标签:
refer: http://sqlblog.com/blogs/paul_white/archive/2012/04/28/query-optimizer-deep-dive-part-1.aspx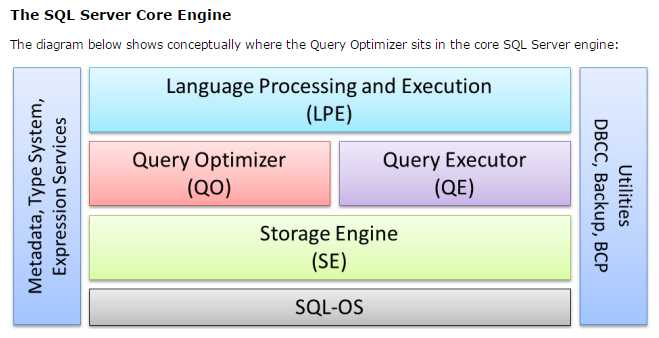


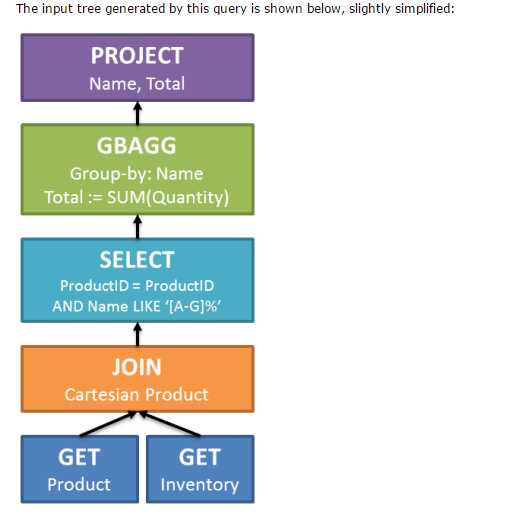
We start by looking at the bound logical tree (input tree). To make the discussion a little less abstract, we will use a test query issued against the AdventureWorks sample database. This simple query shows products and the quantity in stock, limited to products with names that start with a letter between A and G:
-- Test querySELECTp.Name,
Total = SUM(inv.Quantity)FROM Production.Product AS p, Production.ProductInventory AS invWHEREinv.ProductID = p.ProductID
AND p.Name LIKE N‘[A-G]%‘
GROUP BY
p.Name;

The first step of the optimization pipeline we will look at is simplification, where the optimizer looks to rewrite parts of the logical tree to remove redundancies and move logical operations around a bit to help later stages. Major activities that occur around the time simplification occurs (I have taken a little artistic licence here to group a few separate stages together) include:
The optimizer only has direct information about table cardinality (total number of rows) for base tables. Statistics can provide additional histograms and frequency statistics, but again these are only maintained for base tables. To help the optimizer choose between competing strategies later on, it is essential to know how many rows are expected at each node in the logical tree, not just at the GET leaf nodes. In addition, cardinality estimates above the leaves can be used to choose an initial join order (assuming the query contains several joins).
Cardinality estimation computes expected cardinality and distribution statistics for each node, working up from the leaves one node at a time. The logic used to create these derived estimates and statistics uses a model that makes certain assumptions about your data. For example, where the distribution of values is unknown, it is assumed to be uniform across the whole range of potential values.
You will generally get more accurate cardinality estimates if your queries fit the model used, and, as with many things in the wider optimizer, simple and relational is best. Complex expressions, unusual or novel techniques, and using non-relational features often means cardinality estimation has to resort to guessing.
Most of the choices made by the optimizer are driven by cardinality estimation, so if these are wrong, any good execution plans you might see are highly likely to be down to pure luck.
The next stage of the optimizer pipeline is Trivial Plan, which is a fast path to avoid the time and effort involved in full cost-based optimization, and only applies to logical query trees that have a clear and obvious ‘best’ execution plan. The details of which types of query can benefit from Trivial Plan change frequently, but things like joins, subqueries, and inequality predicates generally prevent this optimization. The queries below show some examples where Trivial Plan can, and cannot be applied:
-- Trivial planSELECT p.ProductIDFROM Production.Product AS p
WHERE p.Name = N‘Blade‘;
GO-- Still trivialSELECTp.Name,
RowNumber =
ROW_NUMBER() OVER (ORDER BY p.Name)
FROM Production.Product AS p
WHERE p.Name LIKE N‘[A-G]%‘;
GO-- ‘Subquery‘ prevents a trivial planSELECT (SELECT p.ProductID)
FROM Production.Product AS p
WHERE p.Name = N‘Blade‘;
GO-- InequalitySELECT p.ProductIDFROM Production.Product AS p
WHERE p.Name <> N‘Blade‘;
One interesting case where a Trivial Plan is not applied is where the estimated cost of the Trivial Plan query exceeds the configured ‘cost threshold for parallelism’. The reasoning here is that any trivial plan that would qualify for a parallel plan suddenly presents a choice, and a choice means the query is no longer ‘trivial’, and we have to go through full cost-based optimization. Taking this to the extreme, a SQL Server instance with the parallelism cost threshold set to zero will never produce a trivial plan (since all queries have a cost greater than zero). At the risk of stating the slightly obvious, note that a plan produced at this stage will always be serial. For experimentation only, the trivial plan stage can also be disabled using trace flag 8757.
The input to cost-based optimization is a tree of logical operations produced by the previous optimization stages discussed in part one. Cost-based optimization takes this logical tree, explores logical alternatives (different logical tree shapes that produce the same results), generates physical implementations, assigns an estimated cost to each, and finally chooses the cheapest physical option overall.
The goal of cost-based optimization is not to find the best possible physical execution plan by exploring every possible alternative; rather, the goal is to find a good plan quickly. This approach gives us an optimizer that works pretty well for most workloads, most of the time. If you think about it, that’s quite an achievement – after all, my database is likely very different from yours, and we probably run on quite different hardware as well. The point about finding a good plan quickly is also important – generally, we would not want the optimizer to spend hours optimizing a query that runs for only a few seconds.
This design has a number of important consequences. First, a skilled query tuner will often be able to come up with a better plan than the optimizer does. In some cases, this will because the human can reason about the query in a way the optimizer cannot. Other times, it is simply a question of time – we might be happy spending half a day finding a great execution plan for a crucial query, whereas the optimizer places strict limits on itself to avoid spending more time on optimization than it saves on a single execution.
Perhaps a future version of SQL Server will allow us to configure the optimizer to spend extra time on a particular query – today, we have to use query hints and ‘manual optimizations’ to encourage a particular execution plan shape. The down side to circumventing the optimizer’s natural behaviour in this way is that we then have to take responsibility for ensuring that the execution plan remains good in the future, as data volumes and distributions change. In most systems, it is best to limit the number of manually-tuned queries to a minimum, and thoroughly document any tricks you use to obtain a particular plan.
Back to the task at hand. We have a sample query (reproduced below) that has been through all the previous optimization stages, did not qualify for a trivial plan, and so needs to go through the cost-based optimization process.
SELECTp.Name,
Total = SUM(inv.Quantity)FROM Production.Product AS p, Production.ProductInventory AS invWHEREinv.ProductID = p.ProductID
AND p.Name LIKE N‘[A-G]%‘
GROUP BY
p.Name;
The tree of logical operations passed to the optimizer looks like this:

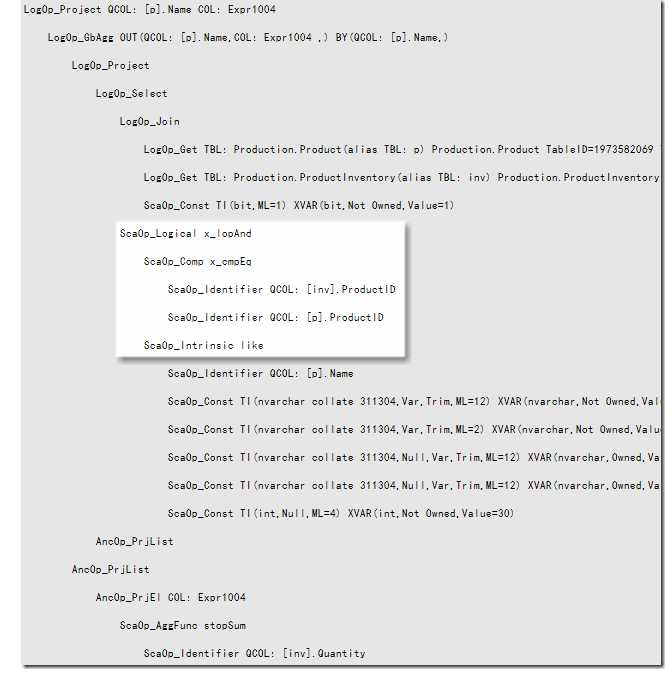
This looks very similar to the original logical tree seen in part one, though cardinality estimates have been added to each primary node, and the tree layout has been expanded a little into a form that is easier for the system to work with. In addition to simple cardinality estimates, remember that each node also has statistics objects (histograms and frequency information) derived from the familiar statistics associated with the tables in the query.
There are also a number of other ‘properties’ associated with each node, that have been added by previous optimization stages. These properties include logical attributes, such as:
There are also some physical properties that may be present on each node, for example:
The optimizer contains rules to transform trees. There are four classes of rule:
Simplification rules transform some part of the logical tree to a simpler logical form, and are responsible for the simplification transforms we saw in part one. Exploration rules run only during cost-based optimization, generating new logical equivalents for some part of the existing logical tree. Implementation rules produce a physical operation (like a hash or merge join) for a logical operation (a logical join). Property enforcement rules introduce new elements to the logical tree to enforce some desired physical property at that point, for example to enforce a particular sorted order of rows (as might be required by a merge join or stream aggregate).
There are 395 rules in SQL Serer 2012, most of which perform quite simple operations; it is the fact that many rules can be run in various orders that accounts for the apparent complexity of optimizer behaviour. The way that simple rules can combine to produce complex behaviours reminds me of Conway’s Game of Life – a cellular automation program with only four rules that nevertheless can produce extraordinarily complex and beautiful patterns as the rules are applied over and over.
One example of a simple exploration rule is SELonJN, a rule that merges a suitable relational SELECT (row filter) into a logical join operation:

Another common exploration rule that generates a new logical alternative is JoinCommute:

As the name suggests, JoinCommute explores a different logical join order, exploiting the fact that A JOIN B is equivalent to B JOIN A for inner joins. Though logically equivalent, the different join orders may have different performance characteristics once the logical alternatives are translated to a physical implementation by a later implementation rule. A third exploration rule that is relevant to our test query is GbAggBeforeJoin, a rule that explores the possibility of pushing an aggregation operation under a join:

As mentioned previously, implementation rules transform part of a logical tree into a physical alternative:

The diagram shows three join implementation rules, JNtoNL (nested loops), JNtoHS (hash join), JNtoSM (sort-merge join); two implementations for Group-By Aggregate, GbAggToStrm (Stream Aggregate) and GbAggToHS (Hash Aggregate); SelectToFilter, GetToScan, and GetIdxToRng.
If we want to see which rules were used when optimizing a query, one option is to use an undocumented view which shows the number of times a rule has been asked to estimate how valuable it might be in the current context (its ‘promise’ value), the number of times the rule was used to generate an alternative section of the tree (‘built’), and the number of times the output of the rule was successfully incorporated into the search space (‘succeeded’). A sample of the contents of the sys.dm_exec_query_transformation_stats DMV is shown below:

By taking a snapshot view of this information before and after optimizing a particular query, we can see which rules were run. The DMV is instance-wide however, so you would need to run these tests on a system to which you have exclusive access. The scripts that accompany this series of posts contain a complete test rig to show the rules used by each query.
We saw in part 2 how optimizer rules are used to explore logical alternatives for parts of the query tree, and how implementation rules are used to find physical operations to perform each logical steps. To keep track of all these options, the cost-based part of the SQL Server query optimizer uses a structure called the Memo. This structure is part of the Cascades general optimization framework developed by Goetz Graefe. The Memo provides an efficient way to store many plan alternatives via the use of groups.
Each group in the Memo initially contains just one entry – a node from the input logical tree. As exploration and implementation phases progress, new groups may be added, and new physical and logical alternatives may be added to existing groups (all alternatives in a group share the same logical properties, but will often have quite different physical properties). Groups are also shared between plan alternatives where possible, allowing Cascades to search more plans in the same time and space compared with other optimization frameworks.
Continuing with our example query, the input tree to cost-based optimization is first copied into the Memo structure. We can see this structure using trace flag 8608:
USE AdventureWorks2008R2;GOSET NOCOUNT ON;
DBCC FREEPROCCACHE;DBCC TRACEON(3604);GO-- Initial memo contentsSELECTp.Name,
Total = SUM(inv.Quantity)FROM Production.Product AS p
JOIN Production.ProductInventory AS inv ON
inv.ProductID = p.ProductID
WHEREp.Name LIKE N‘[A-G]%‘
GROUP BY
p.Name
OPTION (QUERYTRACEON 8608);As a reminder, this is the logical input tree to cost-based optimization shown in part 2:

This is copied to the Memo, one group per logical node, illustrated below:

One the initial Memo has been populated from the input tree, the optimizer runs up to four phases of search. There is a documented DMV,sys.dm_exec_query_optimizer_info, that contains a number of counters specific to query optimization. Four of these counters are ‘trivial plan’, search 0’, ‘search 1’, and ‘search 2’. The value for each counter keeps track of the number of times a search phase was entered. By recording the values before and after a specific optimization, we can see which phases were entered. The current counter values on one of my test SQL Server instances is shown below, as an example:

We look at each of the four phases in a bit more detail next:
This phase is primarily concerned with finding good plans for OLTP-type queries, which usually join a number of tables using a navigational strategy (looking up a relatively small number of rows using an index). This phase primarily considers nested-loops joins, though hash match may be used when a loops join implementation is not possible. Many of the more advanced (and costly to explore) optimizer rules are not enabled during this search phase – for example search 0 never considers indexed view matching or parallel plans.
This search phase can use most or all of the available rules, can perform limited join reordering, and may be run a second time (to consider parallel plans only) if the first run produces a plan with a high enough cost. Most queries find a final plan during one of the Search 1 runs.
This phase uses the most comprehensive search configuration, and may result in significant compilation times in some cases. The search is either for a serial or parallel plan, depending on which type was cheaper after search 1.
The scripts accompanying this series show another way to see which phases were run, using trace flag 8675. The output provides some extra insight into how things work (for example it shows the number of optimization moves (tasks) made in each stage). The only documented and supported way to see the search phases is via the DMV, however.
Each phase has entry conditions, a set of enabled rules, and termination conditions. Entry conditions mean that a phase may be skipped altogether; for example, search 0 requires at least three joined tables in the input tree. Termination conditions help to ensure the optimizer does not spend more time optimizing than it saves – if the current lowest plan cost drops below a configured value, the search will terminate early with a ‘Good Enough Plan Found’ result.
The optimizer also sets a budget at the start of a phase for the number of optimization ‘moves’ it considers sufficient to find a pretty good plan (remember the optimizer’s goal is to find a good enough plan quickly). If the process of exploring and implementing alternatives exceeds this ‘budget’ during a phase, the phase terminates with a ‘Time Out’ message. Early termination (for whatever reason) is part of the optimizer’s design, completely normal, and not generally a cause for concern.
From time to time, we might wish that the optimizer had different goals – perhaps that we could ask it to continue searching for longer – but this is not how it works. It is all too easy to over-spend on optimization (finding transformations is not hard – finding ones that are robustly useful in a wide range of circumstances is), and full cost-based exploration is a memory and processor-intensive operation. The optimizer contains many heuristics, checks and limits to avoid exploring unpromising alternatives, to prune the search space as it goes, and ultimately produce a pretty good plan pretty quickly, most of the time, on most hardware, in most databases.
First a quick summary: The optimizer runs up to four phases, each of which performs exploration using rules (finding new logical alternatives to some part of the tree), then a round of implementation rules (finding physical implementations for a logical part of the tree). New logical or physical alternatives are added to the Memo structure – either as an alternative within an existing group, or as a completely new group. Note that the Memo allows the optimizer to consider very many alternatives at once in a compact and quick-to-search structure; the optimizer does not just work on one overall plan, performing incremental improvements (this is a common misconception).
Having found all these alternatives, the optimizer needs a way to choose between them. Costing runs after each round of implementation rules, producing a cost value for each physical alternative in each group in the memo (only physical operations can be costed, naturally). Costing considers factors like cardinality, average row size, expected sequential and random I/O operations, processor time, buffer pool memory requirements, and the effect of parallel execution.
Like many areas of optimization, the costing calculations are based on a complex mathematical model. This model generally provides a good basis on which to compare alternatives internally, regardless of the workload or particular hardware configuration. The costing numbers do not mean very much by themselves, so it is generally unwise to compare them between statements or across different queries. The numbers are perhaps best thought of as a unit-less quantity, useful only when comparing alternative plans for the same statement.
The model is just that of course: a model, albeit one that happens to produce very good results for most people most of the time. The slide deck that accompanies this series contains details of some of the simplifying assumptions made in the model.
At the end of each search phase, the Memo may have expanded to include new logical and physical alternatives for each group, perhaps some completely new groups. We can see the contents after each phase using trace flag 8615:
-- Final memoSELECTp.Name,
Total = SUM(inv.Quantity)FROM Production.Product AS p
JOIN Production.ProductInventory AS inv ON
inv.ProductID = p.ProductID
WHEREp.Name LIKE N‘[A-G]%‘
GROUP BY
p.Name
OPTION (RECOMPILE, QUERYTRACEON 8615);The final Memo (after each phase, remember) can be quite large, despite the techniques employed to constrain the search space. Our simple test query only requires a single run through search 1, and terminates early after 509 moves (tasks) with a ‘Good Enough Plan Found’ message. Despite that, the Memo contains 38 groups (up from 18) with many groups containing several alternatives. The extract below highlights just the groups that relate directly to the join implementation:

Looking at the green shaded areas, group 13 item 0 was the original (joining groups 8 and 9 and applying the condition described by the sub-tree starting with group 12). It has gained an logical alternative (via the Join Commute rule, reversing the join input groups), and two surviving physical implementations: a one-to-many merge join as item 7, with group 8 option 2 as the first input, and group 9 option 2 as the second; and a physical inner Apply driven by group 8 option 6, on group 30 option 2. Group 20 is completely new – another one-to-many merge join option, but this time with inputs from groups 19.4 and 8.2 with 12 familiar as the join condition. Again, the scripts accompanying this series can be used to explore the details further, if you wish.
The final selected plan consists of physical implementations chosen by starting with the lowest-cost physical option in the root group (18, shaded pink above). The sub-tree from that point has a total estimated cost of 0.0295655 (this is the same cost shown in the final graphical execution plan). The plan is produced by following the links in the Memo, from group 18 option 4, to group 20 option 6, and so on to the leaves:


Our test query produces an optimized physical execution plan that is quite different from the logical form of the query. The estimated cost of the execution plan shown below is 0.0295 units.

Since we know the database schema very well, we might wonder why the optimizer did not choose to use the unique nonclustered index on names in the product table to filter rows based on the LIKE predicate. We could use an index hint to force the name index to be used:

That’s great, and no doubt the index seek is cheaper than the scan we had previously, but the optimizer has still chosen to use a merge join, and that means having both inputs sorted on Product ID. The result of the index seek is ordered by name (the index key) rather than Product ID, so a sort is required. It looks like the new sort adds a little more cost than the seek saves over the scan, because the estimated cost of the query plan with the index hint is 0.0316units.
Naturally, these numbers are rather small since AdventureWorks is not a large database, but these differences can be important in real systems. Anyway, let’s persist with the index seek idea; why is the optimizer so keen on a merge join, even though it involves an extra sort, and we don’t have an ORDER BY Product ID clause on our query? Without a top-level ORDER BY, we are giving the optimizer the freedom to return results in any order that is convenient – perhaps we can do better by forcing the index seek and a hash join instead of a merge join?

Well the sort has gone, so the plan looks visually a little simpler, but the estimated cost has increased again, to 0.0348 units. Hash join has quite a high start-up cost (and it requires a memory workspace grant). We could try other things, but it certainly seems that the optimizer had it right to begin with in this case.
The manual exploration above shows that the optimizer does generally find a good plan quickly (and sometimes it may even find the best possible plan). The terms ‘good’ and ‘best’ here are measured in terms of the optimizer’s own cost model. Whether one particular plan shape actually executes faster on a given system is another question. I might find, for example, that the first merge join plan runs fastest for me, whereas you might find the seek and sort runs fastest for you. We might both find that which is faster depends on whether the indexes and data needed are in memory or need to be retrieved from persistent storage. All these things aside, the important thing is that we are both likely to find that the optimizer’s plans are pretty good most of the time.
There are three principal models used by the optimizer to provide a basis for its reasoning: cardinality estimation, logical relational equivalences, and physical operator costing. Good cardinality estimation (row count expectations at each node of the logical tree) is vital; if these numbers are wrong, all later decisions are suspect. Fortunately, it is relatively easy to check cardinality estimation by comparing actual and estimated row counts in query plans. There are some subtleties to be aware of – for example when interpreting the inner side of a nested loops join, at least in SSMS. If you use the free SQL Sentry Plan Explorertool, many of these common misinterpretations are handled for you.
The model used in cardinality estimation is complex, and contains all sorts of hairy-looking formulas and calculations. Nevertheless, it is still a model, and as such will deviate from reality at least to some extent. I’ll have more to say later on about what we can do to help ensure good cardinality estimates, but for now we will just note that the model has its roots in relational theory and statistical analysis.
Relational equivalences (such as A inner join B = B inner join A) are the basis for exploration rules in the cost-based optimizer. Not all possible relational transformations are included in the product (remember the goal of the optimizer is to find a good plan quickly, not to perform an exhaustive search of all possible plans). As a consequence, the SQL syntax you use will often affect the plan produced by the optimizer, even where different SQL syntaxes express the same logical requirement. Also, the skilled query tuner will often be able to do better than the optimizer, given enough time and perhaps a better insight to the data. The downside of such manual tuning is that it will usually require manual intervention again in the future as data volumes and distributions change.
Physical operator costing is very much the simplest of the three models, using formulas that have been shown to produce good physical plan selections for a wide range of queries on a wide range of hardware. The numbers used probably do not closely model your hardware or mine, but luckily that turns out not to be too important in most cases. No doubt the model will have to be updated over time as new hardware trends continue to emerge, and there is some evidence in SQL Server 2012 show plan output that things are heading in that direction.
All models make simplifying assumptions, and the cardinality estimation and costing models are no different. Some things are just too hard to model, and other things just haven’t been incorporated into the model yet. Still other things could be modelled, but turn out not to add much value in practice and cost too much in terms of complexity or resource consumption. Some of the major simplifying assumptions that can affect real plan quality are:
There are three approaches to working with the optimizer:
All three are valid approaches in different circumstances, though the third option is probably the one to recommend as the best starting point. There is much more to helping the optimizer than just making sure statistics are up-to-date, however:
This is probably the biggest single item. The various models all assume that your database has a reasonably relational design, not necessarily 3NF or higher, but the closer your structures are to relational principles, the better. Cardinality estimation works best with simpler relational operations like joins, projects, selects, unions and group by. Avoid complex expressions and non-relational query features that force cardinality estimation to guess. Also remember that the cost-based optimizer’s exploration rules are based on relational equivalences, so having a relational design and writing relational queries gives you the best chance of leveraging the hard work that has gone into those rules. Some features added in 2005 (e.g. ranking functions) operate on sequences rather than multi-sets (hence the Sequence Project physical operator); the original rules all work with multi-sets, and the seams between the two approaches often show though.
Use check constraints, foreign keys, unique constraints to provide the optimizer with information about your data. Simplification and exploration rules match patterns in the logical tree, and may also require certain properties to be set on the matched nodes. Constraints and keys provide some of the most powerful and fundamental logical properties – omitting these can prevent many of the optimizer’s rules from successfully transforming to an efficient physical plan. If an integer column should only contain certain values, add a check constraint for it. If a foreign key relationship exists, enforce it. If a key exists, declare it. It is not always possible to predict the benefits of providing this type of optimizer information, but my own experience is that it is much greater than most people would ever expect.
Provide more than just default-sampled automatically-created statistics where appropriate (for example where distribution is unusual or correlations exist). Create indexes that will provide potentially useful access paths for a wide range of queries. If you have expressions on columns in your WHERE clause, consider adding a computed column that matches the expression exactly. The computed column does not have to be persisted or indexed to be useful; the system can auto-create statistics on the computed column, avoiding cardinality guessing.
Large, complex queries produce large, complex logical trees. Any errors tend to multiply (perhaps exponentially) as the size of the tree increases, the search space of possible plans expands greatly, and things just become much more difficult in general. Breaking a complex query into smaller, simpler, more relational, steps will generally get greater value out of the optimizer. A side benefit is that small intermediate results stored in a temporary table can have statistics created, which will also help in many cases. There will always be cases where a large complex query is required for ultimate performance, but very often the performance difference is relatively small and may not be worth the future maintenance costs as hand-tuned monolithic queries tend to be fragile.
User-defined functions (other than the in-line variety) may seem convenient, but they are almost completely opaque to the optimizer – it has to guess at the cardinality and distribution of rows produced. Newer features also tend to have much shallower support in the engine than longer-established features that have been around for multiple versions of the product. By all means use all the shiny new features, just be aware that combining them may produce plans of variable quality.
To summarize the flags used in this series (all assume 3604 is also active):
7352 : Final query tree
8605 : Converted tree
8606 : Input, simplified, join-collapsed, and normalized trees
8607 : Output tree
8608 : Initial memo
8615 : Final memo
8675 : Optimization stages and times
The above were used in the presentation because they all work from 2005 to 2012. There are a large number of other optimizer-related flags (some of which only work on 2012). Some are listed below for people that like this sort of thing:
2373 : Memory before and after deriving properties and rules (verbose)
7357 : Unique hash optimization used
8609 : Task and operation type counts
8619 : Apply rule with description
8620 : Add memo arguments to 8619
8621 : Rule with resulting tree
As usual, these are undocumented, and unsupported (including by me!) and purely for educational purposes. Use with care at your own risk.
I hope you have gained some insight and intuition for the workings of the query optimizer: logical trees, simplification, cardinality estimation, logical exploration and physical implementation. The geeky internals stuff is fun, of course, but I rather hope people came away from these sessions with a better understanding of how query text is transformed to an executable plan, and how relational designs and simpler queries can help the optimizer work well for you. Taking advantage of the optimizer frees up time for more productive things – new projects, tuning the odd interesting query, whatever it is you would rather be doing than fighting the same query-tuning battles over and over again.
There are some great resources out there to learn more about SQL Server. Make full use of them to continue to improve your technical skills and just as importantly, experiment with things to build your experience level. Take a deeper look at query plans and the properties they contain; there is a wealth of information there that sometimes requires a bit of thinking and research to understand, but the insights can be invaluable.
The original slides and demo code is again attached as a zip file below. Thanks for reading, all comments and feedback are very welcome.
Finally, I would like to thank Adam Machanic (blog | twitter) for introducing me to the QUERYTRACEON syntax all that time ago, and Fabiano Amorim (blog |twitter) for his email last year that kick-started the process of developing this presentation and blog series.
SQL optimizer -Query Optimizer Deep Dive
标签:
原文地址:http://www.cnblogs.com/zwCHAN/p/4282786.html