今天看到一篇文章介绍2012中的分页,就想测试一下新的分页方法比原先的有多少性能的提升,下面是我的测试过程(2012的分页语法这里不在做多的说明,MSDN上一搜就有):
首先我们来构造测试数据:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33 |
--建表CREATE TABLE [dbo].[MyCustomer]( [id] [int] PRIMARY
KEY, [CustomerNumber] [varchar](25), [CustomerName] [varchar](25), [CustomerCity] [varchar](25))--生成100W测试数据DBCC DROPCLEANBUFFERS DBCC FREEPROCCACHE SET STATISTICS IO ON; SET STATISTICS TIME ON; ;WITH
mycte AS( SELECT
id=1,CustomerNumber=CAST(‘0000‘
AS VARCHAR(25)), CustomerNamer=CAST(‘AAAA‘
AS VARCHAR(25)), CustomerCity=CAST(‘CCCC‘
AS VARCHAR(25)) UNION
ALL SELECT
id=id+1, CustomerNamer=CAST(CHECKSUM(NEWID()) AS
VARCHAR(25)), CustomerNamer=CAST(‘Name‘+CHAR(65+id%26) AS
VARCHAR(25)), CustomerCity=CAST(CHAR(65+id%26) AS
VARCHAR(25)) FROM
mycte WHERE
id<1000000) INSERT
INTO MyCustomer SELECT
* FROM mycteOPTION(MAXRECURSION 0)SET STATISTICS IO OFF ; SET STATISTICS TIME OFF; |
这里我采用CTE的方式来递归构造数据,有兴趣的童鞋可以试试传统的While循环来对比一下两种的区别。接下来我们分别来看下集中常见的分页语句和他们的时间开销情况:
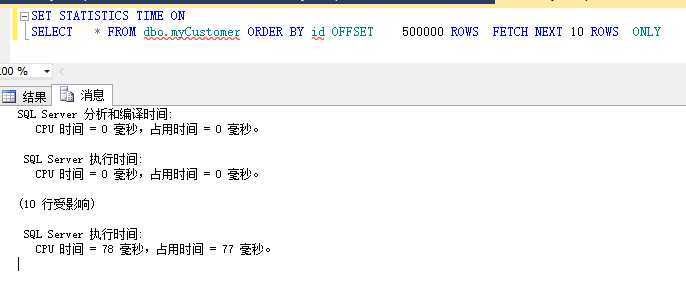
1、2012的分页情况
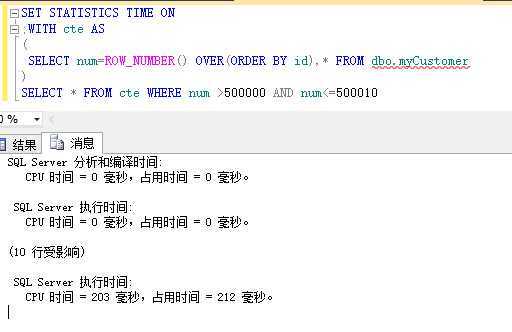
2、05~08的分页情况
3、双ToP N分页的情况
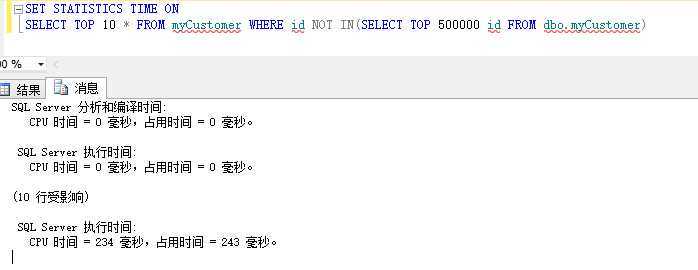
上面的三种分页查询的场景是一致的,都是查询50W后的10条记录,记录总量为100W,我们可以看到,在这种情况下,2012的分页效果是最好的。其余的两种差别不是很大,
当然查询越靠前的记录差别会越小,例如我们若把数据查询的范围缩小到500后的10条,前2种在时间的消耗上已经看不出来区别。有兴趣的童鞋可以对比下3种查询语句的查询计划。查询计划选择和其对应的复杂程度和查询所需的开销是成正比的。
原文地址:http://www.cnblogs.com/mfkaudx/p/3759451.html