首先堆栈和堆(托管堆)都在进程的虚拟内存中。(在32位处理器上每个进程的虚拟内存为4GB)
堆栈stack
1、堆栈中存储值类型
2、堆栈实际上是向下填充,即由高内存地址指向低内存地址填充
3、堆栈的工作方式是先分配内存的变量后释放(先进后出原则)
4、堆栈中的变量是从下向上释放,这样就保证了堆栈中先进后出的规则不与变量的生命周期起冲突
5、堆栈的性能非常高,但是对于所有的变量来说还不灵活,而且变量的生命周期必须嵌套。
6、通常我们希望使用一种方法分配内存来存储数据,并且方法退出后很长一段时间内数据仍然可以使用。此时我们就用到了堆(托管堆)
堆(托管堆)heap
堆(托管堆)存储引用类型
此堆非彼堆,.net中的堆有垃圾收集器自动管理
与堆栈不同,堆是从下往上分配,所以自由的空间都已用空间的上面
比如创建一个对象:
customer cus;
cus=new customer();
申明一个customer的引用cus,在堆栈上给这个引用分配存储空间。这仅仅只是一个引用,不是实际的customer对象!
cus占4个字节的空间,包含了存储customer的引用地址。
接着分配堆上的内存以存储customer对象的实例,假定customer对象的实例是32字节,为了在堆上找到一个存储customer对象的存储位置。
.net运行库在堆中搜索第一个从未使用的,32字节的连续块存储customer对象的实例!
然后把分配给customer对象实例的地址给cus变量!
从这个例子中可以看出,建立对象引用的过程比建立值变量的过程复杂,且不能避免性能的降低!
实际上就是.net运行库保存对状态信息,在堆中添加新数据时,堆栈中引用变量也要更新。性能上损失很多!
有种机制在分配变量内存的时候,不会受到堆栈的限制:把一个引用变量的值赋给一个相同类型的变量,那么这两个变量就引用一个堆中的对象。
当一个应用变量出作用于域时,它会从堆栈中删除,但引用对象的数据仍热保留在堆中,一直到程序结束或者该数据不被任何变量应用时,垃圾收集器会删除它。
——————————————————————————————————————————
装箱转换
using System;
class Boxing
{
public static void Main()
{
int i=0;
object obj=i;
i=220;
Console.WriteLine("i={0},obj={1}",i,obj);
obj=330;
Console.WriteLine("i={0},obj={1}",i,obj);
}
}
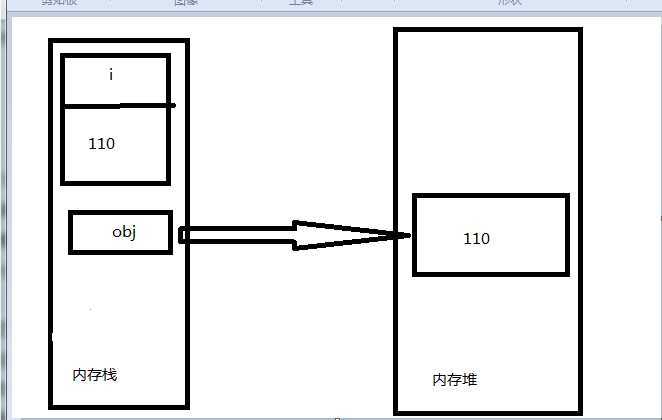
定义整形类型变量i的时候,这个变量占用的内存是内存栈中分配的,第二句是装箱操作将变量110存放到了内存堆中,而定义object对象类型的变量obj则在内存栈中,并指向int类型的数值为110,而该数值是付给变量i的数值副本。
所以运行结果是:
i=220,obj=110
i=220,obj=330
内存格局通常分为四个区
1、全局数据区:存放全局变量,静态数据,常量
2、代码区:存放所有的程序代码
3、栈区:存放为运行而分配的局部变量,参数、返回数据,返回地址等,
4、堆区:即自由存储区
值类型区分两种不同的内存区域:线程堆栈(Thread Stack)和托管堆(Manged Heap)。
每个正在运行的程序都对应着一个进程(process),在一个进程内部,可以有一个或者多个线程(thread),
每个线程都拥有一块“自留地”,称为“线程堆栈”,大小为1M,用于保存自身的一些数据,比如函数中自定义的局部变量、函数调用时传送的参数值等,这部分内存域与回收不需要程序员干涉。
所有值类型的变量都是在线程堆栈中分配的。
另一块内存区域称为“堆(heap)”,在.Net这种托管环境下,堆由CLR进行管理,所以又称为“托管堆(manged heap)”。
用new 关键字创建的类的对象时,分配给对象的内存单元就位于托管堆中。
在程序中我们可以随意的使用new关键字创建多个对象,因此,托管堆中的内存资源是可以动态申请并使用的,当然用完了必须归还。
打个比方更容易理解:托管堆相当于一个旅馆,其中房间相当于托管堆中所拥有的内存单元。当程序员用new方法去创建对象时,相当于游客向旅馆预订房间,旅馆管理员会先看一下有没有合适的房间,有的话,就可以将此房间提供给游客住宿,要办理退房手续,房间又可以为其他游客提供服务了。
引用类型共有四种:类类型、接口类型、数组类型和委托类型。
所有引用类型变量所引用的对象,其内存都是在托管堆中分配的。
严格地说,我们常说的“对象变量”其实是类类型的引用变量。但在实际人们经常将引用类型的变量简称为“对象变量”,用它来指代所有四种类型的引用变量。在不致于引起混淆的情况下,我们也这么认为
在理解了对象内存模型之后,对象变量之间的相互赋值的含义也就清楚了。请看一下代码:
class A
{
public int i;
}
class Program
{
A a;
a=new A();
a.i=100;
A b=null;
b=a; //对象变量的相互赋值
Console.WriteLine("b.i="+b.i); //b.i=?
}
注意第12和13句。
程序的运行结果是:
b.i=100;
事实上,两个对象变量的相互赋值意味着赋值后两个对象变量所占有的内存单元其内容是相同的。
详细一些:
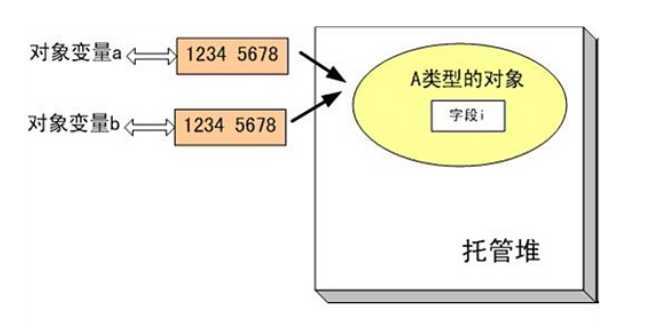
当创建对象以后,其首地址(假设为“1234 5678”)被放入到变量a自身的4个字节的内存单元中。
有定义了一个对象变量b,其值最初为null(即对应的4个字节内存单元中为“0000 0000”)
a变量的值被复制到b的内存单元中,现在,b内存单元的值也为“1234 5678”
根据上面介绍的对象内存模型,我们知道现在变量a和b都指向同一个实例对象。
如果通过b.i修改字段i的值,a.i也会同步变化,因为a.i与b.i其实代表同一对象的统一字段。
如上图
由此得到一个重要结论:
对象变量的互相赋值不会导致对象自身被复制,其结果是两个对象变量指向同一个对象。
另外,由于对象变量本身是一个局部变量,因此,对象本身是位于线程堆栈中的。
严格区分对象变量于对象变量所引用的对象,是面向对象编程的关键技术之一。
由于对象变量类似于一个对象指针,这就产生了“判断两个对象变量是否引用用一个对象”的问题
c#使用“==”运算符对比两个对象变量是否引用同一个对象,“!=”比对两个对象变量是否引用不同的对象。
A a1=new A();
A a2=new A();
Console.WriteLine(a1==a2);//输出:false
a2=a1;//a1和a2引用相同的对象
Console.WriteLine(a1==a2);//输出 true
需要注意的是,如果“==”被用到值类型的变量之间,则比对的变量的内容:
int i=0;
int j=100;
if(i==j)
{
Console.WriteLine("i与j的值相等");
}
理解值类型与引用类型的区别在面向对象编程中非常关键。
1、类型,对象,堆栈和托管堆
c#的类型和对象在应用计算机内存时,大体用到了两种内存,一个叫堆栈,另一个叫托管堆,下面我们用直接长方形表示堆栈,用圆角长方形来代表托管堆。

先举个例子,有如下两个方法,Method_1和Add,分别如下:
public void Method_1()
{
int value1=10; //1
int value2=20;//2
int value3=Add(value,value);//3
}
public int Add(int n1,int n2) //4
{
int sum=n1+n2;//5
return sum;//6
}
这段代码执行,用图表示为为:

上图基本对应程序中的每个步骤。在执行Method_1的时候,先把value1压入堆栈顶部,然后是value2,接着下面的调用方法Add,因为方法有两个参数是n1和n2,所以把n1和n2分别压入堆栈,因为此处调用了一个方法,并且方法有返回值,所以这里需要保存Add的返回地址,然后进入Add方法内部,在Add内部,首先给sum赋值,所以把sum压入栈顶,然后用return返回,此时,返回的返回地址就起到了作用,return会根据地址返回回去,在返回的过程中,把sum推出栈顶,找到了返回地址,但在Method_1方法中,我们希望把Add的返回值赋给Value3,此时的返回地址也被推出堆栈,把value2压入堆栈。
虽然这个例子的结果没大用途,但这个例子很好的说明方法被执行时,变量在进出堆栈的情况。这里也能看出为什么方法内部局部变量用过之后,不能在其他方法中访问的原因。
下面我们讨论一下类和对象在托管堆和堆栈中的情况。
先看一下代码:
class Car
{
public void Run()
{
Console.WriteLine("一切正常");
}
public virtual double GetPrice()
{
return 0;
}
public static void Purpose()
{
console.WtriteLine("载入");
}
}
class BMW:Car
{
public override double GetPrice()
{
return 80000;
}
}
上面是两个类,一个Father一个son,son继承了Father,因为你类中有一个virtual的BuyHouse方法,所以son类可以重写这个方法。
下面接着看调用代码。
public void Method_A()
{
double CarPrice;//1
Car car=new BMW();//2
CarPrice=car.GetPrice();//调用虚方法(其实调用的是重写后的方法)
car.Run();//调用实例化方法
car.Purpose();//调用静态方法
}
这个方法也比较简单,就是定义一个变量用来获得价格,同时定义了一个父类的变量,用子类来实例化它
接下来,我们来分步骤说明:
看一下运行时堆栈和托管堆的情况:
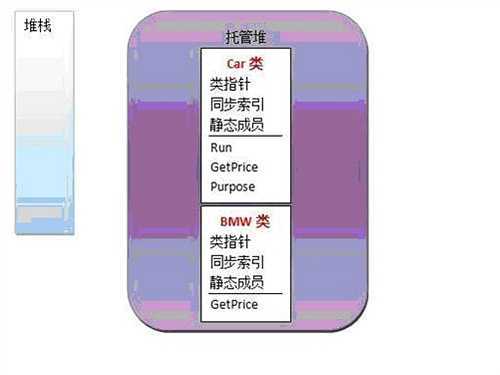
这里需要说明的是,类是位于托管堆中的,这个类有分为四个类部,用来关联对象;同步索引,引用完成同步(比如线程同步)需要建立的,静态成员是属于类的,所以在类中出现,还有一个方法列表(这里的方法列表项与具体的方法对应)。
当Mehod_A方法的第一执行时:
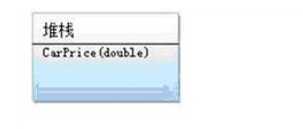
这时的CarPrice是没有值得
当Method_A方法执行到第二步,其实第二步又可以分成
Car car;
car=new BWM();
先看Car

car在这里是一个方法内部的变量,所以被压力到堆栈中。
在看car =new BWM();
这是一个实例化过程,car变成了一个对象
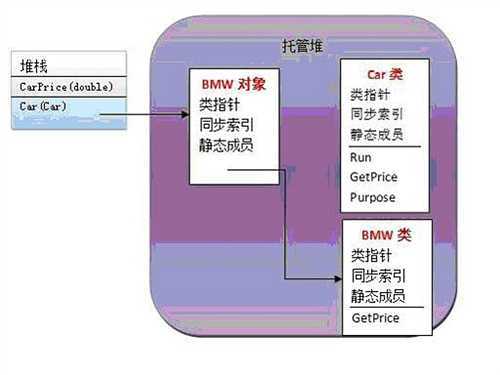
这里是用子类来实例化父类类型。对象其实是子类的类型的,但变量的类型的父类的。
接下来,在Method_A中的调用的中调用car.GetPrice(),对于car来说,这个方法是虚方法(并且子类重写了它),虚方法在调用是不会执行类型上的方法,即不会执行car类中的虚方法,而是执行对象对应类的上的方法,即BWM中的GtPrice.如果Method_A中执行方法Run()因为Run是普通实例方法,所以执行car类中的Run方法。
如果调用了Method_A的Prupose方法,即不用变量car调用,也不用对象调用,而使类名Car调用,因为静态方法会在类中分配内存中。如果用Car生成多个实例,静态成员只有一份,就是在类中,而不是在对象中。
-------------------------------------------------------------------------------------------------------
在32位的window操作系统中,每个进程都可以用4GB的内存,这得益于虚拟寻址技术,在这4GB的内存中存储这可执行代码、代码加载的DLL和程序运行的所有变量,在c#中,虚拟内存中有个两个存储变量区域,一个称为堆栈,一个称为托管堆,托管堆的出现是.net不同于其他语言的地方,堆栈存储值类型数据,而托管堆栈存储引用类型如类、对象,并受垃圾回收集器的控制和管理。在堆栈中,一旦变量超出使用范围,其使用的内存空间会被其他变量重新使用,这时其空间存储的值被其他变量覆盖而不复存在,但有时候我们希望有些值仍然存在,这需要托管堆来实现,我们用几段代码来说明其工作原理,假设已经定义了一个类class:
class1 object1;
object1=new class1();
第一句定义了一个class1的引用,实质上只是在堆栈中分配一个4个字节的空间,它将用来存储后来实例化对象在托管堆中的地址,在windows中这需要4个字节来表示内存地址。第二句实例化object1对象,实际上是在托管堆中开辟了一个内存空间来存储类class1的一个具体对象,假设这个对象需要36个字节,那么object1指向的实际上是在托管推一个大小为36字节的连续内存空间开始地址,当对象不再使用时,这个被存储在堆栈中引用变量将被删除,但是从上述机制中可以看出,在托管堆中这个引用指向的对象仍然存在,其空间何时被释放取决垃圾收集器而不是引用变量失去作用域时。
在使用电脑的过程中大家可以都有过这种经验,电脑用久了以后程序会变得越来越慢,其中一个重要的原因就就系统存在中大量内存碎片,就是因为程序反复在堆栈中创建和释放变量,久而久之可用变量在内存中将不再是连续的内存空间,为了寻址这些变量也会增加系统开销。在.net中这种类型将得到很大改善,这是因为有了垃圾回收集器的工作,垃圾收集器将会压缩托管堆的内存空间,保证可用变量在一个连续的内存空间中,同时将堆栈中引用变量中的地址改为新的地址,这将会带来额外的系统开销,但是,其带来的好处会抵消这种影响,而另外的一个好处是,程序员将不再花上大量的心思在内存泄露问题上。
当然,以c#程序中不仅仅只有引用类型的变量,仍然存在值类型和其他托管堆不能管理的对象,如果文件名柄、网络连接和数据库连接,这些变量的释放仍然需要程序员通过析构函数或者IDispose接口来做。
另一方面,在某些时候c#程序需要追求速度,比如对一个含有大量成员的数组的操作,如仍使用传统的类来操作,将不会得到很好的性能,因为数组在c#中实际是System.Array的实例,会存储在托管堆中,这将会对运算造成大量的额外的操作,因为除了垃圾收集器除了会压缩托管堆、更新引用地址,还会维护托管堆的信息列表。所幸的是c#中同样能够通过不安全代码使用c++程序员通常喜欢的方式来编码,在标记为unsafe的代码块使用指针,这和在c++中使用指针没有什么不同,变量也是存在堆栈中,在这种情况下声明一个数组可以使用stacklloc语法,比如声明一个存储有50个double类型的数组:
double* pDouble=stackalloc double[50]
stackalloc会给pDouble数组在堆栈中分配50个double类型大小的内存空间,可以使用pDouble[0]、*(pDouble+1)这种方式操作数组,与在c++中一样,使用指针必须知道自己在做什么,确保访问的正确的内存空间,否则会出现无法预料的错误。
进程中每个线程都有自己的堆栈,这是一段线程创建时保留下的地址区域。我们的“栈内存”即在此。至于“堆”内存,我个人认为在未使用new定义时,堆应该就是未“保留”为“提交”的自由空间,new的功能是在这些自由空间中保留出一个地址范围
栈(stack)是操作系统在建立某个进程时或者线程(在支持多线程的操作系统中是线程)为这个线程的存储区域,该区域具有FIFO的特性,在编译的时候可以指定需要的Stack的大小。在编程中,例如c/c++中,所有的局部变量都是从栈中分配内存空间,实际上也不是什么都分配,只是从栈顶向上用就行,在推出函数的时候,只修改栈指针就可以把栈中的内容销毁,所以速度最快。
堆(Heap)是应用程序在运行的时候请求操作系统给自己内存,一般是申请/给予的过程,c/c++分别用malloc/New请求分配Heap,用free/delete销毁内存。由于从操作系统管理的内存分配所以在分配和销毁时都要占用时间,所以堆的效率要低的多!,但是堆的好处是可以做的很大,c/c++堆分配的Heap是不初始化的。
在Java中除了简单类型(int,char等)都是在堆中分配内存,这也是程序慢的一个主要原因。但是跟C/C++不同,Java中分配Heap内存是自动初始化的。在Java中所有的对象(包括int的wrapper Integer)都是在堆中分配的,但是这个对象的引用却是在Stack中分配。也就是说在建立一个对象时从两个地方都分配内存,在Heap中分配的内存实际建立这个对象,而在Stack中分配的内存只是一个指向这个堆对象的指针(引用)而已。
在.NET的所有技术中,最具争议的恐怕是垃圾收集(Garbage Collection,GC)了。作为.NET框架中一个重要的部分,托管堆和垃圾收集机制对我们中的大部分人来说是陌生的概念。在这篇文章中将要讨论托管堆,和你将从中得到怎样的好处。
spring事务管理器设计思想(一),布布扣,bubuko.com
原文地址:http://www.cnblogs.com/isoftware/p/3758013.html