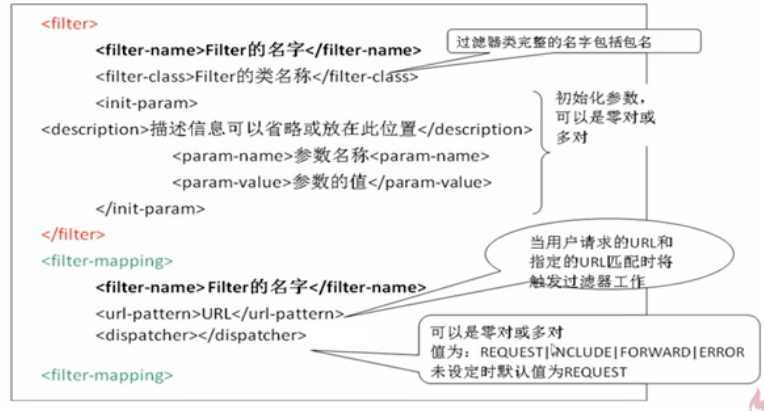
关于url-pattern的书写规范,
(A)一个filter映射一个url:这种情况下的url与url-pattern中配置的url进行精确匹配。url-pattern中的访问路径必须以 / 开头,表示的是Web应用程序的根目录,而不是Web站点的根目录,路径名称可以是多级目录的形式,例如
<url-pattern>/demo/index.html</url-pattern>
(B)一个filter映射多个url:这种情况下可以使用通配符,需要注意的也有两种情况:
(1)*.扩展名,*点前面不能有 “/”
(2)以/开头,并以 /* 结尾,例如
<url-pattern>/action/*</url-pattern>表示的是整个action目录下的url
<url-pattern>/</url-pattern>表示的是整个web应用程序下的url
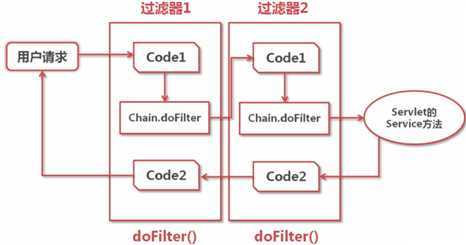
过滤器链
---恢复内容结束---
过滤器是一个驻留在服务器端的Web组建,可以截取客户端和资源之间的请求和响应信息。Web过滤器是不能直接处理客户端请求,返回客户端数据的!
举例来说:当我们登录CSDN或邮箱的时候,输入应用名和密码就可以进入我们请求的页面,当我们点击退出后,下一次进入时需要重新输入登录用户名与密码。这是过滤器应用的一个场景。
我们需要了解:
1、过滤器的工作原理
上面的图简单说明了过滤器在客户端和服务器之间的作用。
2、过滤器的生命周期
Web容器启动的时候,会加载web.xml并执行一次init()函数,然后每次客户端的请求都会执行doFilter()函数,最后当容器关闭的时候会执行destroy()函数
上面显示的是一个Web应用程序的结构,所有的Webroot中的内容都是Web的内容,Web-INF下所有的资源都不能直接被url访问,其他的文件,用户可以通过url访问。
关于url-pattern的书写规范,
(A)一个filter映射一个url:这种情况下的url与url-pattern中配置的url进行精确匹配。url-pattern中的访问路径必须以 / 开头,表示的是Web应用程序的根目录,而不是Web站点的根目录,路径名称可以是多级目录的形式,例如
<url-pattern>/demo/index.html</url-pattern>
(B)一个filter映射多个url:这种情况下可以使用通配符,需要注意的也有两种情况:
(1)*.扩展名,*点前面不能有 “/”
(2)以/开头,并以 /* 结尾,例如
<url-pattern>/action/*</url-pattern>表示的是整个action目录下的url
<url-pattern>/</url-pattern>表示的是整个web应用程序下的url
过滤器链
标签:
原文地址:http://www.cnblogs.com/CBDoctor/p/4235082.html