标签:
原文地址:http://www.cnblogs.com/MikeZhang/archive/2012/03/24/MySplitFunCPP.html
这篇文章总结的很好,原文出自上面的地址。
一、用strtok函数进行字符串分割
原型: char *strtok(char *str, const char *delim);
功能:分解字符串为一组字符串。
参数说明:str为要分解的字符串,delim为分隔符字符串。
返回值:从str开头开始的一个个被分割的串。当没有被分割的串时则返回NULL。
其它:strtok函数线程不安全,可以使用strtok_r替代。
示例:

1 //借助strtok实现split
2 #include <string.h>
3 #include <stdio.h>
4
5 int main()
6 {
7 char s[] = "Golden Global View,disk * desk";
8 const char *d = " ,*";
9 char *p;
10 p = strtok(s,d);
11 while(p)
12 {
13 printf("%s\n",p);
14 p=strtok(NULL,d);
15 }
16
17 return 0;
18 }
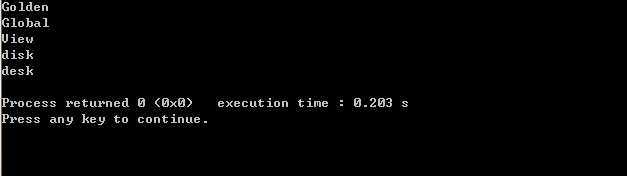
运行效果:
二、用STL进行字符串的分割
涉及到string类的两个函数find和substr: 1、find函数 原型:size_t find ( const string& str, size_t pos = 0 ) const; 功能:查找子字符串第一次出现的位置。 参数说明:str为子字符串,pos为初始查找位置。 返回值:找到的话返回第一次出现的位置,否则返回string::npos
2、substr函数 原型:string substr ( size_t pos = 0, size_t n = npos ) const; 功能:获得子字符串。 参数说明:pos为起始位置(默认为0),n为结束位置(默认为npos) 返回值:子字符串
实现如下:
1 //字符串分割函数 2 std::vector<std::string> split(std::string str,std::string pattern) 3 { 4 std::string::size_type pos; 5 std::vector<std::string> result; 6 str+=pattern;//扩展字符串以方便操作 7 int size=str.size(); 8 9 for(int i=0; i<size; i++) 10 { 11 pos=str.find(pattern,i); 12 if(pos<size) 13 { 14 std::string s=str.substr(i,pos-i); 15 result.push_back(s); 16 i=pos+pattern.size()-1; 17 } 18 } 19 return result; 20 }
完整代码:
1 /* 2 File : split1.cpp 3 Author : Mike 4 E-Mail : Mike_Zhang@live.com 5 */ 6 #include <iostream> 7 #include <string> 8 #include <vector> 9 10 //字符串分割函数 11 std::vector<std::string> split(std::string str,std::string pattern) 12 { 13 std::string::size_type pos; 14 std::vector<std::string> result; 15 str+=pattern;//扩展字符串以方便操作 16 int size=str.size(); 17 18 for(int i=0; i<size; i++) 19 { 20 pos=str.find(pattern,i); 21 if(pos<size) 22 { 23 std::string s=str.substr(i,pos-i); 24 result.push_back(s); 25 i=pos+pattern.size()-1; 26 } 27 } 28 return result; 29 } 30 31 int main() 32 { 33 std::string str; 34 std::cout<<"Please input str:"<<std::endl; 35 //std::cin>>str; 36 getline(std::cin,str); 37 std::string pattern; 38 std::cout<<"Please input pattern:"<<std::endl; 39 //std::cin>>pattern; 40 getline(std::cin,pattern);//用于获取含空格的字符串 41 std::vector<std::string> result=split(str,pattern); 42 std::cout<<"The result:"<<std::endl; 43 for(int i=0; i<result.size(); i++) 44 { 45 std::cout<<result[i]<<std::endl; 46 } 47 48 std::cin.get(); 49 std::cin.get(); 50 return 0; 51 }
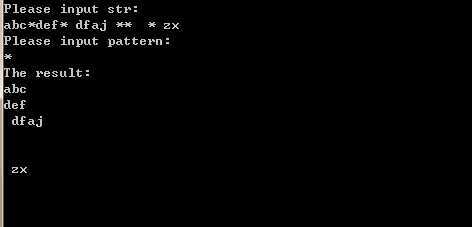
运行效果:
三、用Boost进行字符串的分割
用boost库的正则表达式实现字符串分割 实现如下:
1 std::vector<std::string> split(std::string str,std::string s) 2 { 3 boost::regex reg(s.c_str()); 4 std::vector<std::string> vec; 5 boost::sregex_token_iterator it(str.begin(),str.end(),reg,-1); 6 boost::sregex_token_iterator end; 7 while(it!=end) 8 { 9 vec.push_back(*it++); 10 } 11 return vec; 12 }
完整代码:
1 //本程序实现的是利用正则表达式对字符串实现分割 2 //运行环境 VC6.0 + boost 库 3 /* 4 File : split2.cpp 5 Author : Mike 6 E-Mail : Mike_Zhang@live.com 7 */ 8 #include <iostream> 9 #include <cassert> 10 #include <vector> 11 #include <string> 12 #include "boost/regex.hpp" 13 14 std::vector<std::string> split(std::string str,std::string s) 15 { 16 boost::regex reg(s.c_str()); 17 std::vector<std::string> vec; 18 boost::sregex_token_iterator it(str.begin(),str.end(),reg,-1); 19 boost::sregex_token_iterator end; 20 while(it!=end) 21 { 22 vec.push_back(*it++); 23 } 24 return vec; 25 } 26 int main() 27 { 28 std::string str,s; 29 str="sss/ddd/ggg/hh"; 30 s="/"; 31 std::vector<std::string> vec=split(str,s); 32 for(int i=0,size=vec.size();i<size;i++) 33 { 34 std::cout<<vec[i]<<std::endl; 35 } 36 std::cin.get(); 37 std::cin.get(); 38 return 0; 39 }
运行效果:

补充:
最近发现boost里面有自带的split的函数,如果用boost的话,还是直接用split的好,这里就不多说了,代码如下:
1 #include <iostream> 2 #include <string> 3 #include <vector> 4 #include <boost/algorithm/string/classification.hpp> 5 #include <boost/algorithm/string/split.hpp> 6 7 using namespace std; 8 9 int main() 10 { 11 string s = "sss/ddd,ggg"; 12 vector<string> vStr; 13 boost::split( vStr, s, boost::is_any_of( ",/" ), boost::token_compress_on ); 14 for( vector<string>::iterator it = vStr.begin(); it != vStr.end(); ++ it ) 15 cout << *it << endl; 16 return 0; 17 }
标签:
原文地址:http://www.cnblogs.com/elitiwin/p/4249848.html