标签:style c class blog code java
最近看了些node.js方面的知识,就像拿它来做些什么。因为自己喜欢摄影,经常上蜂鸟网,所以寻思了一下,干脆做个简单的爬虫来扒论坛的帖子。
直接上代码吧。

1 var sys = require("sys"), 2 http = require("http"), 3 fs = require("fs"); 4 var url = "http://newbbs.fengniao.com/forum/forum_125.html"; 5 var data = ""; 6 //创建正则,过滤html 7 var reg = /<div\s*class="recommendSub">\s*<a\s*href="(.*?)"\s*class="pic"\s*title="(.*?)"/g; 8 var result = [], 9 timeStamp = 0; 10 // 创建一个请求 11 var req = http.request(url, function (res) { 12 // 设置显示编码 13 timeStamp = new Date().getTime(); 14 res.setEncoding("utf8"); 15 res.on(‘data‘, function (chunk) { 16 data += chunk; 17 }); 18 // 响应完毕时间出发,输出 data 19 res.on(‘end‘, function () { 20 while (match = reg.exec(data)) { 21 result.push({ 22 title: match[1], 23 url: match[2] 24 }); 25 } 26 writeFile(result); 27 }); 28 }); 29 // 发送请求 30 req.end(); 31 function writeFile(r) { 32 var str = ‘‘; 33 for (var i = 0, _len = r.length; i < _len; i++) { 34 str += r[i].title + ‘\n‘ + r[i].url + ‘\n‘; 35 } 36 //数据拼接结束后,写入s.txt文件 37 fs.writeFile(‘s.txt‘, str, function (err) { 38 if (err) { 39 throw err; 40 } 41 console.log(‘耗时约‘ + Math.ceil((new Date().getTime() - timeStamp) / 1000) + ‘s‘); 42 console.log(‘数据已写入文件‘); 43 }); 44 }
这里比较需要注意的就是正则了,大家要注意贪婪匹配这些要点。
我们把这个js文件命名为spider.js,控制台下运行
node spider.js
后就可以看到s.txt文件生成了,里面就是获取的帖子信息。
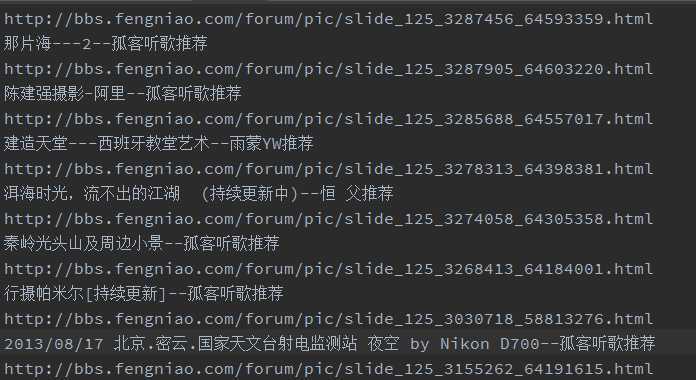
就这样吧,打算抽空好好学学node.js,这家伙还是挺有趣的。
相关的js我同时也上传到了github上,有感兴趣的同学可以clone到本地。
地址:https://github.com/kbqncf/spider
使用node.js制作简易爬虫,布布扣,bubuko.com
标签:style c class blog code java
原文地址:http://www.cnblogs.com/kbqncf/p/3754857.html