标签:
昨天分析的进程的代码让自己还在头昏目眩,脑子中这几天都是关于Linux内核的,对于自己出现的一些问题我会继续改正,希望和大家好好分享,共同进步。今天将会讲诉Linux如何追踪和管理用户空间进程的可用内存和内核的可用内存,还会讲到内核对内存分类的方式以及如何决定分配和释放内存,内存管理是应用程序通过软硬件协助来访问内存的一种方式,这里我们主要是介绍操作系统正常运行对内存的管理。插个话题,刚才和姐姐聊天,她快结婚了,说起了自己的初恋,可能是一句很搞笑的话,防火防盗防初恋,,嘎嘎,这个好像是的吧,尽管大三了,有了新的女友,也特别喜欢她,把她当作未来的伴侣,但是那个时候确实很美好,难怪哦姐姐聊起这些,这里祝福姐姐,心情好相信接下来的博客讲解一定可以状态大好,和大家一起好好分享。
在深入了解内存管理的实现之前一些有关内存管理的高级概念我们有必要了解一下,先说虚拟内存,怎么产生的呢?现在操作系统要求能够使多个程序共享操作系统资源,并且还要求内存对程序的开发透明,有了虚拟内存之后,依靠透明的使用磁盘空间,就可以使系统物理内存大得多,而且使得多个程序共享更加容易方便。然后再说说虚拟地址,当一个程序从内存中存取数据时,会使用地址来指出需要访问的内存地址,这就是虚拟地址,它组成了进程虚拟地址空间,其大小取决于体系结构的字宽。内存管理在操作系统中负责维护虚拟地址和物理地址之间的关系并且实现分页机制(将页从内存到磁盘之间调入调出的机制), 内核把物理页作为内存管理的基本单位;内存管理单元(MMU)把虚拟地址转换为物理地址,通常以页为单位进行处理。如:
32位系统:页大小4KB
64位系统:页大小8KB
上述这些数据都会在页面载入内存时候得以更新,下面来看看内核是如何利用页来实现内存管理的。
作为内存管理的基本单元,页有许多属性需要维护,下面的结构体描述了页描述符的各种域以及内存管理是如何使用它们的,在include/linux/mm.h中可以查看到定义。
1 struct page 2 { 3 unsigned long flags; //flags用来存放页的状态,每一位代表一种状态 4 atomic_t count; //count记录了该页被引用了多少次 5 unsigned int mapcount; 6 unsigned long private; 7 struct address_space *mapping; //mapping指向与该页相关的address_space对象 8 pgoff_t index; 9 struct list_head lru; //存放的next和prev指针,指向最近使用(LRU)链表中的相应结点 10 union 11 { 12 struct pte_chain; 13 pte_addr_t; 14 } 15 void *virtual; //virtual是页的虚拟地址,它就是页在虚拟内存中的地址 16 };
要理解的一点是page结构与物理页相关,而并非与虚拟页相关。因此,该结构对页的描述是短暂的。内核仅仅用这个结构来描述当前时刻在相关的物理页中存放的东西。这种数据结构的目的在于描述物理内存本身,而不是描述包含在其中的数据。
在linux中,内核也不是对所有的也都一视同仁,内核而是把页分为不同的区,使用区来对具有相似特性的页进行分组。Linux必须处理如下两种硬件存在缺陷而引起的内存寻址问题:
为了解决这些制约条件,Linux系统使用了三种区:
每个内存区都有一个对应的描述符号zone,zone结构被定义在/linux/mmzone.h中,接下来浏览一下该结构的一些域:
struct zone { spinlock_t lock; //lock域是一个自旋锁,这个域只保护结构,而不是保护驻留在这个区中的所有页 unsigned long free_pages; //持有该内存区中所剩余的空闲页链表 unsigned long pages_min, pages_low, pages_high; //持有内存区的水位值 unsigned long protection[MAX_NR_ZONES]; spinlock_t lru_lock; //持有保护空闲页链表的自旋锁 struct list_head active_list; 在页面回收处理时,处于活动状态的页链表 struct list_head inactive_list; //在页面回收处理时,是可以被回收的页链表 unsigned long nr_scan_active; unsigned long nr_scan_inactive; unsigned long nr_active; unsigned long nr_inactive; int all_unreclaimable; //内存的所有页锁住时,此值置1 unsigned long pages_scanned; //用于页面回收处理中 struct free_area free_area[MAX_ORDER]; wait_queue_head_t * wait_table; unsigned long wait_table_size; unsigned long wait_table_bits; //用于处理该内存区页上的进程等待 struct per_cpu_pageset pageset[NR_CPUS]; struct pglist_data *zone_pgdat; struct page *zone_mem_map; unsigned long zone_start_pfn; char *name; unsigned long spanned_pages; unsigned long present_pages; };
内核提供了一种请求内层的底层机制,并提供了对它进行访问的几个接口。所有这些接口都是以页为单位进行操作的页面是物理内存存储页的基本单元,只要有进程申请内存,内核便会请求一个页面给它,同理,如果页面不再使用,那么内核将其释放,以便其他进程可以使用,下面介绍一下这些函数。
alloc_page() 用于请求单页,不需要描述请求内存大小的order参数
alloc_pages() 可以请求页面组
#define alloc_pages(gfp_mask,order)
alloc_pages_node(numa_node_id(),gfp_mask,order) #define alloc_page(gfp_mask) alloc_pages_node(numa_node_id(),gfp_mask,0)
__get_free_page() 请求单页面操作的简化版本
include/linux/gfp.h #define __get_dma_pages(gfp_mask,order) \ __get_free_pages((gfp_mask)|GFP_DMA,(order))
__get_dma_pages() 用于从ZONE_DMA区请求页面
include/linux/gfp.h #define __get_dma_pages(gfp_mask,order) \ __get_free_pages((gfp_mask)|GFP_DMA,(order))
当你不再需要页时可以用下列函数释放它们,只是提醒:仅能释放属于你的页,否则可能导致系统崩溃。内核是完全信任自己的,如果有非法操作,内核会开心的把自己挂起来,停止运行。
extern void __free_pages(struct page *page, unsigned int order); extern void free_pages(unsigned long addr, unsigned int order);
上面提到都是以页为单位的分配方式,那么对于常用的以字节为单位的分配来说,内核通供的函数是kmalloc(),和mallloc很像吧,其实还真是这样,只不过多了一个flags参数。用它可以获得以字节为单位的一块内核内存。
kmalloc
kmalloc()函数与用户空间malloc一组函数类似,获得以字节为单位的一块内核内存。
void *kmalloc(size_t size, gfp_t flags)
void kfree(const void *objp)
分配内存物理上连续。
gfp_t标志:表明分配内存的方式。如:
GFP_ATOMIC:分配内存优先级高,不会睡眠
GFP_KERNEL:常用的方式,可能会阻塞。
vmalloc
void *vmalloc(unsigned long size)
void vfree(const void *addr)
vmalloc()与kmalloc方式类似,vmalloc分配的内存虚拟地址是连续的,而物理地址则无需连续,与用户空间分配函数一致。
vmalloc通过分配非连续的物理内存块,在修正页表,把内存映射到逻辑地址空间的连续区域中,虚拟地址是连续的。 是否必须要连续的物理地址和具体使用场景有关。在不理解虚拟地址的硬件设备中,内存区都必须是连续的。通过建立页表转换成虚拟地址空间上连续,肯定存在一些消耗,带来性能上影响。所以通常内核使用kmalloc来申请内存,在需要大块内存时使用vmalloc来分配。
进程往往会以字节为单位请求小块内存,为了满足这种小内存的请求,内核特别实现了Slab分配器,Slab分配器使用三个主要结构维护对象信息,分别如下:
kmem_cache的缓存描述符
cache_sizes的通用缓存描述符
slab的slab描述符
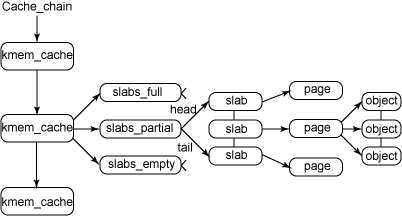
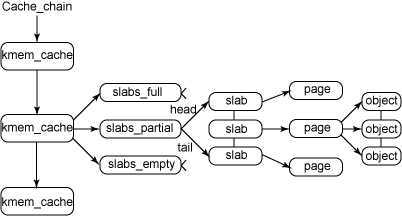
在最高层是 cache_chain,这是一个 slab 缓存的链接列表。可以用来查找最适合所需要的分配大小的缓存。cache_chain 的每个元素都是一个 kmem_cache 结构的引用。一个kmem_cache中的所有object大小都相同。这里我们首先看看缓存描述符中各个域以及他们的含义。
struct kmem_cache_s{ struct kmen_list3 lists; //lists域中包含三个链表头,每个链表头均对应了slab所处的三种状态(满,未满,空闲)之一, unsigned int objsize; //objsize域中持有缓存中对象的大小 unsigned int flags; //flags持有标志掩码,其描述了缓存固有特性 unsigned int num; //num域中持有缓存中每个slab所包含的对象数目 unsigned int gfporder; //缓存中每个slab所占连续页面数的幂,该值默认0 size_t color; unsigned int color_off; unsigned int color_next; kmem_cache_t *slabp_cache; //可存储在自身缓存中也可以存在外部其他缓存中 unsigned int dflags; void (*ctor) (void *,kmem_cache_t*,unsigened long); void (*dtor)(void*,kmem_cache_t *,unsigend long); const char *name; //name持有易于理解的名称 struct list_head next; //next域指向下个单向缓存描述符链表上的缓存描述符 };
如我们所讲,作为通用目的的缓存大小都是被定义好的,且成对出现,一个为从DMA内存分配对象,另一个从普通内存中分配,结构cache_sizes包含了有关通用缓存大小的所有信息。代码解释如下:
struct cache_sizes{ size_t cs_size; //持有该缓存中容纳的内存对象大小 kmem_cache_t *cs_cachep; //持有指向普通内存缓存描述符飞指针 kmem_cache_t *cs_dmacachep; //持有指向DMA内存缓存描述符的指针,分配自ZONE_DMA };
最后介绍一下Slab状态和描述符域的值,如下表(N=slab中的对象数目,X=某一变量的正数)
| Free | Partial | Full | |
| Slab->inuse | 0 | X | N |
| Slab->free | 0 | X | N |
现在我们再内核运行的整个生命周期范围内观察缓存和slab分配器第如何交互的,内核需要某些特殊结构以支持进程的内存请求和动态可加载模块来创建特定缓存,内核函数 kmem_cache_create 用来创建一个新缓存。这通常是在内核初始化时执行的,或者在首次加载内核模块时执行.
struct kmem_cache *kmem_cache_create ( const char *name, //定义了缓存名称 size_t size, //指定了为这个缓存创建的对象的大小 size_t align, //定义了每个对象必需的对齐。 unsigned long flags, //指定了为缓存启用的选项 void (*ctor)(void *)) //定义了一个可选的对象构造器和析构器。构造器和析构器是用户提供的回调函数。当从缓存中分配新对象时,可以通过构造器进行初始化。
当缓存被创建之后,其中的slab都是空的,事实上slab在请求对象前都不会分配,当我们在创建slab时,不仅仅分配和初始化其描述符,而且还需要和伙伴系统交互请求页面。从一个命名的缓存中分配一个对象,可以使用 kmem_cache_alloc 函数,这个函数从缓存中返回一个对象。注意如果缓存目前为空,那么这个函数就会调用 cache_alloc_refill 向缓存中增加内存。
void kmem_cache_alloc( struct kmem_cache *cachep, gfp_t flags );
//cachep是需要扩充的缓存描述符
//flags这些标志将用于创建slab
缓存和slab都可被销毁,其步骤与创建相逆,但是对齐问题在销毁缓存时候不需要关心,只需要删除缓存描述符和释放内存即可,其步骤有三如下:
mm/slab.c int kmem_cache_destroy(kmem_cache_t *cachep) { int i; if(!cache || in_interrupt()) BUG(); //完成健全性检查 down(&cache_chain_sem); list_del(&cachep->next); up(&cache_chain_sem); //获得cache_chain信号量从缓存中删除指定缓存,释放cache_chain信号量 if(_cache_shrink(cachep)){ slab_error(cachep,"Can‘t free all objects"); down(&cache_chain_sem); list_add(&cache->next,&cache_chain); up(&cache_chain_sem); return 1; //该段负责释放为使用slab } ... kmem_cache_free(&cache_cache,cachep); //释放缓存描述符 return 0; }
目前为止,我们讨论完了slab分配器,那么实际的内存请求是怎么样的呢,slab分配器是如何被调用的呢?这里我粗略讲解一下。当内核必须获得字节大小的内存块时,就需要使用函数kmalloc(),它实际上会调用函数kmem_getpages完成实际分配,调用路径如下:kmalloc()->__cache_alloc()->kmem_cache_grow()->kmem_getpages().kmalloc和get_free_page申请的内存位于物理内存映射区域,而且在物理上也是连续的,它们与真实的物理地址只有一个固定的偏移,因此存在较简单的转换关系,virt_to_phys()可以实现内核虚拟地址转化为物理地址:
1 #define __pa(x) ((unsigned long)(x)-PAGE_OFFSET) 2 extern inline unsigned long virt_to_phys(volatile void * address) 3 { 4 return __pa(address); 5 }
那么内核是如何管理它们使用内存的呢,用户进程一旦创建便要分配一个虚拟地址空间,其地址范围可以通过增加或者删除线性地址间隔得以扩大或者缩减,在内核中进程地址空间的所有信息都被保存在mm_struct结构中,mm_struct和vm_area_struct结构之间的关系如下图:
struct mm_struct { struct vm_area_struct * mmap; /* 指向虚拟区间(VMA)链表 */ rb_root_t mm_rb; /*指向red_black树*/ struct vm_area_struct * mmap_cache; /* 指向最近找到的虚拟区间*/ pgd_t * pgd; /*指向进程的页目录*/ atomic_t mm_users; /* 用户空间中的有多少用户*/ atomic_t mm_count; /* 对"struct mm_struct"有多少引用*/ int map_count; /* 虚拟区间的个数*/ struct rw_semaphore mmap_sem; spinlock_t page_table_lock; /* 保护任务页表和 mm->rss */ struct list_head mmlist; /*所有活动(active)mm的链表 */ unsigned long start_code, end_code, start_data, end_data; /*start_code 代码段起始地址,end_code 代码段结束地址,start_data 数据段起始地址, start_end 数据段结束地址*/ unsigned long start_brk, brk, start_stack; /*start_brk 和brk记录有关堆的信息, start_brk是用户虚拟地址空间初始化时,堆的结束地址, brk 是当前堆的结束地址, start_stack 是栈的起始地址*/ unsigned long arg_start, arg_end, env_start, env_end; /*arg_start 参数段的起始地址, arg_end 参数段的结束地址, env_start 环境段的起始地址, env_end 环境段的结束地址*/ unsigned long rss, total_vm, locked_vm; unsigned long def_flags; unsigned long cpu_vm_mask; unsigned long swap_address; .... };
最后简单讲一下进程映象分布于线性地址空间的相关重点,当用户程序被载入内存之后,便被赋予 了自己的线性空间,并且被映射到进程地址空间,下面需要注意。
永久映射:可能会阻塞
映射一个给定的page结构到内核地址空间:
void *kmap(struct page *page)
解除映射:
void kunmap(struct page *page)
临时映射:不会阻塞
void *kmap_atomic(struct page *page)
小结
这次讲了内存管理的大部分内容,介绍了页是如何在内核中被跟踪,然后讨论了内存区,之后讨论了小于一页的小块内存分配,即slab分配器管理。在内核管理结构和众多代码分析完了之后,继续讨论了用户空间进程管理特殊方式,最后简单介绍了进程映象分布于线性地址空间的相关重点。里面肯定有些内容比较散乱,代码有补全的状况,希望大家能够多家批评改正,一起讨论,今天发生了很多事情,到现在才更新完,晚上还有些时间,还需要好好理解体会,共勉。
版权所有,转载请注明转载地址:http://www.cnblogs.com/lihuidashen/p/4242645.html
标签:
原文地址:http://www.cnblogs.com/lihuidashen/p/4242645.html