标签:
搜索引擎的结果取决于两组信息:网页的质量信息,这个查询与每个网页的相关性信息。这里,我们介绍前一个。
1.PageRank算法原理
算法的原理很简单,在互联网上,如果一个网页被很多其他网页所链接,说明它收到普遍的承认和信赖,那么它的排名就高。比如我们要找李开复博士,有100个人举手说自己是李开复,那么谁是真的呢?如果大家都说创新工厂的那个是真的,那么他就是真的。这就是所谓的民主表决。但是,那么多网页,我们不可能一样对待。有些可靠的链接,相应的权重就要大一点。但是麻烦来了,一开始的时候,我们怎么给网页设置初始权重呢?这有点类似“先有鸡还是先有蛋”的问题。破解这个问题的是谷歌的创始人之一:布林。他把问题变成一个二维矩阵相乘的问题,用迭代的方法解决这个问题。他们先假设所有网页的排名相同,然后算出哥哥网页第一次迭代排名,然后根据这个第一次的排名算第二次的....他们从理论上证明了无论初始值如何,这个算法保证网页的排名的估计值能收敛到排名的真实值。且算法不需要人工干预。由于互联网上的网页量很大,在计算矩阵乘法时,谷歌利用稀疏矩阵减少了计算量。并利用MapReduce实现并行计算自动化。
网页排名算法的高明之处在于它把整个互联网当作一个整体来对待。这无意识中符合了系统论的观点。而当时大部分人只注意了网页内容和查询语句,忽略了网页之间的关系,就算发现了,也只是摸到一些皮毛,没有从根本上解决问题。这个算法对当时的搜索结果影响非常大。当时一般的搜索引擎,前十个只有三四个是相关的。而Google能达到七八条。现在的搜索引擎基本都能达到这一点。
2.延伸阅读:PageRank的计算方法
假定向量

为第一、第二、...第N个网页的排名。矩阵

为网页之间连接的数目,amn代表第m个网页指向第n个网页的链接数。A已知,B未知,也是我们要计算的。
假定Bi是第i次迭代的结果,那么Bi = A·Bi-1 (10.3)
初试假设:所有网页的排名都是1/N,即
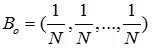
对初试B0不断迭代,我们可以最终得到Bi,且收敛。当Bi和Bi-1的差距非常小时,我们可以停止迭代。
此外,由于网页之间链接数量相比互联网的规模非常稀疏,因此计算网页的排名也需要对零概率或者小概率事件进行平滑处理。公式如下:
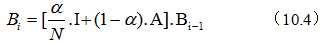
其中N是互联网网页数量,是一个很小的常数,I是单位矩阵。
3.小节
虽然今天的Google搜索比最初复杂、完善了很多,但PageRank算法依然是至关重要的。它在文献检索中的贡献是相当大的。
第十章 PageRank——Google的民主表决式网页排名技术
标签:
原文地址:http://www.cnblogs.com/KingKou/p/4270826.html