标签:
这一篇再说下索引的最后一个主题,索引覆盖,当然学习比较好的捷径是看看那些大师们设计的索引,看从中能提取些什么营养的东西,下面我们看
看数据库中一个核心的Orders表。
一:查看表的架构
<1> 先查看这个表的大概架构信息
1 --查看表的架构信息 2 SELECT c.column_id,c.name,t.name FROM sys.columns AS c 3 JOIN sys.types t 4 ON c.system_type_id=t.system_type_id 5 WHERE c.object_id=object_id(‘O_Orders‘) 6 ORDER BY c.column_id
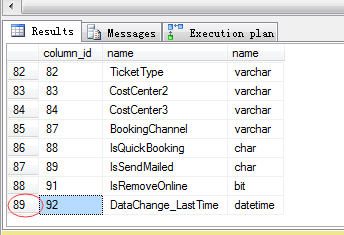
从这个订单表来看大概有89个字段。。。还是蛮多的,可能有太多的历史原因吧,下面就有一个疑问来了,针对这么多的字段加上五花八门的类型,如何规划
好单列索引和复合索引。。。下面我们来看看这些专家们怎么设计的。
<2> 复合索引
首先声明一下,由于我的权限有限,不能进行DBCC IND,PAGE等命令,所以我没有能力判断下面的索引是include索引还是复合索引,所以这里统一叫成
复合索引吧。
1 SELECT name,type_desc FROM sys.indexes WHERE object_id=object_id(‘O_Orders‘)
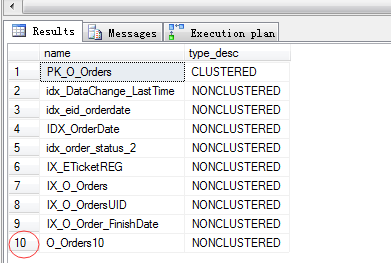
从上面可以看到,有9个非聚集索引,1个聚集索引,然后可以通过 SHOW_STATISTICS 抽查几个索引看看到底关联了哪些字段,找到其中的二个索引,
覆盖多达6列,如索引"idx_order_status_2","IX_O_OrdersUID"。
DBCC SHOW_STATISTICS(O_Orders,idx_order_status_2) DBCC SHOW_STATISTICS(O_Orders,IX_O_OrdersUID)
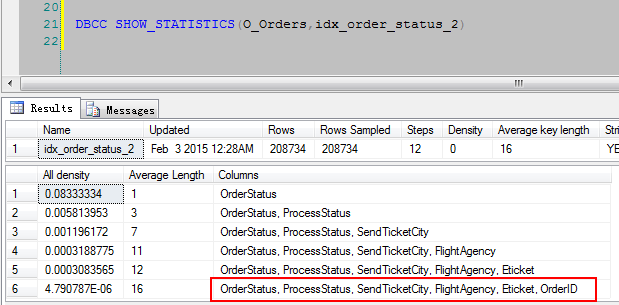
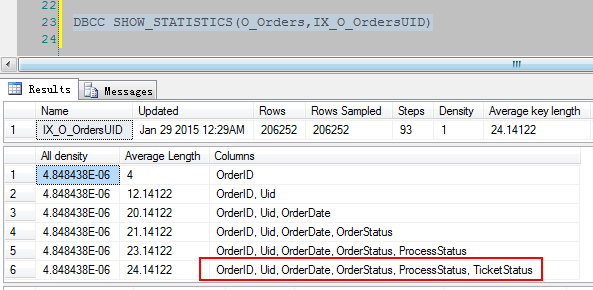
从这两个索引中关联的字段大概可以看出两点信息:
①:这些字段都比较小,为char(1),smallint,bit这样的,自然表示的状态会比较少。
②:将表中多个状态少的字段挑选几个按照访问频率组合在一起做一个索引。
但是仔细想想,虽然原则上说状态少的字段不合适建索引,但是类似“订单状态(OrderStatus”这种字段,肯定是一个被频繁查询的列。。。既然是频繁的列,
肯定就要想办法优化,方法就是建复合索引,这样在复杂的sql中更加容易被撞上索引覆盖。
比如下面这样:
1 SET STATISTICS IO ON 2 SELECT OrderStatus, ProcessStatus, SendTicketCity, FlightAgency, Eticket, OrderID 3 FROM dbo.Orders WHERE OrderStatus=‘P‘ AND ProcessStatus=‘1‘ AND SendTicketCity=1
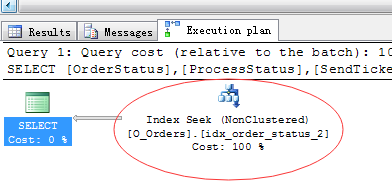
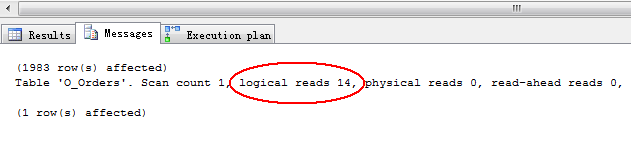
然后继续挑选几个索引瞄一瞄。。。一般来说,覆盖1到2个列的索引都叫小索引。
1 DBCC SHOW_STATISTICS(O_Orders,idx_eid_orderdate) 2 DBCC SHOW_STATISTICS(O_Orders,IX_O_Order_FinishDate)
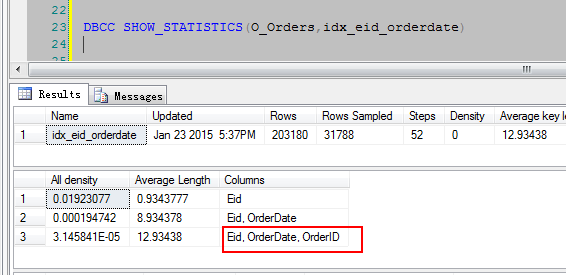
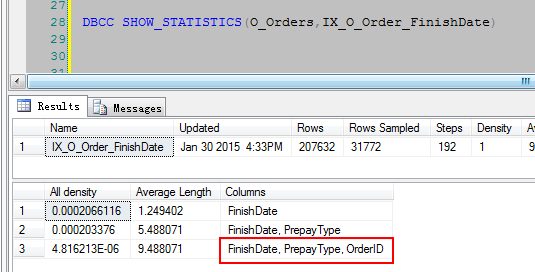
通过上面的索引大概可以看到,Eid和FinishDate这两列,一眼扫过就知道应该是一个唯一性比较高的列了,至于为什么要覆盖2列,那这个就是根据业务
和生产的滚动数据来决定了,那这样的索引有什么好处呢?同样更容易会撞到索引链接,也就是多条件中会走到多个索引,每个索引中贡献一些列刚好可以
满足select中的所有列。。。比如下面这样。
1 -- 可以看到,select中的所有列都是有idx_eid_orderdate 和 IX_O_Order_FinishDate 贡献 2 SELECT OrderID,FinishDate,PrepayType,Eid,OrderDate 3 FROM dbo.O_Orders WHERE Eid=‘cctv1‘ AND FinishDate>2015-1-1
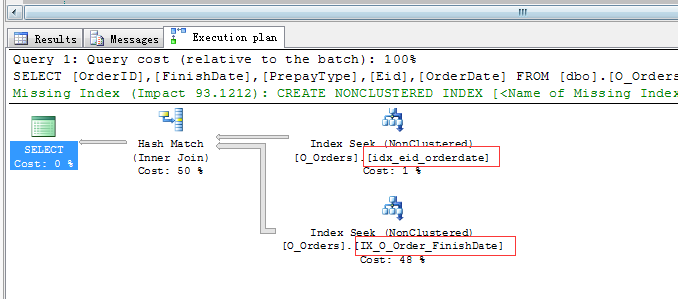
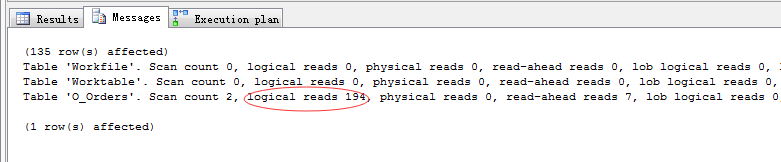
好了,就像园友说的,索引就是拆东墙补西墙,每建一个索引都需要评估它的利弊。
Sql Server之旅——第九站 看公司这些DBA们设计的这些复合索引
标签:
原文地址:http://www.cnblogs.com/huangxincheng/p/4269891.html