标签:
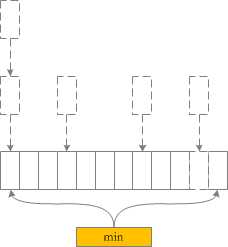
1、在流式计算中经常需要对一批的数据进行汇总计算,类似SQL中的GROUP BY。在用JStorm来实现这一条简单的SQL时,面对的是一条一条的数据库变化的消息(这里需要保证有序消费),其实相当于在一堆的消息上面做了一个嵌套的SQL查询,用一张图表示如下:
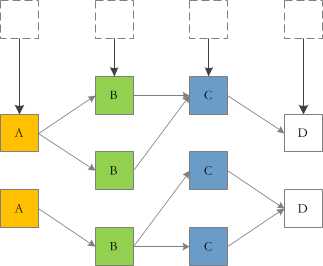
2、业务DB中的表基本上不会有大宽表,也就是说获取数据时需要从把不同的表进行JOIN才能拿到结果,那么现在的问题是在JOIN的多个表中,任意一个表的数据出现变化都可能影响到最终的结果。也就是说在JStorm中需要针对每个表的变化想好应对的方法:
最近看JStorm的接口,在分发消息的部分做了很多策略,我们设计模型的时候可以充分的利用这些策略来规避分布式情况下一些问题:
----- updating -----
标签:
原文地址:http://www.cnblogs.com/antispam/p/4274212.html