标签:

synchronized不仅仅只有原子性,还具有内存可见性。我们不仅希望能够避免一个线程修改其他线程正在使用的对象的状态,而且希望确保当一个线程修改了对象的状态后,其他线程能够真正看到改变。你可以使用显示的同步或者利用内置于类库中的同步机制,来保证对象的安全性。
在多线程环境下,下面程序中当ready为true时,number不一定为42,这是因为它没有使用恰当的同步机制,没有保证主线程写入ready和number的值对读线程是可见的。
public class NoVisibility {
private static boolean ready;
private static int number;
private static class ReaderThread extends Thread {
public void run() {
while (!ready)
Thread.yield();
//这里可能输出0,也可能永远都不会输出
System.out.println(number);
}
}
public static void main(String[] args) {
new ReaderThread().start();
number = 42;
ready = true;
}
}
这里可能会产生两个问题,一是程序可能一直保持循环,因为对于读线程来说,ready的值可能永远不可见。二是输入的number为0,这是因为重排序引起的,在写线程将ready与number从工作内存中写回到主内存中时,在没有同步的机制下,先写ready还是先写number这是不确定的,也就是说将它们写回到主内存时的顺序可能与程序逻辑顺序恰好相反,这是因为在单个线程下,只要重排序不会对结果产生影响,这是允许的。
在没有使用同步的情况下,编译器、运行器、运行时安排顺序可能完全出乎意料,在没有进行适当同步的多线程程序中,尝试推断那些“必然”发生在内存中的动作时,你总是会判断错误。
上面NoVisibility程序在多线程环境下还可能读取到过期数据,比如当ready为true时,写线程已将number域的值置为了42,但在它还未来得及将这个新值从工作内存中写回到主内存前,读线程就已将ready从主内存中读取出来了,这时的值还是为初始的默认值0,这个值显然是一个已过期了的值,因为number现在真真的值应该为42,而不是0。
在没有同步的情况下读取数据类似于数据库中使用READ_UNCOMMITTED(未提交读)隔离级别,这时你更愿意用准确性来交换性能。
在NoVisibility中,过期数据可能导致它打印错误数值,或者程序无法终止。过期数据可能会使对象引用中的数据更加复杂,比如链指针在链表中的实现。过期数据还可能引发严重且混乱的错误,比如意外的异常,脏的数据结构,错误的计算和无限的循环。
下面的程序更对过期数据尤为敏感:如果一个线程调用了set,但还未来得及将这个新值写回到主内存中时,而另一个线程此时正在调用get,它就可能看不到更新的数据了:
@NotThreadSafe
public class MutableInteger {
private int value;
public int get() { return value; }
public void set(int value) { this.value = value; }
}
我们可以将set与get同步,使之成为线程安全的。注,仅仅同步某个方法是没有用的。
当一个线程在没有同步的情况下读取变量,它可能会得到一个过期值。但是至少它可以看到某个线程在那里设定的一个完整而真实数值,而不是一个凭空而来的值。这样的安全保证被称为是最低限的安全性。
最低限的安全性应用于所有变量,除了一个例外:没有声明为volatile的64位数值变量double和long。Java内存模型规定获取(read动作)和存储(write动作)操作都是原子性的,但是对于非volatile的long和double变量,JVM允许将64位的读回写划分为两个32的操作。如果读和写发生在不同的线程,这种情况读取一个非volatile类型long就可能会现得到一个线程写的值的高32位和另一个线程写的值的低32位,最终这个long变量的值由这两个线程高低位组合而成的值。因此,即使你并不关心过期数据,但仅仅在多线程程序中使用共享的、可变的long和double变量也可能是不安全的,除非将它们声明为volatile类型,或者锁保护起来。
内置锁可以用来确保一个线程以某种可预见的方法看到另一个线程的影响,像下图一样。当B执行到与A相同的锁监视的同步块时,A在同步块之中所做的每件事,对B都是可见的,如果没有同步,就没有这样的保证。
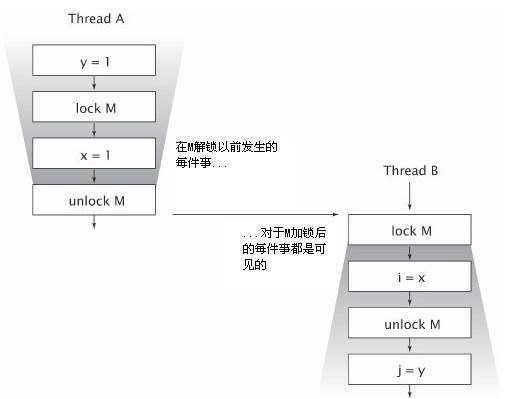
锁不仅仅是关于同步与互斥的,也是关于内存可见的。为了保证所有线程都能够看到共享的、可变变的最新值,读取和写入线程必须使用公共锁进行同步。
volatile是一种弱同步的形式,它确保对一个变量的更新后对其他线程是可见的。当一个域声明为volatile类型后,编译器与运行时会监视这个变量:它是共享的,而且对它的操作不会与其他的内存操作一起被重排序。volatile变量不会缓存在寄存器或者缓存其他处理器隐藏的地方,所以,读一个volatile类型的变量时,总会返回由某一线程所写入的最新值。
读取volatile变量的操作不会加锁,也就不会引起执行线程的阻塞,这使得volatile变量相对于sychronized而言,只是轻量级的同步机制
volatile变量对可见性的影响所产生的价值远远高于变量本身。线程A向volatile变量写入值,随后线程B读取该变量,所有A执行写操作前可见的变量的值,在B读取了这个volatile变量后,对B也是可见的(与解锁前所有动作对后继加锁后的动作可见是一样的)。所以从内存可见性的角度来看,写入volatile变量就像退出同步块,读取volatile变量就像进入同步块。但是我们并不推荐过度依赖volatile变量所提供的可见性。因为依赖volatile变量来控制状态可见性的代码,比使用锁的代码更脆弱,更难以理解。
调试提示:对于服务器应用程序,确保无论是在开发阶段还是测试阶段,启动JVM时都使用-server命令行选项。server模式的JVM会比client模式的JVM执行更多的优化,比如把没有在循环体中修改的变量提升到循环体外部;在开发环境(client模式的JVM)中可以工作的代码,可能会在部署环境(server模式的JVM)中失败。举个例子:比如下面程序中,如果我们忘记把asleep变量声明为volatile,server模式的JVM会将检查asleep的工作提升到循环外部(将它变为一个无限循环),但是client模式的JVM不会这样做。开发环境中的无限循环的开锁远小于将它置于生产环境中所产生的开销。
//实例:数绵羊。
//一定要加上volatile,否则其他线程更新后可能不可见volatile boolean asleep;...
while (!asleep)
countSomeSheep();
volatile变量固然方便,但也存在限制,它们通常被当作标识完成、中断、状态的标记使用,比如上面程序中的asleep变量。尽管volatile也可以用来标示其他类型的状态信息,但是决定这样做之前请格外小心,如volatile的语义不足以使用自增操作(i++)原子化。
加锁可以保证可见性与原子性;volatile变量只能保证可见性。
只有满足了下面所有的标准后,你才能使用volatile变量:
1、 写入变量时并不依赖变量的当前值;或者能够能够确保只有单一线程修改变量的值;
2、 变量不需要与其他的状态变量共同参与不变约束;
3、 而且,访问变量时,没有其他的原因需要加锁。
发布一个对象的意思是使它能够被当前范围之外的代码所使用。比如将一个引用存储到其他代码可以访问的地方、在一个非私有的方法中返回这个引用、也可以把它传递到共他类的方法中。在很多情况下,我们需要确保对象及它们的内部状态不被暴露,在另外一些情况下,为了正当的使用目的,我们又的确希望发布一个对象,这时为了线程安全可能需要同步。如果变量发布了内部状态,就可能危及到封装性,并使用程序难以维持稳定;如果发布对象时,它还没有完成构造,同样危及线程安全。一个对象在尚未准备地时就将它发布,这种情况称作逸出。下面看看一个对象是如何逸出的。
最常见的发布对象的方式是将对象的引用存储到公共静态域,任何类和线程都能看到这个域。initialize方法实例化一个新的HashSet实例,并通过将它存储到knownSecrets引用,从而发布了这个实例:
//发布对象
public static Set<Secret> knownSecrets;
public void initialize() {
knownSecrets = new HashSet<Secret>();
}
发布一个对象还会间接地发布其他对象。如果你将一个Secret对象加入集合knownSecrets中,你就已经发布了这个对象,因为任何代码都可以遍历并获得新Secret对象的引用。类似地,从非私有方法中返回引用,也能发布返回的对象,下面发布了包含洲名的数组,而这个数组本应是私有的:
//内部可变的数据逸出(不要这样做)
class UnsafeStates {
private String[] states = new String[] {
"AK", "AL" ...
};
public String[] getStates() { return states; }
}
以这种方式发布states会出问题,这样会允许内部可变的数据逸出,请不要这样做。因为任何一个调用者都能修改它的内容。在这个例子中,数组states已经逸出了它所属的范围,这个本就是私有的数据,事实上已经变成公有的了。
发布一个对象,同样也发布了该对象所有非私有域所引用的对象。
最后一种发布对象和它的内部状态的机制是发布一个内部类实例。
//隐式地允许this引用逸出,请不要这样做:
public class ThisEscape {
public ThisEscape(EventSource source) {
source.registerListener(
new EventListener() {//会过早地暴露this
public void onEvent(Event e) {
doSomething(e);
}
});
}
}
对象只有通过构造函数返回后,才处于稳定状态。从构造函数内部发布的对象,只是一个未完成构造的对象。甚至即使是在构造函数的最后一行发布的引用也是如此。如果this引用在构造器中逸出,这样的对象被认为是“没有正确构建的”,所以不要让this引用在构造期间逸出。
一个导致this引用在构造期间逸出的常见错误,是在构造函数中创建局部、匿名线程并启动它或者启动一个线程并显示地将this传递过去,这都是不安全的,因为新的线程在所属对象完成构造前就能看见了。在构造器中创建线程并没有错,但是最好不要立即启动它,取而代之的是,发布一个start或initialize方法来启动对象拥有的线程。
另外,构造器中调用一个覆盖的实例方法同样会导致this引用在构造期间逸出。
如果想要在构造器中注册监听器或启动线程,你可以使用一个私有的构造函数和一个公有的工厂方法,这样避免了不正确的问题。
下面是使用工厂方法防止this引用在构造期间逸出:
public class SafeListener {
private final EventListener listener;
private SafeListener() {//私有构造器
listener = new EventListener() {
public void onEvent(Event e) {
doSomething(e);
}
};
}
//使用静态 工厂方法安全发布对象
public static SafeListener newInstance(EventSource source) {
SafeListener safe = new SafeListener();//等构造完后再注册
source.registerListener(safe.listener);
return safe;//安全发布对象
}
}
局部变量是线程安全的,只要我们不要将它们逸出。
使用ThreadLocal确保线程的封闭性。假设你正在将一个单线程的应用迁移到多线环境中,你可以将共享的全局变量都转换为ThreadLocal类型,这样可以确保线程安全。前提是全局共享的语义是允许这样的,如果将应用级的缓存变成一个堆线程缓冲,它将毫无价值。
不可变性也可以满足同步的需求。
创建后状态不能被修改的对象叫做不可变对象。不可变对象天生就是线程安全。它们常量域是在构造函数中创建的。既然它们的状态无法被修改,这些常量永远不会变。所以不可变对象永远是线程安全的。
不可变性并不简单地等于将对象中的所有域都声明为final类型,所有域都是final类型的对象仍然可能是可变的,因为final域可以获得一个到可变对象的引用。只有满足如下状态,一个对象才是不可变的:
1、 它的状态不能在创建后再被修改;
2、 所有域都是final类型;并且,
3、 它被正确创建(创建期间没有发生this引用逸出)。
注,从技术上讲,不可变对象的域并不是全部声明为final类型,这样的情况是可能存在的,String就是这种类。设计这种类依赖于对象良性(恶意除外)数据竞争的精准分析,还需要对Java内存模型有深入的理解,但请不要自己这么做。(1.5版本中除了hash域外都已经是final类型的,而在这之前不是的,所以1.5版本中加强了不可变的语义。)
在不可变对象的内部,同样可以使用可变性对象来管理它们的状态,如下面代码,虽然域stooges是可变的,但它满足了以上三点,所以是一个不可变对象:
@Immutable//不可变对象可以基于可变对象来实现
public final class ThreeStooges {
private final Set<String> stooges = new HashSet<String>();
public ThreeStooges() {
stooges.add("Moe");
}
public boolean isStooge(String name) {
return stooges.contains(name);
}
}
final域不能修改的(尽管如果final域指向的对象是不可变的,这个对象仍然可被修改),然而它在Java内存模式中还有着特殊语义。final域使得确保被始化安全性成为可能,初始化安全性让不可变性对象不需要同步就能自由地被访问和共享。
正如“将所有的域声明为私有的,除非它们需要更高的可见性”一样“将所有的域声明为final型,除非它们是可变的”,也是一条良好的实践。
尽管原子引用自身是线程安全的,不过UnsafeCachingFactorizer中存在竞争条件,在A 与 B,C 与 D之间都有可能切换到其他线程,从而造成错误的结果。
//没有正确原子化的Servlet试图缓存它的最新结果。
@NotThreadSafe
public class UnsafeCachingFactorizer implements Servlet {
private final AtomicReference<BigInteger> lastNumber
= new AtomicReference<BigInteger>();//缓存最后一次客户请求因式分解的数
private final AtomicReference<BigInteger[]> lastFactors
= new AtomicReference<BigInteger[]>();//缓存最后一次客户请求因式分解的结果
public void service(ServletRequest req, ServletResponse resp) {
BigInteger i = extractFromRequest(req);
if (i.equals(lastNumber.get()))//A
encodeIntoResponse(resp, lastFactors.get() );//B
else {
BigInteger[] factors = factor(i);
lastNumber.set(i);//C
lastFactors.set(factors);//D
encodeIntoResponse(resp, factors);
}
}
}
如果上面的A与B操作、以及C与D操作如果是原子性的,那么将不会出现线程安全性问题。如果为这两组操作创建一个不可变的类,即使在不使用同步的情况也能解决安全共享问题。下面就为UnsafeCachingFactorizer创建一个OneValueCache类,对以上操作进行了封装,它是一个不可变对象,进(构造时传进的参数)出(使用时)都对状态进行了拷贝。因为BigInteger是不可变的,所以直接使用了Arrays.copyOf来进行拷贝了,如果状态所指引的对象不是不可变对象时,就要不能使用这项技术了,因为外界可以对这些状态所指引的对象进行修改,如果这样只能使用new或深度克隆技术来进行拷贝了。
@Immutable
class OneValueCache {
private final BigInteger lastNumber;
private final BigInteger[] lastFactors;
public OneValueCache(BigInteger i,
BigInteger[] factors) {
lastNumber = i;
lastFactors = Arrays.copyOf(factors, factors.length);
}
public BigInteger[] getFactors(BigInteger i) {
if (lastNumber == null || !lastNumber.equals(i))
return null;
else
return Arrays.copyOf(lastFactors, lastFactors.length);
}
}
VolatileCachedFactorizer利用OneValueCache存储缓存的数字及因数。与cache域相关的操作的线程不会相互干扰,因为OneValueCache是不可变的,并且利用volatile引用确保及线程之间及时的可见,这两个前提(不可变、使用volatile发布)保证了VolatileCachedFactorizer在没有显式地使用锁,但这个类仍然是线程安全的。
@ThreadSafe
public class VolatileCachedFactorizer implements Servlet {
private volatile OneValueCache cache =
new OneValueCache(null, null);//使用volatile安全发布
public void service(ServletRequest req, ServletResponse resp) {
BigInteger i = extractFromRequest(req);
BigInteger[] factors = cache.getFactors(i);
if (factors == null) {
factors = factor(i);
//由于cache为volatile,所以最新值立即能让其它线程可见
cache = new OneValueCache(i, factors);
}
encodeIntoResponse(resp, factors);
}
}
下面程序中简单地将对象的引用存储到public域中,这不足以安全地发布它:
// 不安全的发布:在没有适当的同步情况下就发布对象
public Holder holder;
public void initialize() {
holder = new Holder(42);
}
public class Holder {
private int n;
public Holder(int n) { this.n = n; }
public void assertSanity() {
if (n != n)//在不正确的发布中,是很有可能出现不等
throw new AssertionError("This statement is false.");
}
}
上面程序的问题是由于对象的可见性问题引起的(最根本的原因是由于JVM运行时重排序引起的),发布的对象可能还处于构造期间,所以是不稳定的。因为没有同步来确保Holder对其他线程可见,所以我们称Holder是“非正确发布”。
由于上面 n != n 会从主存中两次读取,这有可能从这两次读操作间切换到其他线程,这就有可能出 n!=n奇怪的问题。
Java内存模型为共享不可变对象提供了特殊的初始化安全性的保证,即对象在完全初始化之后才能被外界引用,所以只要是不可变对象,一旦构建完成,就可以安全地发布了。
即使发布对象引用时没有使用同步,不可变对象仍然可以被安全地访问(注,只能保证一旦看到的对象就是完整的,在没有使用同步的情况下是不能保证对象引用的可见性,所以不可变对象只能保证初始化完后的就处于稳定状态)。为了获得这种初始化安全性的保证上,应该满足所有不可变性的条件:不可修改的状态、所有域都是final类型的以及正确的构造。(如果上面的Holder是不可变的,那么即使Holder没有正确的发布,assertSanity也不会抛出AssertionError。)
不可变对象可以在没有额外同步的情况下,安全地用于任意线程;甚至发布它们时也不需要同步。
这个保证还会延伸到一个正确创建的对象中所有final类型域的值。final域可以在没有额外的同步情况下被安全地访问(因为只要构造器一旦调用完毕,则final域的也会随之初始化完并可见),然而,如果final域指向可变对象,那么访问这些对象的状态时仍然需要同步的。
如果一个对象不是不可变的,它就必须要被安全的发布,通常发布线程与消费线程都必须同步。我们要确保消费线程能够看到处于发布当时的对象状态。
为了安全地发布一个可变对象,对象的引用以及对象的状态必须同时对其他线程可见。一个正确创建的对象可以通过下列条件安全地发布:
1、 通过静态初始化器初始化对象引用;
2、 将它的引用存储到volatile域或AtomicReference;
3、 将它的引用存储到正确创建的对象的Final域中;
4、 或者将它的引用存储到由锁正确保护的域中,即将对它的访问置于同步器中。
线程安全中的容器提供了线程安全保证(即变向地将对象置于了同步器中进行访问),正是遵守了上述最后一条要求。
比如类库中的安全性容器、Future、Exchanger同样创建了安全发布机制
通常,以最简单和最安全的方式发布一个被静态创建的对象,就是使用静态初始化器:
public static Holder holder = new Holder(42);
静态初始化器由JVM在类的初始阶段执行,由于JVM内在的同步,该机制确保了以这种方式初始化的对象可以被安全地发布。
如果对象在创建后被修改,那么安全发布仅仅可以保证“发布当时”状态的可见性。不仅仅在发布对象时需要同步,而且在对象发布后修改了对象状态又要让其他线程可见,则也需要对每次状态的访问进行同步。为了安全地共享可变对象,可变对象必须被安全发布,同时对状态的访问需要同步化。
如果某个类是可变的,但是它的状态不会在发布后被修改,这样的对象称为高效不可变对象。
用高效不可变对象可以简化开发,并且由于减少了同步的使用,还会提高性能。
任何线程都可以在没有额外的同步下安全地使用一个安全发布的高效不可变对象。
比如,Date自身是可变的(这也许是类库设计的一个错误),但是如果你把它当作不可变对象来使用就可以忽略锁。否则,每当Date被跨线程共享时,都要用锁确保安全。假设你正在维护一个Map,它存储了每位用户的最近登录时间:
public Map<String, Date> lastLogin =
Collections.synchronizedMap(new HashMap<String, Date>());
如果Date值在转入Map中后就不会改变,那么,synchronizedMap中同步的实现就足以将Date安全地发布,并且访问这些Date值时就不再需要额外的同步。
发布对象的必要条件依赖于对象的可变性:
1、 不可变对象可以通过任意机制发布(不需要同步);
2、 高效不可变对象(指对象本身是可变的,但只要发布后状态不再做修改)必须要安全发布;
3、 可变对象必须要安全发布,同时必须是线程安全或者是被锁保护的;
当你获得一个对象的引用时,你要知道用它来做什么,是否需要在使用它前先获得一个锁?是否允许修改它的状态,还是仅仅可读?很多并发错误都是源自没有理解共享对象的这些“预设约束”。当你发布一个类后,应该将如何访问它们写入文档。
在并发程序中,使用和共享对象的一些最有效的策略是:
线程受限(Thread-confined):线程受限的对象只能被一个线程排它使用与独占,即不可共享对象,如方法中的局部变量就是。
只读共享(Shared read-only):一个只读共享的对象能够被并发地被多个线程在没有额外同步的情况访问,但不能被任何线程修改。共享只对读对象包括不可变和高效不可变对象。
线程安全共享(Shared thread-safe):一个线程安全的对象在内部已经进行了同步,所以其他线程无须额外同步,就可以通过它提供的公共接口无需在同步的情况下访问。
被守护的(Guarded):一个被守护的对象只能通过特定的锁来访问。被守护的对象包括那些被其他线程安全对象封装的对象和已知被特定锁保护起来的已发布的对象。
有时一个线程安全类支持我们需要的全部操作,但是更多时候,一个类只支持我们需要的大部分操作,这时我们需要在不破坏其线程安全性的前提下,向它添加一个新的操作。
现在假设我们需要一个线程安全的List,它需要提供给我们一个原子的“缺少即加入(put-if-absent)”操作,该如何做?
第一种方式:扩展Vecotr
@ThreadSafe
public class BetterVector<E> extends Vector<E> {
public synchronized boolean putIfAbsent(E x) {
boolean absent = !contains(x);
if (absent)
add(x);
return absent;
}
}
第二种方式:客户端自己加锁
@ThreadSafe
public class ListHelper<E> {
public List<E> list =
Collections.synchronizedList(new ArrayList<E>());
...
public boolean putIfAbsent(E x) {
synchronized (list) {
boolean absent = !list.contains(x);
if (absent)
list.add(x);
return absent;
}
}
}
第三种方式,也是最好的方式,组合加实现:
ImprovedList通过将操作委托给底层的List实例,并实现了List接口,同时还添加了一个原子操作putIfAbsent。(这种方式就像Collections.synchronizedList和其他容器封装那样)
@ThreadSafe
public class ImprovedList<T> implements List<T> {//实现
private final List<T> list;//组合
public ImprovedList(List<T> list) { this.list = list; }
public synchronized boolean putIfAbsent(T x) {
boolean contains = list.contains(x);
if (contains)
list.add(x);
return !contains;
}
public synchronized void clear() { list.clear(); }
// ... 类似地将其他方法也委托给List相应的方法
}
以下是第16章 Java内存模式内容
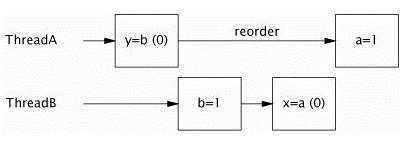
Java语言规范规定了JVM要维护内部线程类似顺序化语意:只要程序的最终结果等同于它在严格的顺序化环境中执行的结果,那么对指令的重新排序的行为是允许的。
public class PossibleReordering {
static int x = 0, y = 0;
static int a = 0, b = 0;
public static void main(String[] args)
throws InterruptedException {
Thread one = new Thread(new Runnable() {
public void run() {
a = 1;
x = b;
}
});
Thread other = new Thread(new Runnable() {
public void run() {
b = 1;
y = a;
}
});
one.start(); other.start();
one.join(); other.join();
System.out.println("( "+ x + "," + y + ")");
}
}
图解上面程序是如何输出 (0, 0)的:
Java存储模型定义了一系列的动作(actions),包括变量的读和写、监视器加锁和释放锁、线程的启动和连接(join).
要想保证执行动作B的线程看到动作A的结果(无论A和B是否发生在同一个线程中),A和B之间就必须满足happens-before关系。如果两个操作之间并未依照happens-before关系排序,JVM可以对它们随意地重排序。
当一个变量被多个线程读取,且至少被一个线程写入时,如果读写操作并未依照happens-before排序,就会产生数据竞争。一个正确同步的程序是没有数据竞争的程序,正确同步的程序会表现出顺序的一致性。
happens-before的法则包括:
1、 程序次序法则:线程中的每个动作A都happens-before于该线程中每个动作B,其中,在程序中,所有动作B都出现在动作A之后。
2、 监视器锁法则:对一个监视器锁的解锁happens-before于每个后续对同上监视器锁的加锁。
3、 volatile变量法则:对volatile域的写入操作happens-before于每一个后续对同一域的读操作。
4、 线程启动法则:在A线程中调用B线程的start方法,则发生在A线程中的所有动作happens-before于B线程中的每个动作。
5、 线程终结法则:线程中的任何动作都happens-before于能检测到这个线程已经终结(从Thread.join调用中成功返回,或Thread.isAlive返回false)的任何线程。
6、 中断法则:一个线程调用另一个线程interrupt happens-before于被中断线程发现中断(通过InterruptedException,或者调用isInterrupted和interrupted来发现中断)。
7、 终结法则:一个对象的构造函数的结束happens-before 于这个对象的finalizer的开始。
8、 传递性:如果A happens-before 于B,且B happens-before 于 C,则 A happens-before 于 C。
下图演示了两个线程同步使用一个公共锁时,它们之间的happens-before关系。线程AB内部所有动作都是依照了“程序次序法则”进行排序的。因为A释放了锁M,B随后获取了锁M,A中所有释放锁之前的动作,也就因此排到了B中请求到锁后动作的前面。如果两个线程是在不同的锁上进行同步,则这两个线程的动作之间就不存在happens-before关系。
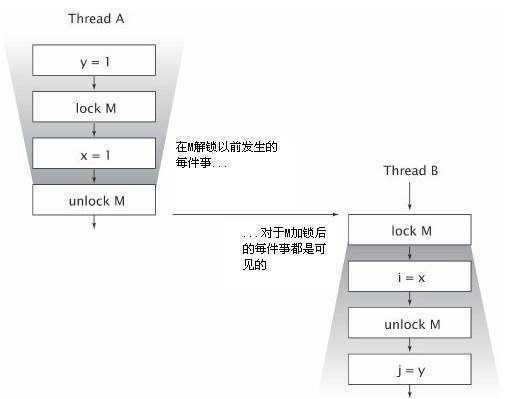
在缺少happens-before关系的情况下,存在重排序的可能性。这就解释了为什么如果在没有充分同步的情况下就发布一个对象,会导致另外的线程看到一个部分创建对象(即构建不完整对象)。
如果你不能保证发布共享引用happens-before于另外的线程读取这个共享引用,那么读取这个共享对象引用与初始化共享对象状态域可以被重排序(这里的重排序关键在于消费线程读取共享对象的引用动作与将构造期修改的状态值写回到主存中的动作是无序的,更准确一点是,按照正规则的语义是当构造器调用完毕后对象状态对象外界是可见的,但在未同步的情况下不能做到在构造函数结束前将状态域值写回到主存中去)(从使用该对象的线程的角度看),在这种情况下,另一个线程就会读到一个还未初始化完整的对象。
错误的惰性初始化会导致不正确的发布:
//不安全的惰性初始化
public class UnsafeLazyInitialization {
private static Resource resource;
public static Resource getInstance() {
if (resource == null)
resource = new Resource(); // 不安全的发布
return resource;
}
}
上面的程序有二个问题:第一个是可能创建出多个Resource;第二个问题是其他线程看到一个构建不完整的对象。
前面描述的安全发布的常用模式,可以确保发布的对象对于其他线程是可见的,因为它们保证发布对象happens-before于消费线程加载已发布对象的引用。
借助于类库中现在的同步容器、使用锁保护共享变量、或都使用共享的volatile类型变量,都可以保证对该变量的读取和写入是按照happens-before排序的。
happens-before事实上可以比安全发布承诺更强的可见性与排序性。如果X对象从A线程到B线程是安全发布的,安全发布可以保证X本身的状态是可见的,但是不包括A所依赖的其他对象(即A中还包含了其他对象,不只是基本类型变量)的状态;但是如果X对象是在同步的情况下由线程A生产,然后由线程B消费,B不仅仅能看到A中所有直接状态域,而且还能看见A所依赖的甚至是更深一层的状态域所做的更改。
使用静态域来初始化,会有的额外的线程安全性保证。静态初始化是JVM完成的,发生在类的初始化阶段(加载、链接、类的初始化),即类被加载后到类被任意线程使用之前。JVM会在初始化期间获得一个锁,这个锁每个线程都至少会获取一次,来确保类是否已被加载;这个锁也保证了静态初始化期间,内存写入的结果自动地对照所有线程都是可见的。所以静态初始化的对象,无论是构造期间还是被引用的时候,都不需要显试地进行同步。然而,这仅仅适用于构造当时的状态——如果对象是可变的,为了保证后续修改的可见性,仍然需要同步。
@ThreadSafe//主动初始化
public class EagerInitialization {
private static Resource resource = new Resource();
public static Resource getResource() { return resource; }
}
主动初始化,避免了懒汉式每次调用getInstance时引发的同步开销,如下面:
@ThreadSafe
public class SafeLazyInitialization {
private static Resource resource;
public synchronized static Resource getInstance() {
if (resource == null)
resource = new Resource();
return resource;
}
}
将主动初始(饿汉式)技术与JVM的惰性类加载相结合,创建出一种惰性初始化技术:
@ThreadSafe
public class ResourceFactory {
private static class ResourceHolder {
public static Resource resource = new Resource();
}
public static Resource getResource() {
return ResourceHolder.resource ;
}
}
JVM将ResourceHolder的初始化被延迟到真正使用它的时刻了。又因为Resource是在静态初始阶段进行初始化的,所以不再需要额外的同步。线程第一次调用getResource,才会引起ResourceHolder的加载和初始化,这个时候,正是在静态初始阶段Resource完成初始化发生的时间。
保证了初始化的安全,就可以让正确创建的不可变对象在没有同步的情况下,可以被安全地跨线程地共享,而不管它们是如何发布的——甚至在发布时存在数据竞争。(这就是说如果Resource 是不可变的,上面的UnsafeLazyInitialization事实上也可以是安全的)
假如没有初始化安全性,就会发生这样的事情:像String这样不可变对象,没有在发布或消费线程中进行同步,它们的值可能表现出变化的性为。(为了确保初始化的安全,所以在1.5中String中的域都已修改成了final了)
初始化安全可以保证,对于正确创建的对象,无论它是如何发布的,所有线程都将看到构造函数设置的final域的值。更进一步,一个正确创建的对象中,任何可以通过其final域访问得到的变量(比如一个final数组中的元素,或者一个final域引用的HashMap里面的内容),也可以保证对其他线程都是可见的。
对于含有final域的对象,安全初始化禁止了在构造器中将final域写回到主存动作与获取引用动作间的重排序,会按照程序的语义——先构造,再引用的,的顺序先去构造完对象,然后再获取该对象的引用,而final域又是在构造器中初始化的,而JVM内存模型又对final作出了明确的可见性规定——当构造完后final域对其他线程一定是可见的,所以final写回主存的动作会happens-before于获取对象的引用。
安全初始化只能保证那些final域及它可以访问得到的其他域,在构造函数完成时才是可见的。对于那些非final,或者即使是final域但创建完成后会修改的,必须使用同步来确保可见性。
平台类库中包含了一个并发构建块的丰富集合,如线程安全的容器与同步工具。
分两部分,一是JDK1.0的Vector与Hashtable,另一个是JDK1.2才被加入的同步包装类Collections.synchronizedXxx工厂方法创建的。Collections.synchronizedXxx工厂方法构造出的容器返回的List与Set的iterator()与listIterator()(List集合)没有使用同步。
同步容器都是线程安全的,但是对于复合操作,有可能客户端需要使用额外的加锁进行保护。如迭代、putIfAbsent(如果不存在则加入)等,这有点像事务要做在Service层而不能做在Dao层一样的道理。
操作Vector(同步容器)的复合操作可能导致混乱的结果:
public static Object getLast(Vector list) {
int lastIndex = list.size() - 1;
return list.get(lastIndex);
}
在多线程的环境下可能会抛出ArrayIndexOutOfBoundsException,因为基他线程可能会在size()与get中修改Vector,但单线程下是不会有问题的。
使用客户端加锁,对Vector进行复合操作:
public static Object getLast(Vector list) {
synchronized (list) {
int lastIndex = list.size() - 1;
return list.get(lastIndex);
}
}
多线程环境下迭代过程中也可能抛出ArrayIndexOutOfBoundsException:
for (int i = 0; i < vector.size(); i++)
doSomething(vector.get(i));
迭代过程中可能抛出异常,但并不意味着Vector就不是线程安全。Vector的状态仍然是有效的,事实上异常恰好使它保持规范的一致性。然而,在正常或迭代读过程中抛出异常的确不是人们所期望的。
造成迭代不可靠的问题同样可以通过在客户端加锁来完成,这要增加一些开销,像下那样,通过在迭代期间持有Vector的锁,我们防止其他线程在迭代期间修改Vector,这样完全阻止了其他线程在这期间访问它,如果集合很大或者对每个元素执行的任务耗时比较长,这会削弱并发性
synchronized (vector) {
for (int i = 0; i < vector.size(); i++)
doSomething(vector.get(i));//还要持有另一个锁,这是一个产生死锁风险的因素
}
尽管上面讨论的Vector是“遗留”下来的容器类,这只是说明同步容器有这样的问题。其实,“现代”的容器类也并没有消除复合操作产生的问题,比如迭代复合操作,当其他线程并发修改容器时,使用迭代器仍然避免不了在使用的地方加锁,在设计同步容器返回迭代器时,并没有使用同步(注,这里讲的是说返回的迭代器不是线程安全,而不是指返回迭代器的方法iterator() 没有使用同步,它本身就是经过同步了的。),因为他们是“及时失败”——只要有其他线程修改容器结果,立马就会抛出未检查性异常ConcurrentModificationException。
注:ConcurrentModificationException也可能出现在单线程的代码中,如果对象不是调用Iterator.remove,而是直接从容器中删除就会出现这种情况。
1.5中的for-each循环语法对容器进行迭代时,也是隐式地用到了Iterator,所以在多线程下也需要同步:
List<Widget> widgetList = Collections.synchronizedList(new ArrayList<Widget>());
...
// May throw ConcurrentModificationException
for (Widget w : widgetList)
doSomething(w);
迭代期间,对容器加锁的一个替代办法就是复制容器。注,复制期间也需要加锁。复制容器会有明显的开销;这样做是好是坏取决于许多因素,包括容器的大小、每一个元素的工作量等。
在一个可能发生迭代的共享容器中,各处都需要锁,这是一个棘手的问题,因为迭代器有时是隐藏的,就像下面代码一样,容器的toString方法的实现是通过迭代容器中的每个元素。如果将HashSet包装为synchronizedSet就不会出现ConcurrentModificationException异常了。
public class HiddenIterator {
private final Set<Integer> set = new HashSet<Integer>();
public synchronized void add(Integer i) { set.add(i); }
public void addTenThings() {
Random r = new Random();
for (int i = 0; i < 10; i++)
add(r.nextInt());
System.out.println("DEBUG: added ten elements to " + set);//这里会隐式地使用迭代
}
}
容器的hashCode和equals方法也会间接地调用迭代,比如当容器本身作为一个元素时,或者是作为另一个容器的key时。类似地,containsAll、removeAll、retainAll方法,以及把容器做为参数的构造函数,都会对容器进行隐式地迭代,所以都会抛出ConcurrentModificationException异常。
1.5提供了几个并发的容器类来改进同步容器。同步容器通过对容器的进行串行访问,从而实现了它们的线程安全。这样做虽然是绝对的安全,但代价是削弱了并发性,当多个线程共同竞争容器级的锁时,吞吐量会降低。
并发容器是为多线程并发访问而设计的。1.5添加了ConcurrentHashMap,来替代同步的哈希Map实现;当大多数的操作是读操作时(因为如果有很多写操作会引起内部对原来集合进行复制,从而带来开销),CopyOnWriteArrayList是List相应的同步实现,同样CopyOnWriteArraySet是Set相应的同步实现(内部是以CopyOnWriteArrayList来实现的)。并且在ConcurrentMap接口还加入了对常见复合操作的支持,如“缺少即加入 put-if-absent”、替换和条件删除。
用并发容器替换同步容器,这种作法以很小的风险带来了可扩展性显著的提高。
1.5同时增加了两个新的容器类型:Queue和BlockingQueue(Queue接口继承了Collection接口)。有几种实现,一个传统意义上(入队与出队不会被阻塞,是相对阻塞队列来说的)的FIFO队列ConcurrentLinkedQueue,底层是基于链表结构;一个是有优先级顺序的队列PriorityQueue(注,它不支持非并发)。Queue的操作不会阻塞,如果队列是空,那么从队列中获取时返回null。尽管可以使用List来模拟Queue的类——事实上,LinkedList就已实现了Queue(如果我们只需要一个单纯的或者是传统意义上的队列时,我们应该使用LinkedList,如果我们需要在并发环境下,则使用ConcurrentLinkedQueue来代替它)——但我们还是需要Queue的类,因为如果忽略掉List的随机访问需求的话,使用Queue能得到高效的并发实现。
Queue接口:
|
element() |
|
|
boolean |
|
|
peek() |
|
|
poll() |
|
|
remove() |
BlockingQueue接口:
|
|
|
|
|
|
|
|
|
|
|
BlockingQueue扩展了Queue,增加了可阻塞的插入(put)和获取操作(take)。如果队列为空,则take阻塞;如果队列满(对于有限队列:LinkedBlockingQueue—可以不指定,不指定时容量为最大的Integer.MAX_VALUE、ArrayBlockingQueue构造时则一定要指定大小),put操作会阻塞直到有空间,而对于无界队列(PriorityBlockingQueue、DelayQueue),放入时不会被阻塞,直到OutOfMemoryError。阻塞队列在生产者——消费者设计中非常有用。
正如ConcurrentHashMap作为同步的哈希Map的一个替代,1.6加入了ConcurrentSkipListMap和ConcurrentSkipListSet,用来作为同步的SortedMap和SortedSet的并发替代品(用synchronizedMap包装的TreeMap或TreeSet)
同步容器类在每个操作的执行期间都持有一个锁。比如HashMap.get或者List.contains操作,再调用它们的过程中可能需要很长一段时间,并且在这段时间内,其他线程都不能访问这个容器。
ConcurrentHashMap和HashMap一样是一个哈希表,但是它使用完全不同的锁策略,可以提供更好的并发性和或伸缩性。以前的同步容器在内部只有一把锁,即容器自身,而ConcurrentHashMap使用一个更加细化的锁机制,名叫“锁分离”。这种机制允许更深层次的共享访问。任意数量的读线程可以并发访问Map,读和写线程可以并发访问Map,并且有限数量的写线程还可以并发修改Map。这样为并发访问带来了更高的吞吐量,同时几乎没有损失单个线程访问的性能。
ConcurrentHashMap提供了不会抛出ConcurrentModificationException异常的迭代器,因此不需要在容器迭代时加锁访问,它所返回的迭代器是弱一致性的,而非“及时失败”的。弱一致性的迭代可以允许并发修改,当迭代器被创建时,它会遍历已有的元素,并且可以(但是不保证)感应到在迭代器被创建后,对容器的修改。
尽管有这么多改进,但有一些还是需要权衡的地方。那些对整个Map进行操作的方法,如size和isEmpty,它们的语义在反映容器并发特性被弱化了。因为size的结果相对于在计算的时候可能已经过期,它仅仅只是一个估算值,所以允许size返回一个近似值而不是一个精确的值。这在一开始会让人有些困扰,不过事实上像size和isEmpty这样的方法在并发环境下几乎没有什么用处,因为它们的目标是在于并发的读与写,所以这些操作的原子性被弱化了。相反,应该保证对最重要的操作进行性能优化,最重要的是get、put、containsKey和remove。
相比于Hashtable和synchronizedMap,ConcurrentHashMap有很多的优势,因此大多数情况下ConcurrentHashMap取代同步Map实现只会带来更好的可伸缩性。只有当你程序需要独占访问中加锁时,ConcurrentHashMap才无法胜任。
因为ConcurrentHashMap不能被独占访问,所以我们不能在客户端加锁来创建新的原子操作,比如我在前面对Vector复合操作施加的原子性。不过一些常的复合操作,如“缺少即加入”、“相乘便移除”和“相等便替换”等都已被实现为原子操作。如果你正在已同步Map中加入这些功能时,你可能考虑使用ConcurrentHashMap来替代同步的Map。
public V putIfAbsent(K key, V value) :如果键不存在,则关联
public boolean remove(Object key, Object value) :如果键存在且值相等,则删除
public boolean replace(K key, V oldValue, V newValue) :如果键存在且值相等,则使用新的值替代旧值
public V replace(K key, V value) 如果键存在,则替换
CopyOnWriteArrayList是同步List的一个并发替代品,在通常情况下提供了更好的并发性,并避免了在迭代期间对容器加锁和复制.。相似地,CopyOnWriteArraySet是同步Set的一个并发替代,它是对CopyOnWriteArrayList包装,所有的操作都是转换给CopyOnWriteArrayList,与CopyOnWriteArrayList没什么区别。
“写入时复制 copy-on-write”容器的线程安全性保障是有要求的:只要将不可变对象正确的发布,那么访问它将不再需要同步。在每次修改时,所有对象它们的修改线程都会拥有一个底层数据的拷贝,以此来实现可变性。当集合上的迭代线程数目大大多于修改线程时,这种安排就显得十分有用了。
它们的迭代器保留容器底层基础数据的另一拷贝引用(注,仅仅是浅拷贝),这个数组永远不会被修改,因此对它的同步只不过是为了确保数组内容的可见性。因此,多个线程可以对这个容器进行迭代,并且不会受到另一个或多个想要修改容器的线程的影响。并且迭代时不会抛出ConcurrentModificationException异常,并且返回的元素严格与迭代器创建时相一致(但是如果元素本身是可变的则不一定),不会考虑后续的修改。
CopyOnWriteArrayList<StringBuffer> cwa = new CopyOnWriteArrayList<StringBuffer>();
cwa.add(new StringBuffer("0"));
Iterator<StringBuffer> it = cwa.iterator();
cwa.get(0).append("1");
cwa.add(new StringBuffer("3"));
while (it.hasNext()) {
// 不会抛异常,那怕在迭代创建后修改了结构,并只输出 01
System.out.println(it.next());
}
在每次对容器修改时都会复制底层基础数组,这需要开销,特别是对大容器,所以只有当对容器替代操作的频率远远高于对容器修改的频率时,使用“写入时复制”容器是个合理的选择。
Queue继承体系结构:
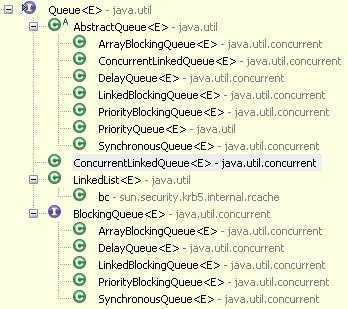
队列是一种数据结构,它有两个基本操作:在队列尾部加人一个元素,和从队列头部移除一个元素就是说,队列以一种先进先出的方式管理数据,如果你试图向一个已经满了的阻塞队列中添加一个元素或者是从一个空的阻塞队列中移除一个元索,将导致线程阻塞.在多线程进行合作时,阻塞队列是很有用的工具。工作者线程可以定期地把中间结果存到阻塞队列中而其他工作者线线程把中间结果取出并在将来修改它们。队列会自动平衡负载。如果第一个线程集运行得比第二个慢,则第二个线程集在等待结果时就会阻塞。如果第一个线程集运行得快,那么它将等待第二个线程集赶上来。下表显示了jdk1.5中的阻塞队列的操作:
add增加一个元素如果队列已满,则抛出一个IIIegaISlabEepeplian异常
remove移除并返回队列头部的元素如果队列为空,则抛出一个NoSuchElementException异常
element返回队列头部的元素如果队列为空,则抛出一个NoSuchElementException异常
offer添加一个元素并返回true如果队列已满,则返回false
poll移除并返问队列头部的元素如果队列为空,则返回null
peek返回队列头部的元素如果队列为空,则返回null
put添加一个元素如果队列满,则阻塞
take移除并返回队列头部的元素如果队列为空,则阻塞
remove、element、offer 、poll、peek 其实是属于Queue接口,这些方法都不会阻塞。
队列Queue接口与List、Set同一级别,都是继承了Collection接口。LinkedList现已经实现了Queue接口。Queue接口窄化了对LinkedList的方法的访问权限(即在方法中的参数类型如果是Queue时,就完全只能访问Queue接口所定义的方法了,而不能直接访问LinkedList的非Queue的方法),以使得只有恰当的方法才可以使用。BlockingQueue 继承自Queue接口。
阻塞队列的操作可以根据它们的响应方式分为以下三类:aad、removee和element操作在你试图为一个已满的队列增加元素或从空队列取得元素时抛出异常。当然,在多线程程序中,队列在任何时间都可能变成满的或空的,所以你可能想使用offer、poll、peek方法。这些方法在无法完成任务时只是给出一个出错示而不会抛出异常。
注意:poll和peek方法出错进返回null。因此,向队列中插入null值是不合法的。
还有带超时的offer和poll方法变种,例如,下面的调用:
boolean success = q.offer(x,100,TimeUnit.MILLISECONDS);
尝试在100毫秒内向队列尾部插入一个元素。如果成功,立即返回true;否则,当到达超时进,返回false。同样地,调用:
Object head = q.poll(100, TimeUnit.MILLISECONDS);
如果在100毫秒内成功地移除了队列头元素,则立即返回头元素;否则在到达超时时,返回null。
最后,看看阻塞操作put和take。阻塞队列提供了可阻塞的put和take方法,它们与可定时的offer和poll是等价的。如果Queue已经满了,put方法会阻塞直到有空间可用;如果是空,那么take方法会被阻塞直到有元素可用;而带有时间参数的offer与poll在没有空间或为空时,会阻塞到指定时间时返回。Queue的长度可以有限,也可以无限,无限的put方法将不会被阻塞。
生产者—消费者模式将“需要完成的工作”和“执行工作”分开。他简化了开发,消除了生产者与消费都之间的代码依赖。并解决了产生与消费在速度上不匹的问题。
最常见的生产者-消费者设计是将线程池与工作队列相结合起来(据我所知,Executor框架有以下地方用到了池:池中的线程就是放在队列中的,但Executor的任务提交后不是会放入队列中,而是立刻准备执行;ScheduledExecutorService定制的计划任务会放入工作队列中,等到延迟到达后执行;另外CompletionService处理完后的结果会放在队列中),讲述Executor任务执行框架时会具体介绍这个模式。
如果生产者产生工作的速度总是比消费者处理的速度快,那么任务放在没有边界的队列中最终会耗尽内存,如果我们此时使用有界的列队,当队列充满时则put会阻塞,从而消费者有时间追上进度。
阻塞队列同样提供了一个offer方法,如果加入不成功则返回失败,这样就给我们带了处理任务上的灵活,比如将未放入的任务序列化到磁盘、减少生产者线程、增加消费线程等。
有界队列是强大的资源管理器,用来建立可靠的应用程序:它会遏制那些产生多的工作量、具有威胁的活动,从而让你的程序在而对超负荷工作进更加的健壮。
类库中中包含一些BlockingQueue的实现:
LinkedBlockingQueue,底层基于链表结构的阻塞队列,默认情况下容量是没有上限的(说的不准确,在不指定时容量为Integer.MAX_VALUE,要不然的话在put时怎么会受阻呢),但是也可以选择指定其最大容量,它是基于链表的队列,此队列按 FIFO(先进先出)排序元素。
ArrayBlockingQueue,底层基于数组结构的阻塞队列,在构造时需要指定容量,并可以选择是否需要公平性,如果公平参数被设置true,等待时间最长的线程会优先得到处理(其实就是通过将ReentrantLock设置为true来达到这种公平性的:即等待时间最长的线程会先操作)。通常,公平性会使你在性能上付出代价,只有在的确非常需要的时候再使用它。它的底层基于数组的阻塞循环队列,此队列按 FIFO(先进先出)原则对元素进行排序。
PriorityBlockingQueue,它是基于PriorityQueue来实现的,而PriorityQueue优先队列底层是基于堆数据结构的,是一个带优先级的队列,而不是先进先出队列。元素按优先级顺序被移除,该队列也没有上限(因PriorityQueue是没有容量限制的,与ArrayList一样,所以在优先阻塞队列上put时是不会受阻的。虽然此队列逻辑上是无界的,但是由于资源被耗尽,所以试图执行添加操作可能会导致 OutOfMemoryError),但是如果队列为空,那么取元素的操作take就会阻塞,所以它的检索操作take是受阻的。另外,放入的元素要具有比较力或构建队列时指定一个Comparator比较器。
DelayQueue,也是基于PriorityQueue来实现的,是一个存放Delayed 元素的无界阻塞队列,只有在延迟期满时才能从中提取元素。该队列的头部是延迟期满后保存时间最长的 Delayed 元素。如果延迟都还没有期满,则队列没有头部,并且poll将返回null。当一个元素的 getDelay方法返回一个小于或等于零的值时,则出现期满,poll就以移除这个元素了。此队列不允许使用 null 元素。下面是Delayed接口:
public interface Delayed extends Comparable<Delayed> {
long getDelay(TimeUnit unit);
}
另外关于的介绍请参考:定时周期性任务章节最后。
最后一个BlockingQueue的实现是SynchronousQueue,但它根本上不是一个真正的队列,因为这个类没有存储元素的空间。不过,它维护一个排队的线程清单,这些线程等待把元素加入队列或者移出队列。这好比在洗盘子时,没有盘架子(在生产者与消费者模式中相当于它们之间的缓冲区)一样,却是直接将洗好的盘子放入烘干机。这种直接地移交工作,减少了在生产者和消费者之间移动数据的延迟时间。另外直接移交任务同样会给生产者带来更多关于任务状态的反馈信息,当移交被接受,它就知道消费者已经得到了任务,而不是简单地把任务放在一个队列或是什么其他地方。因为SynchronousQueue没有存储能力,所以除非另一个线程已经准备好参与移交工作,否则put和take会一直阻塞。SynchronousQueue这类队列只有在消费者充足的时候比较合适,因为这样总能为下一个任务移交做好准备(而生产者是主动发起,发不发起及什么时候发起移交动作由生产者来决定,所以只需要有够的消费者,而生产者多还是少不重要)。具体示例请参考:SynchronousQueue(同步队列)章节。
/**
* @author jiangzhengjun
* @date 2010-6-11
*/
public class TestLinkedBlockingQueue {
// 随机获取字母
private static char getChar() {
return (char) (Math.random() * 26 + 65);
}
// 随机睡几秒
private static void sleep() {
try {
Thread.sleep((long) (Math.max(500, Math.random() * 1000)));
} catch (InterruptedException e) {
e.printStackTrace();
}
}
private static class Producer implements Runnable {// 生产者
private BlockingQueue<String> sq;
public Producer(BlockingQueue<String> d) {
this.sq = d;
}
public void run() {
try {
while (!Thread.currentThread().isInterrupted()) {
sq
.put(Thread.currentThread().getName() + " - "
+ getChar());
sleep();
}
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
private static class Consumer implements Runnable {// 消费者
private BlockingQueue<String> sq;
public Consumer(BlockingQueue<String> d) {
this.sq = d;
}
public void run() {
try {
while (!Thread.currentThread().isInterrupted()) {
System.out.println(Thread.currentThread().getName() + " - "
+ sq.take());
sleep();
}
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
public static void main(String[] args) {
// LinkedBlockingQueue阻塞队列,可换成其他阻塞队列
BlockingQueue<String> sq = new LinkedBlockingQueue<String>();
Thread t = null;
for (int i = 0; i < 2; i++) {
t = new Thread(new Producer(sq));
t.setName("Producer -" + i + "- ");
t.start();
t = new Thread(new Consumer(sq));
t.setName("Consumer -" + i + "- ");
t.start();
}
}
}
/**
* @author jiangzhengjun
* @date 2010-6-11
*/
public class TestPriorityBlockingQueue {
// 随机获取字母
private static char getChar() {
return (char) (Math.random() * 26 + 65);
}
public static void main(String[] args) throws Exception {
// 优先级队列
BlockingQueue<Character> sq = new PriorityBlockingQueue<Character>();
Map<Character, Character> hashMap = new HashMap<Character, Character>();
System.out.print("put - ");
for (int i = 0; i < 26; i++) {
char c = getChar();
while (hashMap.containsKey(c)) {
c = getChar();
}
hashMap.put(c, c);
System.out.print(c + " ");
sq.put(c);
}
System.out.println();
System.out.print("take - ");
for (int i = 0; i < 26; i++) {
System.out.print(sq.take() + " ");
}
}
} /*
put - D G Q X P I Z L K E T O W F Y N M B V S U J H A R C
take - A B C D E F G H I J K L M N O P Q R S T U V W X Y Z
*/
从上面的输出可以看出队与入队的顺序是不一样的,在入队时会将元素进行排序,这里按照字母的自然顺序排列,所以出出队时就是有顺的了。
/**
* @author jzj
* @date 2010-6-11
*/
public class TestDelayQueue {
// 放入DelayQueue的对象需实现Delayed接口
static class DelayObj implements Delayed {
long time;// 可从队列中取出的时间点
int id;
public int getId() {
return id;
}
// time的单位是秒
DelayObj(long time, int id) {
this.time = System.nanoTime() + TimeUnit.SECONDS.toNanos(time);
this.id = id;
}
public int compareTo(Delayed y) {
long i = time;
long j = ((DelayObj) y).time;
if (i < j)
return -1;
if (i > j)
return 1;
return 0;
}
public boolean equals(Object other) {
return ((DelayObj) other).time == time;
}
public long getDelay(TimeUnit unit) {
long n = time - System.nanoTime();// 剩余延迟时间
return unit.convert(n, TimeUnit.NANOSECONDS);
}
public long getTime() {
return time;
}
public String toString() {
return String.valueOf(time);
}
}
public static void main(String args[]) throws InterruptedException {
Random random = new Random();
DelayQueue<DelayObj> queue = new DelayQueue<DelayObj>();
for (int i = 0; i < 5; i++) {
queue.add(new DelayObj(random.nextInt(5), i));
}
long last = 0;
for (int i = 0; i < 5; i++) {
// 只有延迟时间点到后才会取出
DelayObj delay = queue.take();
//从延时时间到达至从队列中取出来使用所相隔时间
long tmpTime = System.nanoTime() - delay.getTime();
long t = delay.getTime();
System.out.println("DelayObj_" + delay.getId() + "- "
+ delay.getTime() + " " + tmpTime);
if (i != 0) {
// 打印后一个比前一个延迟了多少
System.out.println("Delay last: " + (t - last));
}
last = t;
}
}
} /*
DelayObj_2- 10380274830293 40575
DelayObj_0- 10381273985449 414310
Delay last: 999155156
DelayObj_3- 10381274835355 15126560
Delay last: 849906
DelayObj_4- 10381274839786 15205837
Delay last: 4431
DelayObj_1- 10384274818037 15111507
Delay last: 2999978251
*/
从上面的输出来看,取出的顺序与放入的顺序是完全不一样的,取出的顺序是依赖于DelayObj的延时时间点time的值,即哪个时间点在前就先取出哪个。
BlockingQueue的put和take方法会抛出一个受检查的InterruptedException,这与类库中的其他方法是相同的,比如Thread.sleep。当一个方法能够抛出中断异常时,是在告诉你这个方法是一个可阻塞方法,并且,如果它被中断,将可以提前结束阻塞状态。
中断只是一种请求或者是一种提醒,中断方法是不会真真将某个线程立即停止掉。中断的结果线程是死亡、还是等待新的任务或是继续运行至下一步,就取决于这个程序本身。
如果当你的代码调用的方法抛出了InterruptedException异常,则意味着你的方法也就是一个阻塞方法了。处理InterruptedException异常的方式有以下几种:
1、 传递——可以不捕获InterruptedException异常,也可以先捕获然后做一些处理后再次抛出。
2、 恢复中断——有时你不能抛出InterruptedException异常,比如当你的代码是Runnable的一部分时。在这样的情况下,你必须捕获InterruptedException,并且,在当前线程中通过调用线程的interrupt从中断中恢复,这样高层代码将会发现中断已经发生。
以上是两种差不多可以对付大多数情况了,但是你不应该捕获InterruptedException后,不作任何响应,这样的话会丢掉线程中断的证据,从而剥夺了上层栈的代码处理中断的机会,除非你的代码是最高层代码。
详细的中断线程请参见这里XXXXXXXXXXXXXXXXXXX
java.util.concurrent包包含了若干能够帮助人们来管理线程相互合作的类。如果有一个相互合作的线程集,它又满足这些行为模式中的一种,那么应该直接重用合适的库类而不要去试图手工维护。
Class
它能做什么
何时使用它
CyclicBarrier
允许一个线程集等待直至其中预定数量的线程达到一个公共检障栅为止,然后可以选择执行一个处理障栅的动作
当大量的线程需要在它们的结果可用之前完成时
CountDownLatch
允许一个线程集等待直到计数器减为0为止
当一个或多个线程需要等待直到制定数量的结果可用为止
Exchanger
允许两个线程在要交换的对象准备好时交换对象
当两个线程工作在同一个数据结构的两个实例上时,一个向实例中添加数据,另一个将数据从实例中清除
SynchronousQueue
允许一个线程将对象交给另一线程
在没有同步的情况下,当两个线程准备好将一个对象从一个线程会给另一个时
Semaphore
允许线程集等待直到允许继承运行为止
用来限制访问资源的线程总数。如果许可是1,则阻塞线程直到另一个线程给出许可为止
闭锁(Latch),它可以延迟线程的进度直到线程到达终止状态。一个闭锁工作方式就像一道大门,直到闭锁到达终点状态之前,门一直关闭着,没有线程能够通过,终点状态到来的时候,门开了,允许所有线程都可以通过。一旦闭锁到达了终点状态,它就不能够再改变状态了,所以它会永远保持敞开状态,这与CyclicBarrier是不同的。闭锁可以用来确保特定的活动直到其他活动完成后才发生。
CountDownLatch 使用一个计数器来实现,它初始化为一个正,用来表示需要等待的活动事件数。countDown 方法使计数器减一,表示一个事件已经发生了,而await方法等待计数器达到零,此时表示所有需要等待的事件都已发生,只有当计数器到达零时,锁才会开起。如果计数器的初始值不为零,await会一直阻塞直到计数器为零,或者是等待线程中断或超时。
TestHarness展示了两种常见的用法。它有两个闭锁,一个是“开始阀门”和一个“结束阀门”,开始阀门将计数器初始化为1,结束阀门将计数器初始化为工作线程的数量。每个工作线程要做的第一件事是等待开始阀门的打开;这样做能确保所有线程都准备后才开始工作。每个线程的最后一个工作是为结束阀门减一,这样做会即时知道所有工作线程是都完成,这样就能计算事个耗时了。
public class TestHarness {
public static long timeTasks(int nThreads, final Runnable task)
throws InterruptedException {
final CountDownLatch startGate = new CountDownLatch(1);// 开始阀门
final CountDownLatch endGate = new CountDownLatch(nThreads);// 结束阀门
for (int i = 0; i < nThreads; i++) {
Thread t = new Thread() {
public void run() {
System.out.println(" " + System.currentTimeMillis());
try {
// 开始阀门,等待外界将阀门打开后(即所有线程都准备好后)
// 开始向下执行
startGate.await();
try {
task.run();
} finally {
// 当执行完后计数器减1
endGate.countDown();
}
} catch (Exception ignored) {
}
}
};
t.start();
}
long start = System.nanoTime();
startGate.countDown();//打开开始阀门
// 结束阀门,等待所有线程都完成后会自动打开
System.out.println("- " + System.currentTimeMillis());
endGate.await();
long end = System.nanoTime();
return end - start;
}
public static void main(String[] args) throws Exception {
System.out.println(timeTasks(10, new Runnable() {
public void run() {
}
}));
}
}/*
- 1276925505488
1276925505488
1276925505489
1276925505489
1276925505489
1276925505489
1276925505490
1276925505490
1276925505491
1276925505491
1276925505491
4738512
*/
上面为什么不在线程创建后就立即运行,还要像上面那样使用闭锁的方式?如果我们简单地创建线程并启动线程,那么先启动的就比后启动的具有“领先优势”,并且根据活动线程数据的增加或者减少,这样的竞争度也在不断改变。而开始阀门让控制线程能够同时释放所有工作线程,结束阀门让控制线程能够等待最后一个线程完成任务,而不需要自己去判断每个线程是否完成。
??但是要注意的是,上面还是不精确,因为从输出的结果可以看出startGate.countDown()是完全有可能在所有任务线程还没有开始前就已经先执行了,所有任务线程都聚集在一点后再同时执行在这里好像没有作到??下面是我改进后的结果:
public static long timeTasks(int nThreads, final Runnable task)
throws InterruptedException {
final CountDownLatch startGate = new CountDownLatch(1);// 开始阀门
final CountDownLatch taskStartGate = new CountDownLatch(nThreads);// 任务开始阀
final CountDownLatch endGate = new CountDownLatch(nThreads);// 结束阀门
for (int i = 0; i < nThreads; i++) {
Thread t = new Thread() {
public void run() {
System.out.println(" " + System.currentTimeMillis());
//只有所有任务线程执行此句后主线程才能继续执行
taskStartGate.countDown();
try {
// 开始阀门,等待外界将阀门打开后(即所有线程都准备好后)
// 开始向下执行
startGate.await();
try {
task.run();
} finally {
// 当执行完后计数器减1
endGate.countDown();
}
} catch (Exception ignored) {
}
}
};
t.start();
}
//确保所有任务线程都启动后(即进行了run方法)开始往后执行
taskStartGate.await();
System.out.println("- " + System.currentTimeMillis());
long start = System.nanoTime();
startGate.countDown();//打开开始阀门
// 结束阀门,等待所有线程都完成后会自动打开
endGate.await();
long end = System.nanoTime();
return end - start;
}
闭锁与障栅(CyclicBarrier)有下面向个不同点:
1、 不是所有线程(根据指定的线程数)都需要等待到闭锁打开为止
2、 闭锁可以由外部事件打开
3、 倒计时闭锁是一次性的,一旦计数器到达0,就不能再重用它了
闭锁Latch是一次性使用的对象,一旦进入到最终状态,就不能被重置了。
障栅类似于闭锁,它们都能够阻止一组线程,直到某些事件发生。与闭锁不同的是,所有线程必须都到达障栅后,才能继续处理。闭锁等待的则是事件,障栅等待的是其他线程。
CyclicBarrier在构造时需传递一个需在障栅点集合的线程数量,只有所有预定的线程都到达这个障栅点后,才可能往下执行,否则会被阻塞。
CyclicBarrier的await调用地方就是一个障栅点。如果所有线程都到达了障栅点,障栅就被成功地突破,这样所有线程都被释放,障栅会重置以备下一次使用。如果对await的调用超时或阻塞过程中被中断,那么障栅会失败,所有对await调用未完成的都抛出BrokenBarrierException异常而终止。如果所有线程都成功通过障栅,await为每一个线程返回一个唯一的到达索引号(其中,索引 getParties() - 1 指示将到达的第一个线程,零指示最后一个到达的线程)。CyclicBarrier 有一个可选的 Runnable 参数构造器,在一组线程中的最后一个线程到达之后(但在释放所有线程之前),该命令只在每个屏障点运行一次,若在任何参与线程继续执行之前更新共享状态,此屏障操作很有用。
下面是并行求和,它将数据根据CPU的内核数量分成多个任务后求和,一旦所有分段计算任务计算出结果后,就可以将每个任务的和进行汇总:
//并行计算
public class ConcurrentCal {
private final CyclicBarrier barrier;// 屏障
private final int cpuCoreNumber;// 待计算数组
private final int[] data;// 等计算数组
private final AtomicInteger sum = new AtomicInteger();// 和
// 计算任务
class SumCal implements Runnable {
private int[] numbers;
private int start;
private int end;
public SumCal(int num, final int[] numbers, int start, int end) {
this.numbers = numbers;
this.start = start;
this.end = end;
}
public void run() {// 求每小段数组的和
int tmpSum = 0;
for (int i = start; i < end; i++) {
tmpSum += numbers[i];
}
sum.getAndAdd(tmpSum);//存储每段和
try {
/*
* 在最后一个线程调用 await 方法之前,都将一直等待。只有当所有线
* 程都到达这里后才能通过
*/
barrier.await();
} catch (InterruptedException ex) {
return;
} catch (BrokenBarrierException ex) {
return;
}
}
}
public ConcurrentCal(int[] data) {
this.data = data;
cpuCoreNumber = Runtime.getRuntime().availableProcessors();// CPU内核数
this.barrier = new CyclicBarrier(cpuCoreNumber, new Runnable() {// 计算完后输出结果
/*
* 在最后一个线程到达之后,即触发点是最后一个线程调用await方法,并在该
* 方法中调用直接调用这个run方法(注,不会启动另一线程,而是直接在调用
* await方法线程中执行),且该命令只在每个屏障点运行一次
*/
public void run() {
System.out.println("计算完毕 sum=" + sum);
}
});
}
public void start() {
// 根据CPU核心个数拆分任务
for (int i = 0; i < cpuCoreNumber; i++) {
int increment = (data.length + 1) / cpuCoreNumber;
int start = increment * i;
int end = increment * i + increment;
if (end > data.length) {
end = data.length;
}
new Thread(new SumCal(i, data, start, end)).start();
}
}
public static void main(String[] args) {
int[] numbers = new int[] { 1, 2, 3, 4, 5, 6, 7, 8, 10, 11 };
new ConcurrentCal(numbers).start();
}
}
FutureTask实现了Runnable, Future两个接口
FutureTask同样可以作为闭锁。FutureTask的实现描述了一个抽象的可携带的结果的计算。FutureTask计算是通过Callable来实现的,它等价于一个可携带结果的Runnable,并有三个状态:等待、运行、完成,而完成包括正常结束、取消、异常。一旦进行完成状态,就会永永远停止在这个状态上。
FutureTask.get的行为依赖于任务的状态,如果它已经完成,便可立即返回结果,否则会被阻塞直到任务完成后返回结果或者抛出异常。
FutureTask把计算结果从运行计算的线程传送到了需要这个结果的线程,同时FutureTask保证了返回的对象是已经初始化完整的对象,可以心使用。
Executor框架利用了FutureTask来完成异步任务,并可以用来进行任何潜在的耗时计算,而且可以在真正需要计算结果之前就启动它们开始预先计算。
使用FutureTask预载稍后需要的数据:
public class Preloader {
private final FutureTask<ProductInfo> future =
new FutureTask<ProductInfo>(new Callable<ProductInfo>() {
public ProductInfo call() throws DataLoadException {
return loadProductInfo();
}
});
private final Thread thread = new Thread(future);
//不要在构造器中或静态初始化方法中启动线程,所以提供了这个单独的启动方法
public void start() { thread.start(); }//可以在get方法之前预先异步执行,等到调用get时结果已经准备后或者只需要等待很短的时间了
public ProductInfo get() throws DataLoadException, InterruptedException {
try {
//get会抛出三种异常:ExecutionException - 如果计算抛出异常;InterruptedException - 如果当前的线程在等待时被中断;以及非捕获性异常CancellationException - 如果计算被取消。
return future.get();
} catch (ExecutionException e) {// ExecutionException表示只要是计算过程的异常都会封装在这里面,再被Future.get重新抛出
Throwable cause = e.getCause();
if (cause instanceof DataLoadException)
throw (DataLoadException) cause;
else
throw launderThrowable(cause);
}
}
}
/** 如果Throwable是Error则抛出;如果是
* RuntimeException 则返回;其他情况抛出IllegalStateException
*/
public static RuntimeException launderThrowable(Throwable t) {
if (t instanceof RuntimeException)
return (RuntimeException) t;
else if (t instanceof Error)
throw (Error) t;
else
throw new IllegalStateException("Not unchecked", t);
}
使用信号量进行同步和互斥的控制是最经典的并发模型,java中也提供支持。相当于操作系统中的PV操作原语。
计数信号量用来控制能够同时访问某特定资源的线程的数量,它可以用来实现资源池或者给一个容器限定边界。
一个Semaphore管理一个有效的许可(permits)集,许可初始量通过构造函数传入,通过acquire方法申请一个许可(相当于PV操作原语中的P操作,即申请一个资源),许可数为0则阻塞线程,否则许可获取成功后要使用release方法释放一个许个(相当于PV操作原语中的V操作,即释放资源),这时许可数就加一。
通俗一点讲,许可就像一个令牌,谁拿到令牌(acquire)就可以去执行了,如果没有令牌则需要等待。执行完毕,一定要归还(release)令牌,否则令牌会被很快用光,别的线程就无法获得令牌而执行下去了。
计算信息量的一种退化形式就是二元信号量:一个计数量为1的Semaphore为二元信号量,相当于一个互斥锁,表示不可重入的锁,谁拥有了这个唯一许可,就拥有了互斥锁。请参考PV操作对单缓冲的同步与互斥XXXXXXXXXXXXXXXXX
下面使用Semaphore把任何容器转换为有界的阻塞容器:
public class BoundedHashSet<T> {
private final Set<T> set;
private final Semaphore sem;
public BoundedHashSet(int bound) {
this.set = Collections.synchronizedSet(new HashSet<T>());
sem = new Semaphore(bound);// bound为容器允许的最大容量
}
public boolean add(T o) throws InterruptedException {
sem.acquire();//如果容器满后则阻塞
boolean wasAdded = false;
try {
wasAdded = set.add(o);
return wasAdded;
}
finally {
if (!wasAdded)//如果添加不成功,则释放刚刚获取的信号量
sem.release();
}
}
public boolean remove(Object o) {
boolean wasRemoved = set.remove(o);
if (wasRemoved)//如果删除成功,则需要释放一个信号量
sem.release();
return wasRemoved;
}
}
Exchanger是两个线程可以交换对象的同步点。每个线程都在进入 exchange 方法时给出某个对象,相互接受对方准备的对象。
当两个线程工作在同一个数据缓冲区的两个实例上时,就可以使用交换器。典型情形是,一个线程向缓冲区中添加数据,另一个线程消费掉这些数据,当它们都完成后,它们相互交换缓冲。
Exchanger 可能被视为 SynchronousQueue 的双向形式。
/**
* 生产线程不停地向未满绥存中添加元素直到满为止,
* 消费线程不停地从非空缓存读取元素直到缓冲空为止,
* 当生产线程的缓存满且消费线程的缓存空时,将两者
* 的缓存互换,就这样一直下去
* @author jiangzhengjun
* @date 2010-6-9
*/
public class TestExchanger {
//交换器
static Exchanger<DataBuffer> exchanger = new Exchanger<DataBuffer>();
static DataBuffer emptyBuffer = new DataBuffer(10);
static DataBuffer fullBuffer = new DataBuffer(10);
public static void main(String[] args) {
new Thread(new ProducerThread()).start();
new Thread(new ConsumerThread()).start();
}
//随机获取字母
private static char getChar() {
return (char) (Math.random() * 26 + 65);
}
//随机睡几秒
private static void sleep() {
try {
Thread.sleep((long) (Math.max(500, Math.random() * 1000)));
} catch (InterruptedException e) {
e.printStackTrace();
}
}
//生产者 —— 不停的向缓冲中添加字母
static class ProducerThread implements Runnable {
public void run() {
int index = 0;
while (!Thread.currentThread().isInterrupted()) {
try {
// 如果发现数据缓冲满后,则不能再向缓冲添加元素,准备与消费线程中的空缓冲交换
if (emptyBuffer.isFull()) {
// 等待一个满的数据缓冲,一旦生产线程准备好,则互换,即将满的数所缓存
// 传递给消费线程,并获取消费线程会传进来的空的数据缓存
emptyBuffer = exchanger.exchange(emptyBuffer);
System.out.println("ProducerThread.capacity - "
+ emptyBuffer.data.size());
index = 0;
} else {//如果数据缓冲不满,则直到添加满为止
char c = getChar();
System.out.println("ProducerThread - " + (index++) + " - " + c);
emptyBuffer.put(c);
sleep();
}
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
//消费者 —— 不停的从缓冲中获取字母
static class ConsumerThread implements Runnable {
public void run() {
int index = fullBuffer.capacity;
while (!Thread.currentThread().isInterrupted()) {
try {
// 如果发现数据缓冲为空,则不能再读取元素,准备与生产消费线程中的满缓冲交换
if (fullBuffer.isEmpty()) {
// 等待一个满的数据缓冲,一旦生产线程准备好,则互换,即将空的数所缓存
// 传递给生产线程,并获取生产线程会传进来的满的数据缓存
fullBuffer = exchanger.exchange(fullBuffer);
System.out.println("ConsumerThread.capacity - "
+ fullBuffer.data.size());
index = fullBuffer.capacity;
} else {//如果缓冲不为空,则读到缓冲为空止
System.out.println("ConsumerThread - " + (--index) + " - "
+ fullBuffer.get());
sleep();
}
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
//数据缓冲
static class DataBuffer {
private List<Character> data;
private int capacity;//缓冲允许最大容量
public DataBuffer(int capacity) {
this.capacity = capacity;
data = new ArrayList<Character>();
}
public void put(char c) {
if (data.size() < capacity) {
data.add(c);
}
}
public char get() {
if (data.size() >= 0) {
return data.remove(data.size() - 1);
} else {
return 0;
}
}
public boolean isFull() {
return data.size() == capacity ? true : false;
}
public boolean isEmpty() {
return data.size() == 0 ? true : false;
}
}
}
一个阻塞队列,在每次的put操作中必须等待另一线程执行对应的take操作,反之亦然。同步队列没有任何内部容量,甚至连一个队列的容量都没有。SynchronousQueue允许我们在两个线程之间交换单个元素。
同步队列类似于 CSP 和 Ada 中使用的 rendezvous 信道。它非常适合于传递性设计,在这种设计中,在一个线程中运行的对象要将某些信息、事件或任务传递给在另一个线程中运行的对象,它就必须与该对象同步(即信息在两个线程间是相同的,这与普通的列队缓存是不一样的,这个是即放即取,信息对象不会停留在同步队列中)。
对于正在等待的生产者和消费者线程而言,SynchronousQueue的构造器还支持可选的公平排序策略。默认构造器是下不保证这种排序。使用公平设置为 true 所构造的队列可保证线程以 FIFO 的顺序进行访问。公平通常会降低吞吐量,但是可以减小可变性并可避免得不到服务。
另外SynchronousQueue详细的介绍请参考:阻塞队列和生产者—消费者模式章节。
/**
* @author jiangzhengjun
* @date 2010-6-9
*/
public class TestSynchronousQueue {
// 随机获取字母
private static char getChar() {
return (char) (Math.random() * 26 + 65);
}
// 随机睡几秒
private static void sleep() {
try {
Thread.sleep((long) (Math.max(500, Math.random() * 1000)));
} catch (InterruptedException e) {
e.printStackTrace();
}
}
private static class Producer implements Runnable {// 生产者
private BlockingQueue<String> sq;
public Producer(BlockingQueue<String> d) {
this.sq = d;
}
public void run() {
try {
while (!Thread.currentThread().isInterrupted()) {
// 但不一定能做到即消即产,因为生产者远少于消费者
sq.put(Thread.currentThread().getName() + " - "
+ getChar());
sleep();
}
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
private static class Consumer implements Runnable {// 消费者
private BlockingQueue<String> sq;
public Consumer(BlockingQueue<String> d) {
this.sq = d;
}
public void run() {
try {
while (!Thread.currentThread().isInterrupted()) {
System.out.println(Thread.currentThread().getName() + " - "
+ sq.take());// 即产即消,因为消费者比生产者充足
sleep();
}
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
public static void main(String[] args) {
// 同步队列
BlockingQueue<String> sq = new SynchronousQueue<String>();
Thread t = null;
//我们只创建二个生产者
for (int i = 0; i < 2; i++) {
t = new Thread(new Producer(sq));
t.setName("Producer -" + i + "- ");
t.start();
}
//创建多个消费者
for (int i = 0; i < 10; i++) {
t = new Thread(new Consumer(sq));
t.setName("Consumer -" + i + "- ");
t.start();
}
}
}
几乎每个服务器应用程序都使用某种形式的调整缓存。利用已有的计算结果可以缩短等等时间,提高吞吐量,代价是占用更多的内存。
下面我们一步步来构建一个调整的缓存,并一步步的优化。先尝试使用HashMap和同步来初始化缓存,下面是简单的实现:
public interface Computable<A, V> {//具有计算能力接口
V compute(A arg) throws InterruptedException;
}
//实现计算接口
class ExpensiveFunction implements Computable<String, BigInteger> {
public BigInteger compute(String arg) {//假设这是一个耗时的计算实现
// after deep thought...
return new BigInteger(arg);
}
}
class Memoizer1<A, V> implements Computable<A, V> {
//使用HashMap来建立缓存
private final Map<A, V> cache = new HashMap<A, V>();
private final Computable<A, V> c;//
public Memoizer1(Computable<A, V> c) {
this.c = c;
}
//注意这里需要同步HashMap
public synchronized V compute(A arg) throws InterruptedException {
V result = cache.get(arg);//缓存中是否已有
if (result == null) {//如果缓存中没有则重新计算
result = c.compute(arg);
cache.put(arg, result);
}
return result;
}
}
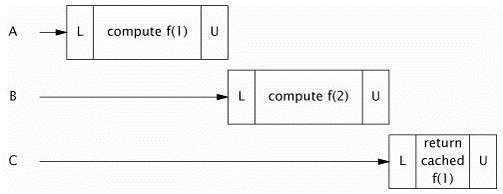
上面实现中Memoizer1中compute方法被整个同步了,这保证了线程安全,但是却带来一个明显的可伸缩性问题:一次只有一个线程能够执行compute。如果另外一个线程正忙于计算结果,其他调用compute的线程可能被阻塞很长时间。那么,compute可能会比不使用缓存花费更长的时间。这显示不是我们希望的结果。
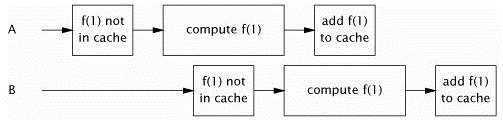
下面使用ConcurrentHashMap取代HashMap,改进Memoizer1中这种糟糕的并发行为。因为ConcurrentHashMap是线程安全的,所以不需要同步。Memoizer2与Memoizer1相比,毫无疑问具有更好的并发性:多线程可以真正并发地使用它了。但是它作为调整缓存仍然存在缺陷——当两个线程同时调用compute时,存在一个漏洞,可能同时计算相同的值。这对于这种备忘录形式的缓存,这仅仅是效率的问题,但是对于像一个缓存对象仅仅只能被初始化一次的缓存,这个漏洞就会带来安全性问题了。
public class Memoizer2<A, V> implements Computable<A, V> {
private final Map<A, V> cache = new ConcurrentHashMap<A, V>();
private final Computable<A, V> c;
public Memoizer2(Computable<A, V> c) { this.c = c; }
public V compute(A arg) throws InterruptedException {
V result = cache.get(arg);
if (result == null) {//计算相同参数的线程可能在相隔不长的时间内都到达
result = c.compute(arg);
cache.put(arg, result);
}
return result;
}
}
下面使用ConcurrentHashMap<A,Future<V>>替代ConcurrentHashMap<A, V>:
class Memoizer3<A, V> implements Computable<A, V> {
//缓存的不是值,而是一个计算的任务过程,它可能正在计算,也可能已计算完成
private final Map<A, Future<V>> cache = new ConcurrentHashMap<A, Future<V>>();
private final Computable<A, V> c;
public Memoizer3(Computable<A, V> c) {
this.c = c;
}
public V compute(final A arg) throws InterruptedException {
Future<V> f = cache.get(arg);
if (f == null) {
Callable<V> eval = new Callable<V>() {
public V call() throws InterruptedException {
return c.compute(arg);
}
};
FutureTask<V> ft = new FutureTask<V>(eval);
f = ft;
cache.put(arg, ft);//这里与上面if一起使用时是一个复合操作,所以还是有问题
ft.run(); // call to c.compute happens here
}
try {
return f.get();//如果还没有计算完则等待,否则马上返回
} catch (ExecutionException e) {
e.printStackTrace();
}
return null;
}
}
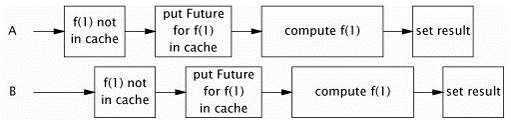
Memoizer3首先检查一个相应的计算是否开始,Memoizer2与它相反,它计算是否完成。Memoizer3的实现近乎是完美的:它展现了非常好的并发性(大部分来源于ConcurrentHashMap良好的并发性),能很快的返回结果,如果新到的线程请求的是其他线程正在计算的结果,它会耐心地等待。虽然这个程序与Memoizer2一样也存在着相同的缺陷,从上面幅图可以看出这个机率要小得多。这是还是因为if语句与put操作不是一个原子性引起的。
使用putIfAbsent方法来替换上面的复合操作:
public V compute(final A arg) throws InterruptedException {
while (true) {
Future<V> f = cache.get(arg);
if (f == null) {
Callable<V> eval = new Callable<V>() {
public V call() throws InterruptedException {
return c.compute(arg);
}
};
FutureTask<V> ft = new FutureTask<V>(eval);
f = cache.putIfAbsent(arg, ft);//重新检测if条件不是否满足
if (f == null) { f = ft; ft.run(); }//只有在成功放入后才开始计算
}
try {
return f.get();//注,计算取消或失败时都需要从缓存中移除,因为取消与失败的任务下次还是不会计算成功
} catch (CancellationException e) {
cache.remove(arg, f);//如果计算被取消,则移除,以便下次新的计算
} catch (ExecutionException e) {
cache.remove(arg, f);//如果计算失败,也要移除,以便下次新的计算
throw launderThrowable(e.getCause());//对ExecutionException异常进行分解
}
}
}
这个最终的修复的程序还是有缓存过期的问题,但是这些可以通过FutureTask的一个子类来完成,它会为每一个结果关联在一个过期时间,并周期性地扫描缓存中过期的访问。
@ThreadSafe
public class Factorizer implements Servlet {
private final Computable<BigInteger, BigInteger[]> c =
new Computable<BigInteger, BigInteger[]>() {
public BigInteger[] compute(BigInteger arg) {
return factor(arg);//计算某个数的因子,可能耗时比较长
}
};
private final Computable<BigInteger, BigInteger[]> cache
= new Memoizer<BigInteger, BigInteger[]>(c);//高速缓存
public void service(ServletRequest req, ServletResponse resp) {
try {
BigInteger i = extractFromRequest(req);
encodeIntoResponse(resp, cache.compute(i));//从缓存中取或重新计算
} catch (InterruptedException e) {
encodeError(resp, "factorization interrupted");
}
}
}
任务就是抽象、离散的工作单元。把一个应用程序的工作分离到任务中,执行与任务的分离,可以简化程序的管理。
服务器应用程序应该兼具良好的吞吐量和快速的响应性。
下面SingleThreadWebServer顺序地处理它的任务——接受达到80端吕的HTTP请求:
class SingleThreadWebServer {
public static void main(String[] args) throws IOException {
ServerSocket socket = new ServerSocket(80);
while (true) {
Socket connection = socket.accept();
handleRequest(connection);
}
}
}
理论上它是正确的,但它一次只能处理一个请求,因此在生产环境中的执行效率是很糟糕的。线程不断地在“接受连接”与“处理相关请求”之间交替运行,并且直到线程完成了当前的请求并再次调用accept,此前新的请求都必须等待。如果请求的处理速度很快,这样未尝不可,但我们不能将它应用到现实的Web Server中。该程序响应慢而且CPU利用率低。
顺序化处理在简单性或者安全性上具有优势,当任务数量少,但生命周期很长时或者服务器只服务于唯一用户时,比较应用。但它不能为服务器应用程序提供良好的吞吐量或快速的响应性。
为了提供好的响应性,可以为每个服务请求创建一个新的线程:
class ThreadPerTaskWebServer {
public static void main(String[] args) throws IOException {
ServerSocket socket = new ServerSocket(80);
while (true) {
final Socket connection = socket.accept();
Runnable task = new Runnable() {//使用线程处理每个请求
public void run() {
handleRequest(connection);
}
};
new Thread(task).start();
}
}
}
执行任务的负载已经脱离了主线程,这让主循环能够迅速地重新开始等待下一个连接,提高了响应性。另外“每任务一个线程”这样并行处理任务,使得多个请求可以同时得到服务,如果加上有多个处理器,程序的吞量会得到提高。
在中等强度的负载水平下,“每任务一个线程”方法是对顺序化执行的良好改进,只要请求的到达速度尚未超出服务器的请求处理能力,那么这种方法可以同时带来更快的响应性和更大的吞吐量。
“每任务一线程”存在一些实际的缺点:
1、 线程生命周期的开销:线程的创建关闭都要消耗资源,如果请求是频繁的,为每个请求创建一个线程会消耗大量的资源。
2、 资源消耗量:活动线程会消耗系统资源,尤其是内存。如果可运行的线程数多于可用的处理器数,线程将会空闲。大量空闲的线程会占用更多的内存,给垃圾回收带来压力,而且大量线程在竞争CPU资源时,还会产生其他性能开销。如果在这种有大量线程竞争CPU资源情况下,再创建线程将会产生更大的威害。
3、 稳定性:应该限制可创建线程的数目。这个数目在依赖于不同的平台与JVM启动时所带的参数。如果你超过这个数目,最可能的结果是收到一个OutOfMemoryError。
在一定范围内,增加线程可以提高系统的吞吐量,一旦超出了这个范围,再创建更多的线程只会拖垮你的程序。为了避免这种危险,应该设置一个范围限制你的应用程序可以创建的线程数,然后测试你的程序,确保线程数达到这个范围的极限,程序又不会耗尽所有的资源。
“每任务一线程”的问题在于它没有对创建的线程的数量进行任何限制。无限制的创建线程的行为在开发阶段可能表现还良好,但一旦部署后,并运行于高负载环境下,它的问题才会暴露出来。
任务是逻辑上的工作单元,线程是使任务异步执行的机制。
前面两种线程执行任务的策略者有严重的局限性:顺序执行会产生糟糕的响应性和吞吐量;“每任务一线程”会给资源管理带来麻烦。
就像“有界队列”防止应用程序过载而耗尽内存,线程池为线程管理提供了同新的好处。
作为Executor框架的一部分,java.util.concurrent提供了一个灵活的线程池实现。在Java类库中,任务执行的首要抽象不是Thread,而是Executor。
Executor接口:
public interface Executor {
void execute(Runnable command);
}
这是一个简单的接口,但它却为灵活强大的框架提供了基础。这个框架可以用于异步任务的执行,且支持很多不同的任务执行策略。为任务提交和任务执行之间的解耦提供了方法,并支持以前旧的Runnable的任务形式。
java.util.concurrent包中提供的 Executor 实现实现了 ExecutorService,这是一个使用更广泛的接口。ThreadPoolExecutor 类提供一个可扩展的线程池实现。Executors 类为这些 Executor 提供了便捷的工厂方法。
Executor是基于生产者——消费者模式。提交任务的执行者是生产者(产生待执行的工作单元-任务),执行任务的线程是消费者(从队列中取任务并执行)。如果你要在你的程序中实现一个生产者-消费者的设计,使用Executor通常是最简单的方式。
class TaskExecutionWebServer {
private static final int NTHREADS = 100;
private static final Executor exec = Executors.newFixedThreadPool(NTHREADS);
public static void main(String[] args) throws IOException {
ServerSocket socket = new ServerSocket(80);
while (true) {
final Socket connection = socket.accept();
Runnable task = new Runnable() {
public void run() {
handleRequest(connection);
}
};
exec.execute(task);
}
}
}
在这个程序中我们使用到了Executor的标准实现ThreadPoolExecutor。通过使用Executor,将处理请求任务的提交与它的执行体进行了解耦。只要替换一个不同的Executor实现,就可以改变服务器的行为。改变Excecutor的实现或者配置,所产生的影响远远小于直接改变任务的执行方式。
只要作些简单的修改,就可以让TaskExecutionWebServer像ThreadPerTaskWebServer那样一样运行:替换一个Executor,它为每个请求都创建一个新的线程。我们只需这样实现:
public class ThreadPerTaskExecutor implements Executor {
public void execute(Runnable r) {
new Thread(r).start();
};
}
或者如果要像SingleThreadWebServer那样运行,则可以让Executor在调用线程中同步地执行所有任务:
public class WithinThreadExecutor implements Executor {
public void execute(Runnable r) {
r.run();
};
}
所以使用Executor是很方便的,它可以让你很方便的更改线程的执行机制,做到了任务与执行的解耦与真正分离。
将任务的提交与任务的执行进行解耦,它的价值在于让你可以简单地为一个任务制定执行策略,并且保证后续的修改不会很因难。
任务策略包括以下几方面:
1、 任务在哪个线程中执行?
2、 任务以什么顺序执行(FIFO、LIFO、优先级)?
3、 可以有多少个任务并发执行?
4、 可以有多少个任务进入等待执行队列?
5、 如果系统过载,需要放弃哪一个任务呢?另外,如何通知应用程序知道这一切呢?
6、 在一个任务的执行前与结束后,应该做什么处理?
执行策略是资源管理的手段。最佳策略取决于可用的计算资源和你对服务质量的需求。将任务的提交与任务的执行策略规则进行分离,有助于在部署阶段选择一个与当前硬件最匹配的执行策略。
无论何时当你看到这种形式的代码:new Thread(runnable).start(),并且你可能最终希望获得一个更加灵活的执行策略时,请认真考虑使用Executor代替Thread。
线程池是与工作队列紧密绑定的。所谓工作队列,其作用是持有所有等待执行的任务。
在线程池中执行任务有很多“每任务一线程”无法比的优势。重用存在的线程而不是新的线程可以在处理多请求时抵消线程创建与消亡产生的开销。另一好处就是,在请求到达时,工作者线程通常已经存在,不需要因创建线程而延迟任务的执行,因此提高了响应性。我们还可以通过调整线程池的大小,你可以得到更多的线程让处理器处于忙碌状态,同时也可防止过多的线程相互竞争资源。
类库中已经提供了灵活的线程池实现和一些有用的预设配置。你可以通过Executors中的某静态方法来创建这个线程池:
newFixedThreadPool:创建一个固定数目的线程池,每当提交一个任务就创建一个线程,直到达到最大数目,这时线程池会保持长度不再变化(如果一个线程因意外的异常而死掉后会重新增加一个)。
newCachedThreadPool:创建一个可缓存的线程池,如果当前线程池的长度超过了处理的需要时,它可以灵活地回收空闲的线程,当需要增加时,它可以灵活地添加新的线程,而并不会池的长度作任何限制。
newSingleThreadExecutor:创建一个单线程化的Executor,它只创建唯一的工作者线程来执行任务,如果这个线程因异常结束,会有另一个线程取代它。Executor会保证任务依照任务队列所规定的顺序(FIFO、LIFO、优先级)执行。
newScheduledThreadPool:创建一个定长的线程池,而且支持定时的以及周期性的任务执行,类似于Timer。
newFixedThreadPool与newCachedThreadPool两个工厂方法返回多用途的ThreadPoolExecutor实例。直接使用ThreadPoolExecutor,也能创建出专用的Executor。
从“每任务一线程”策略迁移到基于池的策略,会对应用程序的稳定性产生重大的影响:Web Server再也不会因过高的负载而失败了(尽管服务器不会因为创建过多的线程而失败,但如果在很长的时里,任务到达的速度要超任务的执行速度工,内存仍然可能耗尽,因为等待执行的Runnable队列会不断的增长,当然我们可以使用一个有界的工作队列在Executor框架内解决这个问题)。
JVM会在所有线程(守护线程除外)全部终止后才退出。因此,如果无法正确关闭Executor,将会阻止JVM的结束。
Executor是异步执行任务的,任务集中,有些可能完成,有些可能正在运行,有些还可能在队列中等待执行,这会导致关闭很复杂。为了解决ExecutorService生命的问题,ExecutorService接口扩展了Executor,并且添加了一些用于生命周期管理的方法(同时还提供任务提交的便利方法):
public interface ExecutorService extends Executor {
void shutdown();
List<Runnable> shutdownNow();
boolean isShutdown();
boolean isTerminated();
boolean awaitTermination(long timeout, TimeUnit unit)
throws InterruptedException;
// ... additional convenience methods for task submission
}
ExecutorService有三种状态:运行(running)、关闭(shutting down)、和终止(terminated)。ExecutorService最初创建后的初始状态是运行状态。shutdown方法会启动一个平缓的关闭过程:停止接受新的任务,同时等待已经提交的任务完成——包括尚未开始执行的任务。shutdownNow方法会启动一个强制的关闭过程:停止所有正在执行的活动任务,暂停处理正在等待的任务,无法保证能够停止正在处理的活动执行任务,但是会尽力尝试,例如,通过 Thread.interrupt() 来取消是一种典型的实现,如果任何任务屏蔽或无法响应中断,则可能永远无法终止该任务。
如果Executor已关闭后提交的任务会被拒绝执行器(rejected execution handler)处理,拒绝执行器可能会悄悄的放弃任务,也可能引发execute抛出一个RejectedExecutionException异常,一旦所有任务都完成,则ExecutorService进行终止状态。可以调用awaitTermination等待ExecutorService进行终止状态,也可以轮询查询isTerminated来判断否进行终止状态了。通常awaitTermination紧跟随shutdwon之后,这样可以产生同步关闭ExecutorService的效果。
下面LifecycleWebServer为Web Server提供了生命周期的支持进行了扩展,它支持两种关闭方式:通过编程手工的调用stop方法,另一种就是由客户端发送一个关闭请求然后再调用stop进行关闭。
class LifecycleWebServer {
private final ExecutorService exec = ...;
public void start() throws IOException {
ServerSocket socket = new ServerSocket(80);
while (!exec.isShutdown()) {
try {
final Socket conn = socket.accept();
exec.execute(new Runnable() {
public void run() { handleRequest(conn); }
});
} catch (RejectedExecutionException e) {
if (!exec.isShutdown())
log("task submission rejected", e);
}
}
}
public void stop() { exec.shutdown(); }
void handleRequest(Socket connection) {
Request req = readRequest(connection);
if (isShutdownRequest(req))//判断客户端是否发送关闭请求
stop();
else
dispatchRequest(req);
}
}
Timer存在一些缺陷,我们应该使用ScheduledThreadPoolExecutor替换他,你也可以使用Executors的工厂方法newScheduledThreadPool工厂方法来创建它。
Timer只创建一个线程来执行所有的timer的任务TimerTask,如果一个任务的执行很耗时,会导致其他的TimerTask的定时执行不准确。例如一个TimerTask每10秒执行一次,而另一个TimerTask每40秒执行一次,短的TimerTask任务可能会在长的TimerTask执行完后快速连续地执行4次,也可能丢掉4次调用(这取绝于你是调用的按固定频率方法如scheduleAtFixedRate或延迟进行调用方法如schedule)。但调度线程池解决了这个缺陷,它提供了多个线程来执行定时周期性任务。
Timer的另一问题是如果TimerTask中抛出了未检查异常(不可能抛检查异常,因为TimerTask的run方法声明没有抛出任何异常),由于Timer线程不捕获任何异常,所以Timer线程会被终止掉,未开始执行的TimerTask将不会不再执行(当然执行了一半的线程就是当前抛出异常的线程,不会是其他线程,因为Timer是按串行来执行每个任务的,所以不会同时出现两个任务在执行)。
由于Timer是启动一个线程来串行的从任务队列中取任务然后执行,如果任务抛出未检查异常,则这个异常不会被抛到调用Timer的线程,因为异常是不会从子线程抛到他的父线程中去的,所以只是Timer线程死掉,而它的父线程还会正常运行。只要某个任务抛出了未检测异常,如果你在计划任务将会得到一个携带“Timer already cancelled”信息的异常。但ScheduledThreadPoolExecutor妥善地处理了这个行为异常的任务。
如果你要自己创建调度服务,你可以使用类库中提供的DelayQueue,它是BlockingQueue的一个实现,是它为ScheduledThreadPoolExecutor提供了调度的功能。DelayQueue是管理实现Delayed接口的对象,只有在延迟期满时才能从中提取元素,该队列的头部是延迟期满后保存时间最长的 Delayed 元素。实现Delayed的getDelay方法可以告诉DelayQueue所剩余延迟时间(零或负值指示延迟时间已经用尽,表示延时期满),只有延时期满的对象才能放入队列中,在调用take时会调用getDelay进行判断是否延时期满。在放入队列过程中还会根据延时长短进行排序,排序的依据是compareTo(因为Delayed还实现了Comparable接口)方法。
要使用Executor,我们得要将任务描述成Runnable对象,这就需要在需求中找出任务的边界,这些任务可大可小。
下面我们开发一个组件的不同版本,每个版本允许的不同的并发性。示例是模拟浏览器渲染HTTP页面的功能,模拟一个页面渲染器组件。假设HTTP页面里只有文本标签,当然在文本中穿插着图片(图片标签还带有尺寸大小)。
最简单的渲染方式是顺序处理,当遇到文本时就先渲染到图像缓存中;当遇到图像时,先去到服务器上下载图像,然后也将它渲染到图像缓存里,等整个HTML页面都渲染好后展示给用户,如果页面很大,图片很的多的情况下会让用户等等很长时间。
另一种同样是顺序执行的方法血稍微好一些,它将渲染文本与渲染图像分开执行。它先渲染所有文本,并为图片预留出图像的所占用的框,在完成第一趟处理后就展示给用户,接着程序开始下载图像,并将它们绘制到相应的框中。SingleThreadRenderer就采用了这种方式:
public class SingleThreadRenderer {
void renderPage(CharSequence source) {
renderText(source);//渲染文本,并预留图像占位框
List<ImageData> imageData = new ArrayList<ImageData>();
for (ImageInfo imageInfo : scanForImageInfo(source))//扫描所有图像
imageData.add(imageInfo.downloadImage());
for (ImageData data : imageData)
renderImage(data);//下载并渲染图像
}
}
虽然Executor框架可以使用Runnable作为基本的任务单元,但Runnable不具有返回值与抛出受检查异常。
如果Callable不需要返回值,可以使用Callable<void>。
可以通过Executors的相关方callable法将Runnable封装成Callable接口的对象。
一个Executor执行的任务生命周期有4个阶段:创建、提交、开始和完成。
在Executor框架中,总可以取消(shutdown、shutdownNow)已经提交但未开始的任务,但是对于已经开始执行的任务,只有它们响应中断才可以取消。取消已经完成的任务没有影响。
Future描述了任务的任命周期,并提供了相关方法来获取结果(get)、取消任务(cancel)以及检查任务是已经完成(isDone)还是被取消(isCancelled)。
Future任务生命周期是单向的,不能向后转换——与ExecutorService的生命周期一样,一旦任务,它就永远停留在完成状态上。下面是Future与Callable接口:
public interface Callable<V> {
V call() throws Exception;
}
public interface Future<V> {
boolean cancel(boolean mayInterruptIfRunning);
boolean isCancelled();
boolean isDone();
V get() throws InterruptedException, ExecutionException,
CancellationException;
V get(long timeout, TimeUnit unit)
throws InterruptedException, ExecutionException,
CancellationException, TimeoutException;
}
任务的状态(还未开始、运行中、完成)决定了get方法的行为:如果任务已完成,get会立即返回或者抛出一个异常;如果任务没有完成,get会阻塞直到它完成。在计算的过程中,如果任务抛出了异常,get会将该异常封装为ExecutionException,然后重新抛出;如果任务被取消,get会抛出CancellationException。当抛出ExecutionException时,可以用getCause获取原始异常,下面是get的源码片段:
V innerGet() throws InterruptedException, ExecutionException {
acquireSharedInterruptibly(0);//如果未执行完会在这里阻塞
if (getState() == CANCELLED)//如果任务已取消
throw new CancellationException();
if (exception != null)//如果任务执行的过程中抛出异常
throw new ExecutionException(exception);
return result;
}
有很多种获取任务的Future,ExecutorService中的submit方法可以接受一个Callable或Runnable,然后可以返回一个Future,因此可用它来获取任务的结果或者取消它。FutureTask实现了Future与Runnable接口,在构造时我们可以确地传进Runnable或Callable来实例化一个FutureTask,它可以提交给Executor来执行,或者将它包装成Thread后当作线程执行,因为FutureTask具有Future特性,所以已可取消或获取执行结果。
在1.6中,ExecutorService所有的实现都覆写了AbstractExecutorService中的newTaskFor方法,以此来控制ExecutorService中get方法所返回的Future的实例对象类型,该方法默认就是创建一个FutureTask类型的Future实例对象。
将Runnable或Callable对象提交到Executor是一个对象安全发布的过程,即Runnable或Callable对象从提交线程传递到任务执行的任务的过程是线程安全的,我们不用担心这些对象是否完全初始(Runnable与Callable对象的工作内存中的数据写回到主内存中)。类似地,通过Future的get方法获取的任务执行结果也是一个安全发布了的对象,我们在获取它的过程中是线程安全的。
为了使用渲染器具有更高的并发性,我们需要将渲染过程分成两个任务:一个是渲染文本,一个是下载所有图像(因为一个受限于CPU,一个受限于I/O)。
使用Future等待图像下载:
public class FutureRenderer {
private final ExecutorService executor = ...;
void renderPage(CharSequence source) {
final List<ImageInfo> imageInfos = scanForImageInfo(source);
Callable<List<ImageData>> task =//图像下载任务
new Callable<List<ImageData>>() {
public List<ImageData> call() {
List<ImageData> result//存储下载的图片
= new ArrayList<ImageData>();
for (ImageInfo imageInfo : imageInfos)
result.add(imageInfo.downloadImage());
return result;//返回下载的图片
}
};
Future<List<ImageData>> future = executor.submit(task);//在渲染文本前启动
renderText(source);//开始渲染文本
try {
List<ImageData> imageData = future.get();//阻塞获取下载的图片
for (ImageData data : imageData)
renderImage(data);//待图片下载完后开始渲染图像
} catch (InterruptedException e) {
// 恢复中断状态
Thread.currentThread().interrupt();
// 我们不需要结果了,所以可以将任务取消
future.cancel(true);
} catch (ExecutionException e) {
throw launderThrowable(e.getCause());
}
}
}
虽然上面在一定程度上提高了并发性,然后,我们还可以做得更好,用户不必等到怕有的图像下载完成后一下子看到所有图片,他们或许更希望只要下载完一幅图像就要看到一幅。
FutureRenderer用到了两个任务:一个负责渲染文本,一个负责下载图像。如果渲染文件的速度远远大于下载图像的速度(这完全是有可能的),那么最终的性能与顺序执行版的性能不会有很大的不同,反倒提高了代码的复杂度。
如果你向Executor提交了一批任务并且还要处理这批任务返回的结果,我们可以通过Executor的实现类ExecutorService的“List<Future<T>> invokeAll(Collection<Callable<T>> tasks)”方法快捷的实现,也可以通过循环这批任务然后在循环里通过ExecutorService的“Future<T> submit(Callable<T> task)”一个个提交给Executor并将返回的Future存储在列表中供后续取消或获取任务结果使用。
上面是调用invokeAll返回的Future列表,列表里元素的顺序与给定任务列表的迭代器所生成的顺序或在循环中通过submit一个个提交的顺序相同。这个缺点就是如果第一个任务要花很多时间,invokeAll就不能及时返回Future列表,这会造成不必要的等待,而在等待期间可能某些任务已经完成,并可以对这些已完成的任务结果先进行处理,显然,返回的结果列表顺序与给定任务列表的迭代器所生成的顺序相同在某些时候可能没什么意义,如果将结果列表按可获得任务结果的顺序保存起来会更有意义(即哪个任务先完成则先处理谁),我们可以通过ExecutorCompletionService来实现。
当然我们也可以不用invokeAll而是在在循环中逐个提交一批任务,并将任务相关连的Future存在放列表中,处理结果时需要手动自己对Futue列表进行遍历,如果想等前面的任务结果返回后再处理紧跟在后面的,则也会造成不必要的等待,但我们也可以反复的轮询Future列表,谁先完成后就处理谁,但这要经过反复的检查任务是否完成(isDone),即使这也不会比使用ExecutorCompletionService方便。
CompletionService提供将“任务生产者线程”与“获取已完成任务的结果”分离开来的服务。原来是这样处理的:在提交任务后(不管是批量还是单条)处理结果时,我们直接通过Future来get结果,如果任务未执行完,get会阻塞,这对只提交一条任务来说没关系,但如果是一批的话,挨个get就不合理的了,因为很有可能调用的get的这个任务还未完成就会阻塞,而其他的任务已经执行完成便可以处理了,所以这会造成不必要的等待。而合理的做法是谁先完成就处理谁的结果。那既然想要这样合理的处理,就要对任务返回的结果进行排列——谁先完成就把它排在最前面,幸运的是我们不需要自己做这些事,ExecutorCompletionService已为会提供了这一切。
CompletionService它整合了Executor和BlockingQueue的功能。通过CompletionService提交的任务会委托给Executor去提交并执行,而执行的返回结果会按照任选执行完成的先后顺序存放到BlockingQueue中,所以能从BlockingQueue队列中取出的结果是已执行完的任务结果。
ExecutorCompletionService是一个CompletionService实现,它通过封装Executor与LinkedBlockingQueue来实现。任务执行完成时会调用FutureTask(ExecutorService返回的Future结果就是FutureTask类型实现)中的done方法。当向ExecutorCompletionService提交一个任务后,首先把这个任务包装为QueueingFuture(而ExecutorService则是封装成FutureTask),它是FutureTask的一个子类,并覆写了done方法,就是在这个方法中将结果放入LinkedBlockingQueue中的。
ExecutorCompletionService的使用大致如下:
//包装一个Executor
ExecutorCompletionService service = new ExecutorCompletionService(executor);
//在循环中一个个提交任务,因为CompletionService不像ExecutorService具
//有任务批量提交方法invokeAll
for (Callable<Integer> task : tasks) service.submit(task);
//在循环中从队列中获取任务结果,结果的个数就是任务的个数,taks为任务集合
for (int i = 0; i < taks.size(); i++)
count += service.take().get();//从阻塞队列中取出Futur,再读取结果,这里的结果肯定是执行完或取消的任务,调用get是不会阻塞的,但take是可能被阻塞的。
使用CompletionService,我们可以从两方面提高页面渲染器的性能:缩短总的运行时间以及提高响应性。我们可以在每需要下载一个图像时,就创建一个独立的任务,并在线程池中执行它们,将顺序的下载过程转换为并行的:这能减少下载所有图像的总时间。而且从CompletionService中获取结果,只要任何一个图像下载完成,就能立刻展示给用户,由此我们要以给用户提供一个更加动态和有更高响应的用户界面。
public class Renderer {
private final ExecutorService executor;
Renderer(ExecutorService executor) {
this.executor = executor;
}
void renderPage(CharSequence source) {
final List<ImageInfo> info = scanForImageInfo(source);
//对ExecutorService进行包装,转换成CompletionService
CompletionService<ImageData> completionService =
new ExecutorCompletionService<ImageData>(executor);
for (final ImageInfo imageInfo : info)//对图像信息循环
//每幅图像一个下载任务
completionService.submit(new Callable<ImageData>() {
public ImageData call() {
return imageInfo.downloadImage();
}
});
//当所有图像下载任务启动后进行文本渲染工作
renderText(source);
try {
//返回结果数目与任务数相等,对结果进行遍历
for (int t = 0, n = info.size(); t < n; t++) {
//从结果队列中获取Future结果对象,来一个就取一个,但这里有可能阻塞
Future<ImageData> f = completionService.take();
//获取任务结果,这里不可能被阻塞
ImageData imageData = f.get();
renderImage(imageData);//开始渲染图像
}
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
} catch (ExecutionException e) {
throw launderThrowable(e.getCause());
}
}
}
有时如果一个任务无法在某个指定的时间内完成,那么它的结果就失效了,此时程序可以放弃该任务。如,一个Web应用会从外部的广告服务器上获取广告信息,但是如果应用程序在两秒钟得不到响应,就会显示一个默认的信息,这样即使得不到广告信息也不会破坏站点的响应性需求。
Future.get(long timeout,TimeUnit unit)为我们提供了时限便利操作:它在结果准备好后立即返回,如果在时限内没有准备好,就会抛出TimeoutException。
使用限时任务的问题是,当它们超时时应该能够停止它们,这样才不会继续运行而浪费资源。为了达到这个目的,可以让任务自己严格管理它的预定时间,超时后就终止执行;或者也要吧在超出时限后取消任务。Future再次派上用场:如果一个限时的get抛出TimeoutException,你可以通过Future取消任务。
下面演示了限时的Future.get的一种典型应用,在指定时间内获取广告信息,如果get超时,会取消获取广告的任务,并使用默认信息代替:
Page renderPageWithAd() throws InterruptedException {
long endNanos = System.nanoTime() + TIME_BUDGET;//预计任务在这个点运行完
Future<Ad> f = exec.submit(new FetchAdTask());//提交下载广告任务
// 在等待广告的时渲染页面
Page page = renderPageBody();
Ad ad;//广告
try {
// 仅需等待所剩余的预计时间
long timeLeft = endNanos - System.nanoTime();
ad = f.get(timeLeft, NANOSECONDS);//在限时内获取结果
} catch (ExecutionException e) {
ad = DEFAULT_AD;//如果广告任务执行失败,则设置默认广告
} catch (TimeoutException e) {
ad = DEFAULT_AD; //如果广告下载超时,则设置默认广告
f.cancel(true);//并取消广告下载任务
}
page.setAd(ad);//为页面设置广告
return page;
}
上面是单个任务采用Future.get来限时的,如果现在我们要对一批任务进行限时,且我们不关心任务是否全部完成,则我们可以通过Executor的invokeAll、invokeAny的限时版本来提交任务。invokeAll会在指定的时间内一定会返回Future列表,但列表里可能会有被取消的任务;invokeAny只要有一个任务完成,则
get:在任务完成前一直阻塞。会抛出三种异常:CancellationException - 如果计算被取消、ExecutionException - 如果计算抛出异常、InterruptedException - 如果当前的线程在等待时被中断。
get(long timeout, TimeUnit unit):在超时之前且任务未完成则一直阻塞。除抛出以上三种异常
cancel(boolean mayInterruptIfRunning):试图取消对此任务的执行。如果任务已完成、或已取消,或者由于某些其他原因而无法取消,则此尝试将失败。当调用cancel时,如果调用成功,而此任务尚未启动,则此任务将永不运行。如果任务已经启动,则mayInterruptIfRunning参数决定了是否调用运行任务的线程的interrupt操作。
isCancelled:如果在任务正常完成前将其取消,则返回true
isDone:正常终止、异常或取消而完成,在所有这些情况中,此方法都将返回 true
ExecutorService的有三个重载的submit方法:
1、 可以接收Runnable或Callable类型的任务,返回Future<?>类型的Future的get返回null。
2、 这三个方法都将提交的任务转换成了Future的实现类FutureTask实例,并作为submit的返回实例。
3、 另外调用这三个方法不会阻塞,不像invokeAll那样要等到所有任务完成后才返回,与不像invokeAny那样要等到有一个任务完成后才返回Future。
4、 这个三方法会调用Executor的execute来完成,因为Executor的execute会抛出RejectedExecutionException - 如果不能接受执行此任务、NullPointerException - 如果命令为 null这两个运行进异常,所以这三个方法也会抛出这两个异常。
T invokeAny(Collection<Callable<T>> tasks):
1、 只要某个任务已成功完成(也就是未抛出异常,这与任务完成概念不一样:任务完成是指定Future的isDone返回true,有可能是抛出异常后进行完成状态),才返回这个结果。一旦正常或异常返回后,则取消尚未完成的任务(即任务所运行的线程处理中断状态,一旦在它上面出现可中断阻塞的方法调用,则会抛出中断异常)。
2、 此方法会阻塞到有一个任务完成为止(正常完成或异常退出)。
3、 也是调用Executor的execute来完成
4、 调用get不会阻塞
invokeAny(Collection<Callable<T>> tasks, long timeout, TimeUnit unit):
1、 只要在给定的超时期满前某个任务已成功完成(也就是invokeAny方法不能抛出异常,包括Future.get所抛的异常),则返回其结果。一旦正常或异常返回后,则取消尚未完成的任务。
2、 此方法会阻塞到有一个任务完成为止(正常完成或异常退出)。
3、 也是调用Executor的execute来完成
4、 调用get不会阻塞
List<Future<T>> invokeAll(Collection<Callable<T>> tasks):
1、 只有当所有任务完成时,才返回保持任务状态和结果的 Future 列表。返回列表的所有元素的 Future.isDone() 为 true。注意,可以正常地或通过抛出异常来已完成任务。
2、 此方法会阻塞到所有任务完成为止(正常完成或异常退出)。
3、 也是调用Executor的execute来完成,如果任务执行过程中抛出了其他异常,则方法会异常退出,且取消所有其他还未执行完成的任务。
4、 返回的列表中的Future都是已经完成的任务,get时不会再阻塞
invokeAll(Collection<Callable<T>> tasks, long timeout, TimeUnit unit):
1、 当所有任务完成或超时期满时(无论哪个首先发生),返回保持任务状态和结果的 Future 列表(如果是超时返回的列表,则列表中的会包括这些还未执行完的任务,使用get获取结果时可能会抛出CancellationException异常)。返回列表的所有元素的 Future.isDone() 为 true。一旦返回后,即取消尚未完成的任务。注意,可以正常地或通过抛出异常来完成任务。
2、 此方法会阻塞到所有任务完成为止(正常完成或异常退出或超时)。
3、 也是调用Executor的execute来完成,如果任务执行过程中抛出了其他异常,则方法会异常退出,且取消所有其他还未执行完成的任务。
4、 返回的列表中的Future中会有因超时执行任务时异常而未执行完的任务,get时会抛出CancellationException或ExecutionException,当然所有的Future的get也不会阻塞。
当外部代码能够在活动自然完成前,能把它的状态更改为完成,那么这个活动被称为可取消的。我们可能会因为很多的原因取消一个活动:用户请求取消、应用程序事件、限时活动、错误、关闭系统。
简单的取消任务的方式是,在活动中定义一个标示,用它来保存取消状态,但要注意的是这个标示域一定要是volatile域,否则由于线程对变量的可见性问题而永远不会停止活动。
一个可取消任务必须拥有取消策略——其他代码如何请求取消该任务、任务在什么时间点检查取消语法是否到达、如何处理取消请求。
PrimeGenerator中的取消机制最终会导致任务退出,但并不是立刻发生的,需要花费一定的时间。如果某个任务调用了一个阻塞方法,如BlockingQueue.put,我们可能会永远都不能取消标志,因些永远都不会终结。
每一个线程都有一个boolean类型的中断状态;在中断的时候,这个中断状态被设置为了true,Thread包含其他用于中断线程的方法,以及获取线程中断状态的方法:
public class Thread {
public void interrupt() { ... }
public boolean isInterrupted() { ... }
public static boolean interrupted() { ... }
...
}
interrupt方法是发出中断请求,并且将线程的中断状态设置为true;isInterrupted是返回目标线程的中断状态;静态方法interrupted也是返回目标线程中断状态,只不过是在访问后立即清除中断状态,它也是唯一清除中断状态的方法,它的目标线程是发起interrupted操作的线程,即当前线程:
public static boolean interrupted() {
return currentThread().isInterrupted(true);
}
所有的类库阻塞方法,如Thread.sleep、Object.wait,如果在阻塞过程中发现线程的中断状态为true,则会先清除当前线程中断状态,再抛出InterruptedException异常,则阻塞方法会因抛出异常而不再阻塞。JVM并没有对阻塞方法发现中断的速度作出保证,不过在现实中这样的响应还是比较迅速的。
当线程在并不处于阻塞状态的情况下发生中断时,会设置线程的中断状态为true,然后一直等到被取消的线程获取中断状态,来检查是否发生了中断,如果不触发InterruptedException异常,中断状态会一直保持,直到有人特意去清除中断状态。
调用interrupt并不意味着一定会停止目标线程,它仅仅是传递了请求中断的消息。线程自己会在一个方便时候选择是否退出运行。
静态的isInterrupted应该小心使用,因为它会清除并发线程的中断状态。如果你调用了isInterrupted,并返回true,你必须对其进行处理,除非你想掩盖这个中断——这时你可以抛出InterruptedException,或者通过再次调用interrupt来保证中断状态。
好像在while循环中显示的检测中断状态(!Thread.currentThread().isInterrupted()))并不是绝对必要的,因为调用了阻塞的put方法,在阻塞时如果线程被中断,则会抛出异常而退出循环,但是这种检测会使用PrimeProducer对中断具有更好的响应性。这是因为在耗时的任务开始之前就有可能发出了中断请求,而不需一定等到put抛出异常才退出。
正如任务的取消策略一样,线程也应有中断策略,一个中断策略决定线程如何应对中断请求——当发现中断请求时如何处理、哪些任务需要考虑原子性、以怎样的速度响应中断。
区分任务和线程对中断的反应很重要,一个单一的中断请求可能有一个或一个以上预期的接收者——在线程池中中断一个工作者线程,意味着取消当前任务,并关闭工作线程,这个中断请求会涉及到任务与线程。
任务不会在自己拥有的线程中执行,它们借助于属性服务的线程,如线程池。如果代码不属于这个线程(对线程池而言,线程池中的线程执行的任何任务都是外部代码)就应该小心地保存中断状态,以便代码拥有者线程能够处理它(中断状态)(想一想,Executor框架中正是这样处理的,我们向Executor提交的任务相对于Executor来说就是外部代码,Executor在执行任务过程中所发生的异常都会保存下来,并可通过Future.get来获取这些异常,另外Executor也将底层的InterruptedException异常传递给了get方法)。
不要掩盖了低层的中断信息,这就是为什么大多数的阻塞库函数仅仅是抛出InterruptedException作为处理的过程,因为这些阻塞库函数调用是经过了库以外的用户(比如我们)调用,所以它们作出了这样合理的取消策略:将异常重新抛给调用者们,这样上层栈就可以进一步处理了。
当检查到中断请求时,任务并不需要放弃所有事情——它可以选择推迟,直到更合理的时机,这需要记得它已经被请求过中断了,完成当前正在进行的任务,然后抛出InterruptedException或者指明中断。
当发现中断信息后,不管我们是否取消任务还是继续执行任务,我们都要保存中断信息,如果对中断的处理不仅仅是将InterruptedException传递给调用者,那还应该在捕获InterruptedException之后恢复中断状态:
Thread.currentThread().interrupt();
因为每一个线程都有其自己的中断策略,所以你不应该终止线程,除非你知道中断对这个线程意味关什么,而是将中断信息传递给上层调用者。
Java中的中断策略是推迟处理,在响应性和健壮性之间处于平衡。
有两种处理InterruptedException异常的实用策略:
1、 传递异常,使用你的方法也成为可中断阻塞方法
2、 或者保存中断状态,上层调用栈中的代码能够对其进行处理
向调用者传递InterruptedException:
BlockingQueue<Task> queue;
...
public Task getNextTask() throws InterruptedException {
return queue.take();
}
如果你不能将InterruptedException传递出去(比如你的任务实现了Runnable的run方法,它是不允许报出非检测异常的),这里你需要在异常块里再次调用interrupt保存中断状态,而不是捕获到了什么也不做,除非你真正实现了线程的中断策略。大多数代码并不知道它们会在哪个线程中运行,所以应该保存中断状态。
只有实现了线程中断策略的代码才可以接收中断请求,通用的任务和库的代码绝不应该接收中断请求,因为它们会被上层调用。
不可取消的任务的中断方式:有些任务拒绝被中断,这使得它们是不可取消的。但是,即使是不可取消的任务也应该尝试保留中断状态,以防在不可取消的任务结束之后,调用栈上更高层的代码需要对中断进行处理。清单 6 展示了一个方法,该方法等待一个阻塞队列,直到队列中出现一个可用项目,而不管它是否被中断。为了方便他人,它在结束后在一个 finally 块中恢复中断状态,以免剥夺中断请求的调用者的权利。(它不能在更早的时候恢复中断状态,因为那将导致无限循环—— BlockingQueue.take() 将在入口处立即轮询中断状态,并且,如果发现中断状态集,就会抛出 InterruptedException。)
清单 6. 在返回前恢复中断状态的不可取消任务
public Task getNextTask(BlockingQueue<Task> queue) {
boolean interrupted = false;
try {
while (true) {
try {
return queue.take();
} catch (InterruptedException e) {
interrupted = true;
// 失败并重试
}
}
} finally {
if (interrupted)// 保留中断状态
Thread.currentThread().interrupt();
}
}
如果你的代码没有调用可中断的阻塞方法,它仍然可以通过检查任务当前线程中断状态来响应中断。选择适当的检查频率需要在效率和响应性之间进行权衡,如果你有高响应性的需求,那么你不应该调用潜在的耗时方法,
有很多的程序运行是没有结束条件的,它们可能永远地运行下去(比如列举某个数的所有质数)。下面是求所有的质数过程:
//求所有质数(素数)的任务
public class PrimeGenerator implements Runnable {
//存储所有求得的质数
private final List<BigInteger> primes = new ArrayList<BigInteger>();
private volatile boolean cancelled;//取消标示
public void run() {
BigInteger p = BigInteger.ONE;//从质数1开始
while (!cancelled) {//轮询是否已被取消
/*
* BigInteger.nextProbablePrime返回大于此 BigInteger 的
* 可能为素数的第一个整数
*/
p = p.nextProbablePrime();
synchronized (this) {
primes.add(p);
}
}
}
public void cancel() {
cancelled = true;
}
public synchronized List<BigInteger> get() {
return new ArrayList<BigInteger>(primes);
}
}
class PrimeGeneratorTest {
static List<BigInteger> aSecondOfPrimes() throws InterruptedException {
PrimeGenerator generator = new PrimeGenerator();
new Thread(generator).start();
try {
TimeUnit.SECONDS.sleep(1);//运行1秒后停止任务
} finally {
generator.cancel();
}
return generator.get();
}
public static void main(String[] args) throws Exception {
System.out.println(aSecondOfPrimes());
}
}
虽然PrimeGenerator运行限制为1秒,但可能需要大于一秒的时间才能停止,但是它最终检测到中断,并发出停止指令,停止线程。这个任务的另一个问题是,如果PrimeGenerator抛出运行时异常,则异常会被忽略,因为一个线中的异常不会传递到他的父线程中,而自己又没有显示地处理异常。
下面程序是上面的aSecondOfPrimes方法的改进,功能是在一定时间内运行一个Runnable任务,并安排了取消任务的计划任务,由这个任务在给定的时间间隔后中断它,这样解决了任务线程抛出未检查异常问题而父线程捕获不到的问题:
private static final ScheduledExecutorService cancelExec = Executors
.newSingleThreadScheduledExecutor();
public static void timedRun(Runnable r, long timeout, TimeUnit unit) {
final Thread taskThread = Thread.currentThread();
cancelExec.schedule(new Runnable() {
public void run() {// 取消求质数任务线程的计划任务
taskThread.interrupt();// 发出中断请求
}
}, timeout, unit);
/*
* 直接调用Runnable的run方法,这样不会启一个线程,这
* 样就可以捕获到run方法抛出的异常了
*/
r.run();//这里有可能不会退出,这就看run方法是否响应了中断
}
上面这是一个很简单的解决方法,但是它违背了以下原则:在中断线程之前,你应该了知道它的中断策略。由于timedRun可以从任意的中线程调用,它并不知道调用线程的中断策略。如果任务在超时之前执行完成了,取消任务可能在任务执行线程调用timedRun方法并返回后才启动,此时我们不知道任务执行线程在执行什么代码,总之没有什么好的结果。
此外,如果任务不响应中断timeRun将不会返回,直到任务结束,这时可能已经超过期望限定时间很久了,这对于一个限时运行的服务如果没有在给定时间内返回的话,这是非常不好的。
下面程序解决了aSecondOfPrimes的异常处理问题,并且也解决了前面做法中引发的问题。用来执行任务的线程拥有自己的执行策略,即使任务不响应中断,限时运行的方法仍然能够返回到调用它的线程。在启动任务线程之后,timedRun方法会调用新创建的任务线程的限时join方法。在join方法返回后,它会检查任务是否有异常抛出,如果有,会在调用timeRun的线程中再次抛出。用来保存异常信息的域t声明成了volatile,这会安全发布该对象,这样就可以安全的在多线程中共享了。
这个版本解决了前面例子中出现的问题,但因为它依赖于一个的join方法,因此它也受到join不足之处的影响:我们不知道控制权的返回是因为线程自然退出还是join的超时。
private static final ScheduledExecutorService cancelExec = Executors
.newSingleThreadScheduledExecutor();
public static void timedRun(final Runnable r, long timeout, TimeUnit unit)
throws Throwable {
//任务执行线程
class RethrowableTask implements Runnable {
// 保存任务执行过程中的异常信息
private volatile Throwable t;
public void run() {
try {
r.run();
} catch (Throwable t) {
this.t = t;
}
}
void rethrow() throws Throwable {
if (t != null)
throw t;
}
}
RethrowableTask task = new RethrowableTask();
final Thread taskThread = new Thread(task);
taskThread.start();// 将任务放在一个线程中运行
cancelExec.schedule(new Runnable() {
public void run() {// 定时取消任务线程
taskThread.interrupt();
}
}, timeout, unit);
//设置一个超时,如果任务在指定的时间内没有完成,也会返回
taskThread.join(unit.toMillis(timeout));
//检测任务在运行时是否抛出异常
task.rethrow();
}
cancel(boolean mayInterruptIfRunning):试图取消对此任务的执行。如果任务已完成、或已取消,或者由于某些其他原因而无法取消,则此尝试将失败。当调用cancel时,如果调用成功,而此任务尚未启动,则此任务将永不运行。如果任务已经启动,则mayInterruptIfRunning参数决定了是否向执行任务的线程发出interrupt操作。
除非你知道线程的中断策略,否则你不应该中断线程,那么什么时候可以调用一个带true的cancel方法呢?任务执行的线程是由标准的Executor实现来创建的,它实现了一个中断策略,使得任务可以通过中断被取消,所以当任务在标准的Executor中运行时,通过它们的Future来的cancel(true)取消任务是安全的。当要取消一个任务的时候,你不应该直接中断线程池,因为你不知道中断请求到达时,线程池中在执行什么任务——所以只能通过任务自身关联的Future来取消它所运行的线程。
下面是timedRun的另一个版本,使用Future和任务执行框架来取消任务:
public static void timedRun(Runnable r,
long timeout, TimeUnit unit)
throws InterruptedException {
Future<?> task = taskExec.submit(r);//提交任务
try {
task.get(timeout, unit);//指定任务超时时间
} catch (TimeoutException e) {
// 任务将会在后面被取消
} catch (ExecutionException e) {
// 如果任务运行时抛出了异常,则重新抛出
throw launderThrowable(e.getCause());
} finally {
//对已经结束的任务没有影响
task.cancel(true); // 中断正在运行的任务
}
}
并非所有的阻塞方法都抛出 InterruptedException,对于这些阻塞方法,我们要使用与中断类似的手段来确保可以停止这些线程:
java.io中的同步 socket I/O:对socket的I/O读写时,会发生阻塞,但线程中断后也不会抛InterruptedException异常,但我们可以调用socket的close方法,则发生在socket I/O上的阻塞方法read、write会抛出SocketException,当然ServerSocket的accept阻塞方法也是这样。
java.nio中的同步I/O:实现InterruptibleChannel接口的通道是可中断的:如果某个线程在可中断通道上因调用某个阻塞的 I/O 操作(常见的操作一般有这些:serverSocketChannel. accept()、socketChannel.connect、socketChannel.open、socketChannel.read、socketChannel.write、fileChannel.read、fileChannel.write)而进入阻塞状态,而另一个线程又调用了该阻塞线程的 interrupt 方法,这将导致该通道被关闭,并且已阻塞线程接将会收到ClosedByInterruptException,并且设置已阻塞线程的中断状态。
Selector的异步I/O。如果Selector.select方法阻塞,可以调用它的close方法,这样会在阻塞方法上抛出ClosedSelectorException。
获得锁。尝试获取一个内部锁的操作(进入一个 synchronized 块)是不能被中断的,但是 ReentrantLock 支持可中断的获取模式。
下面ReaderThread展示了一项用来封装非标准取消任务的技术(非标准中断技术,标准的中断是调用线程的interrupt方法来抛出InterruptException异常?),通过重写Thread的interrupt来封装:
public class ReaderThread extends Thread {
private final Socket socket;
private final InputStream in;
public ReaderThread(Socket socket) throws IOException {
this.socket = socket;
this.in = socket.getInputStream();
}
//重写Thread的interrupt,即支持标准的中断,也关闭了底层的socket
public void interrupt() {//
try {
socket.close();//要中断socket的阻塞方法则需要关闭socket
}
catch (IOException ignored) { }
finally {
super.interrupt();//不要忘了调用标准中断interrupt
}
}
public void run() {
try {
byte[] buf = new byte[BUFSZ];
while (true) {
int count = in.read(buf);//这里可能会阻塞,如果在阻塞时socket被关闭,则会抛出异常,从而可以跳出阻塞状态
if (count < 0)
break;
else if (count > 0)
processBuffer(buf, count);
}
} catch (IOException e) { /* 允许线程退出 */ }
}
}
可以使用newTaskFor回调函数来改进ReaderThread中对非标准取消技术的封装的方法。这个方法是1.6添加到ThreadPoolExecutor的新特性。它是一个工厂方法,用来创建描述任务的Future,它返回的是一个RunnableFuture,这是一个接口,继承了Future和Runnable(FutureTask是它的实现)。
我们可以自定义任务的Future,这样可以覆写Future.cancel方法,并可以在该方法中实现日志、取消那些不响应中断的活动,上面RunnableFuture通过重写了Thread的interrupt实现了取消socket的阻塞线程,现样可以重写任务的Future.cancel来实现。
用newTaskFor封闭非标准取消技术:
//非标准取消的任务接口,扩展了Callable接口,并添加了cancel与newTask接口,我们的任务都要实现这个接口
public interface CancellableTask<T> extends Callable<T> {
void cancel();//自己实现取消任务
//自己实现RunnableFuture,不使用Executor提供的FutureTask默认实现
RunnableFuture<T> newTask();
}
@ThreadSafe//重写newTaskFor方法,该方法会在向Executor提交任务时调用
public class CancellingExecutor extends ThreadPoolExecutor {
...
protected<T> RunnableFuture<T> newTaskFor(Callable<T> callable) {
if (callable instanceof CancellableTask)//如果是自定义的Callable
return ((CancellableTask<T>) callable).newTask();
else
return super.newTaskFor(callable);
}
}
//实现自己的任务,注,这里是为抽象类,因为还没有使用Callable的call方法
public abstract class SocketUsingTask<T> implements CancellableTask<T> {
@GuardedBy("this") private Socket socket;
protected synchronized void setSocket(Socket s) { socket = s; }
//封装非标准的任务取消技术
public synchronized void cancel() {
try {
if (socket != null)
socket.close();//取消任务就是关闭socket
} catch (IOException ignored) { }
}
//为Executor提供的Future实现,可用来替代Executor默认的FutureTask
public RunnableFuture<T> newTask() {
return new FutureTask <T>(this) {//匿名类,继承自FutureTask
//重写FutureTask方法,即在FutureTask的cancel基础上添加了自己非标准中断实现
public boolean cancel(boolean mayInterruptIfRunning) {
try {
SocketUsingTask.this.cancel();//先调用自己的非标准中断实现
} finally {//然后再调用父类的标准中断实现
return super.cancel(mayInterruptIfRunning);
}
}
};
}
}
如果SocketUsingTask通过自己的Future来取消任务,Socket会被关闭,并且执行线程也会被中断,这就在原来默认的FutureTask基础之上添加了Socket I/O的非标准中断。通过上面的封装,我们后面的工作就是只专注于对任务call方法的实现。
应用程序通常会创建基于线程的服务,如线程池。这些服务的时间一般比创建它的方法更长。如果应用程序完成退出,这些服务线程也要结果。
线程池是创建工作线程的拥有者,如果需要中断这些线程,那么应该由线程池来负责。
应用程序可能拥有服务,服务可能拥有工作线程,但是应用程序并不拥有工作线程,所以应用程序不应该试图直接停止工作线程。相反,服务应该提供生命周期的方法来关闭它的自己与所拥有的工作线程,这样,当应用程序关闭这个服务时,服务就可以关闭所有的工作线程了。ExecutorService提供了shutdown 和 shutdownNow方法,持有其他工作线程的服务也应该都提供这种类似的关闭机制。
对于基于线程的服务,只要服务的存在的时间比创建它的方法要长,那么就应该提供生命周期方法。
日志服务器是将应用程序的要记的日志输出到一个缓存中,再通过一个后台日志线程将缓存中的日志写入到日志存储器上,这样降低了应用程序直接与日志存储器的交互可能的瓶颈。
不支持关闭的生产者-消费者日志服务:
// LogWriter就是一个基于线程的服务,但不是一个完成的服务
public class LogWriter {
//日志缓存
private final BlockingQueue<String> queue;
private final LoggerThread logger;//日志写线程
private static final int CAPACITY = 1000;
public LogWriter(Writer writer) {
this.queue = new LinkedBlockingQueue<String>(CAPACITY);
this.logger = new LoggerThread(writer);
}
public void start() { logger.start(); }
//应用程序向日志缓存中放入要记录的日志
public void log(String msg) throws InterruptedException {
queue.put(msg);
}
//日志写入线程,这是一个多生产者,单消费者的设计
private class LoggerThread extends Thread {
private final PrintWriter writer;
public LoggerThread(Writer writer) {
this.writer = new PrintWriter(writer, true); // autoflush
}
public void run() {
try {
while (true)
writer.println(queue.take());
} catch(InterruptedException ignored) {
} finally {
writer.close();
}
}
}
}
为了让一个这个日志服务真正可用,应该需要一个方法来终止日志线程。应用程序只能拥有LogWriter服务,但不能直接拥有该服务所拥有的日志写线程LoggerThread,所以我们应该为LogWriter服务提供一个生命周期的方法,以便能对日志写线程进行关闭动作,这样不会让JVM无法正常关闭。
虽然LoggerThread线程调用了阻塞方法take,并可响应中断,但这里我们不能简单地通过这种方式来终止LoggerThread线程。因为如果应用程序在不断地向缓存放入日志信息,那么take方法将永远不会阻塞,日志线程也就不可能退出。另外,取消一个基于生产者-消费者模式的服务中的线程,我们不只要取消消费者线程,也要考虑生产者线程,但这个例子中,因为生产者并非一个线程,取消它们是困难的。
最好的关闭LogWriter的方案是设置“已请求关闭”标志,避免消息进一步被提交进来。下面LogService是一个完整的日志服务实现,它在LogWriter基础之上添加了可靠的关闭服务器功能:
//日志服务,提供记录日志的服务,并有管理服务生命周期的相关方法
public class LogService {
private final BlockingQueue<String> queue;
private final LoggerThread loggerThread;// 日志写线程
private final PrintWriter writer;
private boolean isShutdown;// 服务关闭标示
// 队列中的日志消息存储数量。我们不是可以通过queue.size()来获取吗?
// 为什么还需要这个?请看后面
private int reservations;
public LogService(Writer writer) {
this.queue = new LinkedBlockingQueue<String>();
this.loggerThread = new LoggerThread();
this.writer = new PrintWriter(writer);
}
//启动日志服务
public void start() {
loggerThread.start();
}
//关闭日志服务
public void stop() {
synchronized (this) {
/*
* 为了线程可见性,这里一定要加上同步,当然volatile也可,
* 但下面方法还需要原子性,所以这里就直接使用了synchronized,
* 但不是将isShutdown定义为volatile
*/
isShutdown = true;
}
//向日志线程发出中断请求
loggerThread.interrupt();
}
//供应用程序调用,用来向日志缓存存放要记录的日志信息
public void log(String msg) throws InterruptedException {
synchronized (this) {
/*
* 如果应用程序发出了服务关闭请求,则不存在接受日志,而是直接
* 抛出异常,让应用程序知道
*/
if (isShutdown)
throw new IllegalStateException(/*日志服务已关闭*/);
/*
* 由于queue是线程安全的阻塞队列,所以不需要同步(同步也可
* 但并发效率会下降,所以将它放到了同步块外)。但是这里是的
* 操作序列是由两个操作组成的:即先判断isShutdown,再向缓存
* 中放入消息,如果将queue.put(msg)放在同步外,则在多线程环
* 境中,LoggerThread中的 queue.size() == 0 将会不准确,所
* 以又要想queue.put不同步,又要想queue.size()计算准确,所
* 以就使用了一个变量reservations专用来记录缓存中日志条数,
* 这样就即解决了同步queue效率低的问题,又解决了安全性问题,
* 这真是两全其美
*/
//queue.put(msg);
++reservations;//存储量加1
}
queue.put(msg);
}
private class LoggerThread extends Thread {
public void run() {
try {
while (true) {
try {
synchronized (LogService.this) {
// 由于 queue 未同步,所以这里不能使用queue.size
//if (isShutdown && queue.size() == 0)
// 如果已关闭,且缓存中的日志信息都已写入,则退出日志线程
if (isShutdown && reservations == 0)
break;
}
String msg = queue.take();
synchronized (LogService.this) {
--reservations;
}
writer.println(msg);
} catch (InterruptedException e) { /* 重试 */
}
}
} finally {
writer.close();
}
}
}
}
shutdown():启动一次顺序关闭,执行完以前提交的任务,没有执行完的任务继续执行完(即不会调用正在运行的任务线程的interrupt中断方法),但不接受新任务。如果已经关闭,则调用没有其他作用。
List<Runnable> shutdownNow():试图停止所有正在执行的任务(向它们发出interrupt操作语法),并暂停处理正在等待的任务,并返回等待执行的任务列表。无法保证能够停止正在处理的任务线程,但是会尽力尝试,典型的实现是通过 Thread.interrupt() 来中断正在运行的任务线程,所以如果任何任务屏蔽或无法响应中断,则可能永远无法终止该任务。
如果ExecutorService已关闭,再向它提交任务时会抛RejectedExecutionException异常。
两种不同的终结选择在安全性和响应性之间进行了权衡:强行终结的速度更快,但是风险更大,因为任务很可能在执行到一半时被终止,而正常终结速度慢,却安全,因为要直到队列中所有任务完成后,ExecutorService才关闭。
简单的程序我们可以在Main中直接启动和关闭一个全局的ExecutorService,但是对于复杂的程序,如基于Executor框架的服务类,我们则需要为它提供生命周期的方法。下面使用Executor修改前面的日志服务:
public class LogService {
//注,池中只创建一个写日志的工作线程
private final ExecutorService exec = Executors.newSingleThreadExecutor();
private final PrintWriter writer;
public LogService(Writer writer) {
this.writer = new PrintWriter(writer);
}
//启动日志服务
public void start() {
//钩子程序,在JVM正常关闭时调用,确保日志文件关闭
Runtime.getRuntime().addShutdownHook(new Thread() {
public void run() {
try {
LogService.this.stop();
} catch (InterruptedException ignored) {
}
}
});
}
//关闭日志服务
public void stop() throws InterruptedException {
try {
exec.shutdown();//先尝试关闭池中的工作线程
exec.awaitTermination(1, TimeUnit.MINUTES);//等待工作线程结束
} finally {
writer.close();//最后关闭日志文件
}
}
//供应用程序调用,用来向日志缓存存放要记录的日志信息
public void log(String msg) throws InterruptedException {
try {
exec.execute(new WriteTask(msg));
} catch (RejectedExecutionException ignored) {
}
}
//写日志任务
private class WriteTask implements Runnable {
private String msg;
public WriteTask(String msg) {
this.msg = msg;
}
public void run() {
writer.println(msg);
}
}
}
另一种保证生产者和消费者服务关闭的方式是使用一个终结标示对象:一个可识别的对象,放在队列最尾,取到它时意味着停止一切工作。生产者要注意的是在放入这个对象后就不能再放入了。这种方式对只有一个生产者比较适用。
下面通过终结标示对象来关闭一个文件检索服务:
public class IndexingService {
private static final File POISON = new File("");// 终结标示对象
private final IndexerThread consumer = new IndexerThread();// 生产者
private final CrawlerThread producer = new CrawlerThread();// 消费者
private final BlockingQueue<File> queue;
private final FileFilter fileFilter;
private final File root;
class CrawlerThread extends Thread { /* 看后面 */}
class IndexerThread extends Thread { /* 看后面 */}
// 启动服务
public void start() {
producer.start();
consumer.start();
}
/*
* 停止服务。这里只能先中断生产者,当生产者响应中断后,会在队列尾放入
* 一个终结标示对象
*/
public void stop() {
producer.interrupt();
}
/*
* 等待服务关闭。即这里要等待消费线程完成。该方法用在调用stop方法后,用
* 来等待服务关闭,这里模拟了ExecutorService的shutdown与awaitTermination
* 方法
*/
public void awaitTermination() throws InterruptedException {
consumer.join();
}
}
class CrawlerThread extends Thread {// 生产者
void run() {
try {
crawl(root);
} catch (InterruptedException e) {
/*
* 如果文件很多,且生产者快于消费者时,则外界可以调用stop方法,
* 给生产线程发送一个中断请求,这里就会捕获到,然后就会跳出
* crawl 方法
*/
} finally {
while (true) {
try {
queue.put(POISON);
break;// 如果是正常放入终结标示对象后直接跳出循环
} catch (InterruptedException e1) {
/*
* 如果队列满后在放入终结标示对象时如果线程再次被中断,
* 则程序会跳到这里执行,这时我们不能退出生产线程,因
* 为标示对象还未放入,所以为会将queue.put放在了无限
* 循环中了,并且try还得要在循环里
*/
}
}
}
}
private void crawl(File root) throws InterruptedException {
...//向队列中放的过程
}
}
class IndexerThread extends Thread {//消费者
public void run() {
try {
while (true) {
File file = queue.take();
//如果从队列中取出的是标示对象,则退出程序
if (file == POISON)
break;
else
indexFile(file);
}
} catch (InterruptedException consumed) {
/*
* 对于外界的InterruptedException不理采,因为队列中很可能
* 还有大批的任务等着该消费线程去处理,该线程的终止只依赖
* 于生产线程
*/
}
}
}
如果有多个生产者,可以对单个生者进行扩充:在每个生产者在结束时都要放入一个终结标示对象,但消费者线程先要等知道生产者数量,并且等取所有终结标示对象后再能退出消费线程。
这种通过终结标示对象来关闭服务的方式只有在无限队列中工作时,才是可靠的,因为如果是有限的时在放入标示对象时可能会阻塞,这又可能会引发中断异常。
boolean checkMail(Set<String> hosts, long timeout, TimeUnit unit)
throws InterruptedException {
ExecutorService exec = Executors.newCachedThreadPool();
//这里不能使用 volatile hasNewMail,因为还需要在匿名内中修改
final AtomicBoolean hasNewMail = new AtomicBoolean(false);
try {
for (final String host : hosts)//循环检索每台主机
exec.execute(new Runnable() {//执行任务
public void run() {
if (checkMail(host))
hasNewMail.set(true);
}
});
} finally {
exec.shutdown();//因为ExecutorService只在这个方法中服务,所以完成后即可关闭
exec.awaitTermination(timeout, unit);//等待任务的完成,如果超时还未完成也会返回
}
return hasNewMail.get();
}
当通过shutdownNow强行关闭一个ExecutorService时,它试图取消正在进行的任务,并返回那些已经提交但并没有开始运行的任务清单,这样,这些任务可以被日志记录,或者存起来等待进一步处理(shutdownNow返回的Runnable对象列表可能并不是提交给ExecutorService的相同对象:它们可能是经过包装的已提交任务的实例)。
然而,我们并没有好的方法来找出那此已经开始、却没有结束的任务。这也就是说,我们不可以在关闭时知道进行中的任务的状态,除非任务本身设置了某些检查点。为了知道哪些任务没有完成,你不仅需要知道哪些任务还没有开始,而且还应该知道在executor关闭时哪些任务正在进行中(不幸的是,关闭选择只会把那些还没有开始的任务返回给调用者,但是不会包括那些正在运行的任务,如果有这样的支持,会给程序增加一些不确定性的东西)。
shutdownNow只返回了还未开始运行的任务,如果我们还想知道哪些正在运行任务是因为调用shutdownNow而被取消的,TrackingExecutor展现了如何记录那些在关闭后还未执行完的任务,它可以识别哪些任务已经开始但没有正常结束。为了应用这个技术,任务(run方法)必须在返回时恢复中断状态,这也是每个程序应该做到的。
public class TrackingExecutor extends AbstractExecutorService {
private final ExecutorService exec;
private final Set<Runnable> tasksCancelledAtShutdown =
Collections.synchronizedSet(new HashSet<Runnable>());
public TrackingExecutor(ExecutorService exec) {
this.exec = exec;
}
public List<Runnable> getCancelledTasks() {//返回被取消的任务
if (!exec.isTerminated())//如果shutdownNow未调用或调用未完成时
throw new IllegalStateException(/*...*/);
return new ArrayList<Runnable>(tasksCancelledAtShutdown);
}
public void execute(final Runnable runnable) {
exec.execute(new Runnable() {
public void run() {
try {
runnable.run();
/*
* 实质上在这里会有线程安全性问题,存在着竞争条件,比如程序刚
* 好运行到这里,即任务任务(run方法)刚好运行完,这时外界调用
* 了shutdownNow(),这时下面finally块中的判断会有出错,明显示
* 任务已执行完成,但判断给出的是被取消了。如果要想安全,就不
* 应该让shutdownNow在run方法运行完成与下面判断前调用。我们要
* 将runnable.run()与下面的if放在一个同步块、而且还要将
* shutdownNow的调用也放同步块里并且与前面要是同一个监视器锁,
* 这样好像就可以解决了,不知道对不能。书上也没有说能不能解决,
* 只是说有这个问题!但反过来想,如果真的这样同步了,那又会带
* 性能上的问题,因为什么所有的任务都会串形执行,这样还要
* ExecutorService线程池干嘛呢?我想这就是后面作者为什么所说
* 这是“不可避免的竞争条件”
*/
} finally {
//如果调用了shutdownNow且运行的任务被中断
if (isShutdown()
&& Thread.currentThread().isInterrupted())
tasksCancelledAtShutdown.add(runnable);//记录被取消的任务
}
}
});
}
// 将ExecutorService 中的其他方法委托到exec
}
下面的WebCrawler展示了TrackingExecutor的应用。Web Crawler的工作通过是无尽的,所以在Crawler关闭时保存它的状态,这样可以在下次启动时继续前一状态继续运行。由于TrackingExecutor存在不可避免的竞争条件,使它产生假阳性现象:识别出的被取消任务事实上可能已经结束,产生的原因是在任务执行的最后一条件指令,以及线程池记录为完成任务之间(and when the pool records the task as complete)。如果两次执行的结果与执行一次相同,那么这不会有会么问题,这个例子就是这样。另外,应用程序得到已被取消的任务必须注意这个风险,应该为这样的假阳性现象作好准备。
//web爬虫
public abstract class WebCrawler {
private volatile TrackingExecutor exec;
private final Set<URL> urlsToCrawl = new HashSet<URL>();
private final ConcurrentMap<URL, Boolean> seen = new ConcurrentHashMap<URL, Boolean>();
private static final long TIMEOUT = 500;
private static final TimeUnit UNIT = TimeUnit.MILLISECONDS;
public WebCrawler(URL startUrl) {
urlsToCrawl.add(startUrl);
}
public synchronized void start() {
exec = new TrackingExecutor(Executors.newCachedThreadPool());
for (URL url : urlsToCrawl)
submitCrawlTask(url);
urlsToCrawl.clear();
}
public synchronized void stop() throws InterruptedException {
try {
saveUncrawled(exec.shutdownNow());//保存还未开始的任务
if (exec.awaitTermination(TIMEOUT, UNIT))
saveUncrawled(exec.getCancelledTasks());//保存被取消的任务
} finally {
exec = null;
}
}
//具体对每个URL的处理由子类实现,并返回这个页面所有链接
protected abstract List<URL> processPage(URL url);
private void saveUncrawled(List<Runnable> uncrawled) {
for (Runnable task : uncrawled)
//取出未做完或没做的URL并保存
urlsToCrawl.add(((CrawlTask) task).getPage());
}
//提交任务爬虫任务
private void submitCrawlTask(URL u) {
exec.execute(new CrawlTask(u));
}
//每个URL一个爬虫任务
private class CrawlTask implements Runnable {
private final URL url;
CrawlTask(URL url) {
this.url = url;
}
//private int count = 1;
boolean alreadyCrawled() {
return seen.putIfAbsent(url, true) != null;
}
void markUncrawled() {
seen.remove(url);
System.out.printf("marking %s uncrawled%n", url);
}
public void run() {
for (URL link : processPage(url)) {
//如果任务线程被中断,则响应中断语法,即退出任务
if (Thread.currentThread().isInterrupted())
return;
submitCrawlTask(link);//继续对象每个页面中的链接进行处理
}
}
public URL getPage() {
return url;
}
}
}
如果在一个线程中启动另一个线程,另一个线程中抛出异常,如果没有捕获它,这个异常也不会传递到父线程中。
导致线程死亡的最主要原因是RuntimeException。因为这些异常表明一个程序错误或者其他不可修复的错误,它们通常不能被捕获,一旦发生这种异常又没有捕获,这个异常将会沿着调用的栈传递到JVM中,最终默认的行为是在控制台打印栈的异常信息,并终止线程。
任何代码都可能抛出RuntimeException异常,无论在何时,你都要怀疑它,不要盲目地认为它一定能返回。
处理任务的线程,在处理任务时我们一定要将它要执行的任务放在try-catch块中执行或者是使用try-finally块来确保框架能够知晓线程的非正常退出,并作出正确的反应。当我们调用未知道代码时,如Executor框架中执行的Runnable或Callable任务时,运行时不知道会抛出什么样RuntimeExceptionwhen的异常,这也是我们为数不多捕获RuntimeExceptionwhen几次。对于捕获运行时异常可能会有一些争议,但当程序抛出一个运行时异常时,整个应用程序都可能受到威胁,所以从系统安全角度来看,这种捕获运行异常是可取的,对自己写的代码我们是不允许这样做的,但对于未知的代码,这样做也是无可厚非的。
下面程序展示了如何在线程池中实现一个工作者线程。如果任务抛出了一个运行时异常,它将允许线程终结,但是会首先通知框架:线程已经终结。然后框架可能会用新的线程取代这个工作线程,也可能不这样做,因为线程池也许正在关闭,或者是池中线程充足。ThreadPoolExecutor和Swing使用这技术来确保那些不能正常运转的任务不会影响到后续任务的执行。
典型的线程池工作线程的实现:
public void run() {//工作者线程的实现
Throwable thrown = null;
try {
while (!isInterrupted())
runTask(getTaskFromWorkQueue());
} catch (Throwable e) {//为了安全,捕获的所有异常
thrown = e;//保留异常信息
} finally {
threadExited(this, thrown);// 重新将异常抛给框架后终结工作线程
}
}
前面小节中讲述了一种主动解决运行进异常的问题的方案,类库中同样提供了UncaughtExceptionHandler线程异常捕获工具类,它可以捕获到从线程中抛出的未捕获的异常。
当一个线程因为未捕获异常而退出时,JVM会把这个事件报告给应用程序提供的UncaughtExceptionHandler;如果处理器handler不存在,默认的行为是向System.err打印出栈的追踪信息。
在1.5以前,操控UncaughtExceptionHandler唯一的方法是子类化ThreadGroup。在1.5以及以后版本,你可以通过Thread. setUncaughtExceptionHandler为每个线程设置一个UncaughtExceptionHandler;也可以使用setDefaultUncaughtExceptionHandler来设置默认的UncaughtExceptionHandler。然而,只有其中一个处理器能够被调用——JVM首先寻找针对每个线程的处理器,然后再查找ThreadGroup的。
未捕获到的异常处理首先由线程自己控制(由Thread. setUncaughtExceptionHandler设置的未捕获异常处理器),然后由线程的 ThreadGroup 对象控制,最后由未捕获到的默认异常处理程(由Thread. setDefaultUncaughtExceptionHandler设置的未捕获异常处理器)序控制。如果线程不设置明确的未捕获到的异常处理程序,并且该线程的线程组(包括父线程组)未特别指定其 uncaughtException 方法(即重写),则将调用默认处理程序(由Thread. setDefaultUncaughtExceptionHandler设置的未捕获异常处理器)的 uncaughtException 方法。
为了给线程池(ExecutorService)设置UncaughtExceptionHandler,需要向ThreadPoolExecutor的构造函数提供一个ThreadFactory。标准的线程池(ExecutorService)允许任务抛出未捕获的异常去终止任务线程,但是当任务线程终止后,使用一个try-finally块来接收通知的话,就能够用新的线程取代它。如果没有未捕获异常的处理器,又没有其他失败通知机制,任务将会无声无息地失败。如果你想在任务因异常而失败时获得通知,那么你应该采取一些特定的任务恢复机制,或者是用Runnable与Callable把任务包装起来提交给ExecutorService执行,然后通过Future.get来获取任务执行时抛出的异常(如果任务是Thread子类,此时即使为这个任务设置了异常处理器,此时也不会起作用,而是将异常封装在Future对象里了),或者是重写ThreadPoolExecutor的afterExecute(Runnable r,Throwable t)钩子方法,这样就能够捕获异常,
要注意的是,Executor框架中的任务未捕获异常处理器只有捕获处理通过execute提交的任务,而通过submit提交的任务,抛出的任何异常,都会封装在任务Future里,如果有一个以submit提交的任务以异常而终止,这个异常会被Future.get重新抛出,这些异常并包装在ExecutionException(注,只有任务本身所抛出的异常再封装成这种异常,比如CancellationException异常就不会,因为这不是任务本身所抛出的)。
下面是Executor框架中的UncaughtExceptionHandler处理器实现:
// 会抛出异常的线程
class ExceptionThread implements Runnable {
public void run() {
Thread t = Thread.currentThread();
System.out.println("run() by " + t);
System.out.println("1.eh = " + t.getUncaughtExceptionHandler());
throw new RuntimeException();//线程运行时一定会抛出运行异常
}
}
// 线程未捕获异常处理器
class MyUncaughtExceptionHandler implements Thread.UncaughtExceptionHandler {
// 异常处理方法
public void uncaughtException(Thread t, Throwable e) {
System.out.println("caught : ");
e.printStackTrace();
}
}
/*
* 线程工厂,Executor框架在创建线程时会调用该工厂,ThreadFactory为
* Executor框架定义的线程创建工作接口,它的作用是创建线程时能为这个
* 线程做一些其它的事件,如这里给它设置一个未捕获异常处理器。
*/
class HandlerThreadFactory implements ThreadFactory {
public Thread newThread(Runnable r) {//线程创建工厂方法
System.out.println(this + " creating new Thread");
Thread t = new Thread(r);
t.setName("exception thread");
System.out.println("created " + t);
//设置异常处理器
t.setUncaughtExceptionHandler(new MyUncaughtExceptionHandler());
System.out.println("2.eh = " + t.getUncaughtExceptionHandler());
return t;
}
}
public class CaptureUncaughtException {
public static void main(String[] args) {
ExecutorService exec = Executors
.newCachedThreadPool(new HandlerThreadFactory());
//未捕获异常处理器会捕获到工作线程的所抛出的异常
exec.execute(new ExceptionThread());
/*
* 注,submit提交的任务抛出的异常是不能被未捕获异常处理捕获到的
* 因为该异常已经通过Future传递到了executor框架线程中来了,并且
* 任务抛出异常后,调用future.get时就会重新抛出这个异常
*/
Future<?> f = exec.submit(new ExceptionThread());
try {
//future.get会重新抛出任务执行时所未捕获到异常
System.out.println(f.get());
} catch (Exception e) {
e.printStackTrace();
}
}
}
JVM既可通过正常手段来关闭,也可强行关闭。
正常关闭:当最后一个“正常(非守护)”线程结束时、当有人调用了System.exit时、使用操作系统相关手段(如按Ctrl - C)。
强行关闭:Runtime.halt(应小心使用此方法。与 exit 方法不同,此方法不会启动关闭挂钩,并且如果已启用退出终结,此方法也不会运行未调用的终结方法。如果已经发起关闭序列,那么此方法不会等待所有正在运行的关闭挂钩或终结方法完成其工作)、杀死JVM操作系统进程(比如在 Unix 上使用 SIGKILL 信号)。注,这种强行关闭方式将无法保证是否将运行关闭钩子。
在正常的关闭过程中,JVM首先启动所有已注册的关闭钩子(Shutdown hook)。关闭钩子是使用Runtime.addShutdownHook方法进行注册的但尚未开始运行的线程。JVM并不能保证关闭钩子的开始顺序。注意,JVM在关闭期间,会继续运行守护线程,如果通过调用 exit 方法来发起关闭操作,那么也会继续运行非守护线程,它们会与关闭钩子并发运行。当所有关闭钩子运行结束完所有的挂钩后,如果已启用退出终结(Runtime.runFinalizersOnExit(true)),那么虚拟机接着会运行所有未调用的终结方法(finalize)。在关闭期间,JVM不会尝试停止或中断仍然在运行中的应用程序线程,它们会在JVM最终停止时被强行关闭。如果关闭钩子或finalizers没有完成,那么orderly关闭进程“挂起”并且JVM必须强行关闭。在强行关闭中,JVM不需要完成除了关闭JVM以外的任何事情,不会运行关闭钩子。
关闭钩子应该是线程安全的:它们在访问共享数据时必须使用同步,并应该小心地避免死锁。
关闭挂钩应该快速地完成其工作,当程序调用 exit 时,虚拟机应该迅速地关闭并退出。由于用户注销或系统关闭而终止虚拟机时,底层的操作系统可能只允许在固定的时间内关闭并退出。因此在关闭挂钩中尝试进行任何用户交互或执行长时间的计算都是不明智的。
与其他线程一样,我们可以为它置一个UncaughtExceptionHandler处理器,在抛出未捕获到的异常时来处理异常。
关闭钩子可用于服务或应用程序的清理,比如删除临时文件,或者消除OS不能自动清除的资源。如 LogService中在start方法中注册了一个关闭钩子,用来确保它的退出时关闭日志文件,请参考关闭ExecutorService章节。
关闭钩子都是并发执行的,关闭日志文件可能会引起其他需要使用日志服务的关闭钩子的麻烦。为了避免这个问题,关闭钩子不应该依赖于应用程序或其他关闭钩子的服务。实现它的一种方式是所有服务使用唯一关闭钩子,让它来调用一系列的关闭动作,这样就避免了竞争的出,确保了它们顺序执行与死锁的出现。
有时想要创建一个线程,执行一些辅助工作,但不希望这个线程阻碍JVM的关闭,这时就需要守护线程。
JVM在启动时创建的线程,除了主线程之外其他线程都是守护线程(如垃圾回收和其他类似线程)。由非守护线程创建出的线程为非守护性线程,由守护线程创建出的线程为守护线程,默认情况下,任何主线程创建的线程都是普通线程。
当系统退出时,JVM会检查运行中的线程清单,如果只有守护线程,则会退出。当JVM停止时,所有仍在运行的守护线程都会被抛弃——不会执行finally块,也不会释放栈——JVM直接退出。
应该小心地使用守护线程,几乎没有哪些活动的处理可以在不进行清理的情况下,可以被安全的抛弃,特别运行I/O操作的守护线程是很危险的。它一般用于普通的管理,如用它从内存中周期性地移除过期的数据。
请参见EJXXXX
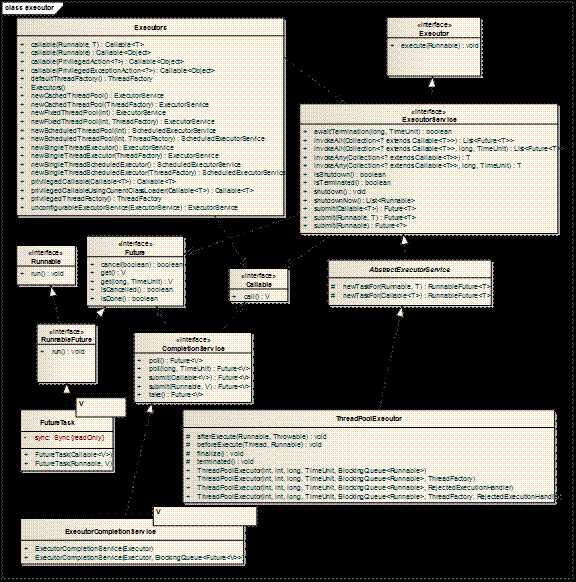
Executor框架可以将任务与执行策略解耦,这其实有些言过其实了。并不是所有任务都适合于Executor框架的执行策略,有些类型的任务是需要明确地指定一个执行策略的:
1、 依赖性任务:当线程池中运行任务都是独立的时,我们可以随意地修改池的长度与配置,这不会影响到性能以外的任何事情。但如果你提交到线程池中的任务依赖于其他的任务,这就会隐式地给执行策略带来了约束。
2、 非安全性任务:如果即使一个任务有线程安全性问题,只要它在单线程的环境下运行是不会有问题,如将它提交到Executors.newSingleThreadExecutor,这是安全的。但是一旦提交到线程池时,就会失去线程安全。
3、 对响应时间敏感的任务:将一个长时间运行的任务提交到单线程化的Executor中,或者将多个长时间运行的任务提交给一个只包含少量线程的线程池中,会削弱由Executor管理的服务响应性。
4、 使用ThreadLocal的任务: Executor会随意重用池中的线程。标准的Executor实现是:在空闲时会回收线程,在忙时会增加新的线程,如果任务抛出异常,就会用一个全新的工作者线程取代出错的那个线程。只有当线程本地变量的生命周期被限制在某个任务线程中时,在池的某线程中使用ThreadLocal变量才有意义;不应在线程池中使用ThreadLocal变量在线程内传递值。
只有当任务都是等同的、独立的时候,线程池才会有最佳的表现。如果将耗时与短任务混合在一起,除非线程池很大,否则会有“塞车”的风险;如果提交的任务要依赖于其他的任务,除非线程池是无限的,否则会产生死锁的风险。
在线程池中如果一个任务依赖于其他任务的执行,就可能产生死锁。对于一个单线程化的Executor,如果一个任务中将另一个任务提交到相同的Executor中,并等待新提交的任务的结果,这总会引发死锁。第二个任务停留在工作队列中,直到第一个任务完成,但是第一个任务不会完成,因数它在等待第二个任务的完成。在一个大的线程池中,如果所有正在执行任务的线程因等待同一工作队列中的其他任务,也要能会发生同样的问题,这被称作线程饥饿死锁,满足以下叙述就会发生:只要池中正在执行的任务正处于无期限的阻塞中,即它们正在等待其他任务的结果,此时除非你能保证这个池足够大,否则会发生线程饥饿死锁。
不应该将线程池的大小进行硬编码,池的长度应该由某种配置机制来提供,或者利用Runtime.availableProcessors的结果,动态地进行计算。
定义线程池大小时,要避免过大与过小,如果太大,会导致CPU与内存资源竞争而影响性能,如果太小又造成资源的浪费,会对吞吐量造成损失。
对于计算要求密集型的任务,线程池长度因该为N(cpu)+1(如果一个任务发生错误或者因其他原因暂停时,刚好有一个额外的线程可以确保在这种情况CPU周期不会中断的工作),这样每个任务的利用率是高的。
对于包含了I/O和其他阻塞操作的任务,不是所有线程都处于运行中,所以你需要一个更大的池。
假设:
N(cpu)=CPU的数量=Runtime.getRuntime().availableProcessors();
U(cpu)= 期望CPU的使用率,0<=U(cpu)<=1
W/C=等待时间与运行时间的比率
为保持CPU达到期望的使用率,最优的池的大小等于:
N(threads)=N(cpu)*U(cpu)*(1+W/C)
当然CPU周期并不是唯一可以用来确定线程池大小的资源,其他可以约束线程池大小的资源包括:内存、文件句柄、套接字句柄、数据库连接等。计算这些类型线程池大小非常简单:使用可用资源的总数除以出每个任务需要的这些资源数量,结果就是池的大小。
ThreadPoolExecutor为一些Exectors提供了基本的实现,这些线程是由Executors中的工厂newCachedThreadPool、newFixedThreadPool、newScheduledThreadExecutor返回的。
如果默认的执行策略不能满足你的需要,你可以通过构造函数实例化一个ThreadPoolExecutor,它有很多个构造器,以下是参数最完整的构造器:
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler)
corePoolSize(池中所保留的线程数量,即使是空闲线程)、maximumPoolSize(池中允许最大的线程数量)、keepAliveTime(当线程数大于corePoolSize时,允许多余的空闲线程所等待新任务的最长时间,如果超过个时间将会被停止掉)。
线程池的大小会试图维持在核心池的大小,即使没有任务执行(当一个ThreadPoolExecutor被初始创建后,所有核心线程并非立即开始,而是要先到有任务提交的时刻,除非你调用prestartAllCoreThreads),池的大小也等于核心池corePoolSize的大小,并且直到工作队列充满前,池都不会创建更多的新的工作线程(注,一般不要将corePoolSize设置为0,因为如果这样的话,只有在任务队列满后再开始创建新的工作线程来执行任务,否则这些任务不会开始工作。除非池使用的任务队列是SynchronousQueue,如Executors.newCachedThreadPool工厂方法就是将核心池设为0,但它的任务队列使用的是SynchronousQueue。如果真想要这样一个特性:在没有任务后,工作线程需要销毁时,我们可以使用1.6中的allowCoreThreadTimeOut方法,它设置了核心池也是允许超时的,且该时间与非核心空闲线程超时时间是相等的,如果你有一个有限的任务,同时又要所有的线程在没有任务的情况下销毁,可以在设置池大小为非零时调用这个方法来激活这个特性)。
最大池maximumPoolSize的大小是可同时活动的线程数的上限。如果一个线程已经闲置的时间超过了存活时间keepAliveTime,安将成为一个被回收的候选者,如果当前的池的大小超过了核心池的大小,线程就会终止它。
通过调节核心大小和存活时间,可以促进线程池归还空闲线程占有的资源,让这些资源可以用于更有用工作。
newFixedThreadPool工厂设置了核心池的大小和最大池的大小是相等的,百且池永远不会超时; newCachedThreadPool工厂将最大的池设置为了Integer.MAX_VALUE,核心池的大小为0,线程池超时时间为60秒,这样创建出的的可无限扩大的线程池,会在任务减少的情况下减少线程数量。其他的组合可以使用显式地ThreadPoolExecutor来构造。
将处理不过来的任务放置在任务队列中要比为每个处理不过来的任务都创建一个线程要便宜得多。
即使通常平均请求率都很稳定,也难免会突然激增。尽管队列有助于缓和瞬时的任务激增,但是如果任务持续快速地到来,你最终还是必须要遏制住请求达到率,以避免耗尽内存。即使没有耗尽内存,响应时间会会随着任务队列的增长而逐渐地变糟。
ThreadPoolExecutor允许你提供一个BlockingQueue来持有等待执行的任务,任务排除有3种基本方法:无限队列、有限队列和同步移交。队列的选择与池的大小有关。
newFixedThreadPool与newSingleThreadExecutor默认使用的是一个无限的LinkedBlockingQueue。如果所有工作者线程都处于忙碌状态,任务将会在队列中等候,如果任务持续地快速到达,超过了它们被执行的速度,队列会无限地增加。
一个稳定的资源管理策略是使用有限的队列,如ArrayBlockingQueue或有限的LinkedBlockingQueue以及PriorityBlockingQueue(无限的,虽然可以初始化一个容量,但这个容量与ArrayList类似,不是用来限制大小的,只是初始大小而已,如果超过这个容量将也会自动增长,那写在这里是什么意思?)。有界队列有助于避免资源耗尽的情况发生,但是它又引入了新的问题:当队列满后,新的任务怎么办?有很多的饱和策略可以处理这个问题,请看后面章节。一个大队列加上一个小池,可以控制对内存与CPU的使用,还可减少上下文切换,但是吞吐量可能不佳。
对于庞大或者无限的池,你可以使用SynchronousQueue,完全绕开队列,将任务直接从生产者移交给工作者线程。它并不是一个真正的队列,而是一种管理直接在线程间移交信息的机制。为了把一个元素放入到这样的队列中,必须有一个线程正在等待接受移交任务。如果没有这样一个线程,只要当前池大小还小于最大值,ThreadPoolExecutor就会创建一个新的线程,否则根据饱和策略,任务会被拒绝。使用直接提交会更加高效,因为任务不必先入放置到队列中,就可以立即移交给任务执行线程处理。只有当池是无限的,或者可以接受任务被拒绝,SynchronousQueue才是一个有实际价值的选择。newCachedThreadPool工厂就使用了SynchronousQueue。
使用LinkedBlockingQueue 或 ArrayBlockingQueue这种FIFO的队列,会造成任务以它们到达的顺序开始执行。如果更进一步地控制任务执行顺序,你还可以使用PriorityBlockingQueue,它通过优先级按排任务。
newCachedThreadPool工厂提供了比定长的线程池更好的队列等候性能,它是Executor的一个很好的默认选择。出于资源管理的目的,当你需要限制当前任务的数量,一个定长的线程池就是很好选择。就像一个接受网络客户端请求的服务器应用程序,如果不进行限制,就会很容易因为过载而遭受攻击。
只有当任务彼此独立时,使用有限线程池或者有限工作队列的才是合理的,如果任务之间相互依赖,有限的线程池或队列就可能引起线程饥饿死锁,使用无限的池配置可以避免这样的问题,就像newCachedThreadPool(如果一个任务提交另一任务并等待它的结果,对于这种情况,还有一种可选的配置策略:使用一个受限的线程池,工作队列选用SynchronousQueue,饱和策略选择“调用者运行”策略)。
当一个有限队列充满后,饱和策略开始起作用。ThreadPoolExecutor的饱和策略可以通过调用setRejectedExecutionHandler来修改(如果任务提交到一个已经被关闭shutdown的Executor时,也会用到饱和策略)。类库提供了几种不同的RejectedExecutionHandler实现,每种都实现了不同的饱和策略:AbortPolicy,、CallerRunsPolicy、DiscardPolicy、DiscardOldestPolicy。
默认的“中止(abort)”策略会引起execute抛出未检查的RejectedExecutionException,调用者可以捕获这个异常,然后自己处理(这是为库默认采用的饱和策略);当最新提交的任务不能进入队列等待执行时,“遗弃(discard)”策略会默认放弃这个任务;“遗弃最旧的(discard-oldest)”策略选择丢弃的任务,是本应该接下来就执行的任务,丢弃后该策略还会尝试去重新提交新的任务(如果工作队列是优先级队列,那“遗弃最旧的”策略选择丢弃的刚好是优先级最高的元素,所以“遗弃最旧的”饱和特事特办和优先级队列是不可行的)。
“调用者策略(caller-runs)”策略的实现即不会丢弃那个任务,也不会抛出任何异常,它会把一些任务推回到调用者那里,以些减缓新任务流。它不会在池线程中执行最新的任务,但是它会在一个调用了execute的线程中执行。我们修改WebServer的例子,让它使用有限队列和调用者运行策略,当池中所有线程都被占用且工作队列也满后,下一个任务会在主线程(即调用execute启动任务的线程的线程)中执行,这样主线程会花费一些时间,所以主线程在一段时间内不能提交任何任务。同时这也给了工作线程有时间来追赶进度,这期间主线程也不会调用accept(因为主线程在用去执行任务了),所以外来的请求不会出现在应用程序中,而会在TCP层的队列中等候。这样如果高负载时,最终由TCP层判断它的连接请求队列是否已经排满,如果已满就开始丢弃请求任务。当服务器过载时,它的负荷会逐渐地外移——从池线程到工作队列到应用程序再TCP层,最终转移到用户头上——这使得服务器在高负载下可以逐步缓解。
前面讨论的是当池满后的饱和策略,如果工作队列满后,并没有预置的饱和策略来阻塞execute(即任务的提交),但是使用Semaphore(信号量)可以实现这个效果。设置Semaphore的限制范围等于在池的大小上加上你希望允许的可以排队的任务数量。下面是一个使用Semaphore来限制任务的提交:
@ThreadSafe
public class BoundedExecutor {
private final Executor exec;
private final Semaphore semaphore;
public BoundedExecutor(Executor exec, int bound) {
this.exec = exec;
this.semaphore = new Semaphore(bound);
}
public void submitTask(final Runnable command)
throws InterruptedException {
semaphore.acquire();
try {
exec.execute(new Runnable() {
public void run() {
try {
command.run();
} finally {
semaphore.release();
}
}
});
} catch (RejectedExecutionException e) {
semaphore.release();
}
}
}
线程池创建一个线程,都要通过一个线程工厂来完成,这个工厂接口如下:
public interface ThreadFactory {
Thread newThread(Runnable r);
}
ThreadPoolExecutor的默认的线程工厂创建一个新、非后台线程,并没有特别的配置。由工厂创建出来的线程为工作者线程,它是以ThreadPoolExecutor.Worker为基础来创建的,我们所提交的任务最后由Worker来执行,而且每个Worker对象反过来又持有线程工厂创建出来的工作线程,具体实现:由ThreadFactory.newThread(Runnable runnable)来创建一个工作线程,参数runnable就是ThreadPoolExecutor.Worker工作者,而Worker是一个实现了Runnable的类,它的run方法实现是在循环中不停的从队列中取任务然后执行任务,下面从提交一个任务所涉及到的方法,ExecutorService.submit(Runnabel)方法会调用execute方法,以下是ThreadPoolExecutor中的方法:
publicvoidexecute(Runnable command) {
if (command == null)
thrownew NullPointerException();
if (poolSize >= corePoolSize || !addIfUnderCorePoolSize(command)) {
//如果提交任务时,线程池已满,且线程池处于运行状态时,则将任务存放到任务队列中稍后运行任务
if (runState == RUNNING && workQueue.offer(command)) {
//如果线程现在的状态不为运行(虽然外层条件语句已经要求是运行状态,但这里没有使用同步,所以程序运行到这里状态可能已经被修改了,所以需重新判断),或者线程池中没有工作线程了时
if (runState != RUNNING || poolSize == 0)
ensureQueuedTaskHandled(command);
}
elseif (!addIfUnderMaximumPoolSize(command))
reject(command); // is shutdown or saturated
}
}
privatevoidensureQueuedTaskHandled(Runnable command) {
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
boolean reject = false;
Thread t = null;
try {
int state = runState;
//如果在线程池处于非运行状态的情况下将任务存入了任务队列的情况,直接拒绝(由于ThreadPoolExecutor这些提交任务的方法未使用同步,只是做了简单判断,所以当程序运行到这里时,该任务很有可能已经在execute方法里就已存入任务队列了:workQueue.offer(command),但入队前基他线程已修改线程池状态)
if (state != RUNNING && workQueue.remove(command))
reject = true;
//如果线程池不是停止或终止状态,线程池未满或空,且任务队列不为空时,则重新创建一个工作线程去执行还未执行完的任务
elseif (state < STOP &&
poolSize < Math.max(corePoolSize, 1) &&
!workQueue.isEmpty())
t = addThread(null);
} finally {
mainLock.unlock();
}
if (reject)
reject(command);
elseif (t != null)
t.start();
}
privatebooleanaddIfUnderCorePoolSize(Runnable firstTask) {
Thread t = null;
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
//如果线程池未满,且是运行状态时,新创建一个工作线程
if (poolSize < corePoolSize && runState == RUNNING)
t = addThread(firstTask);
} finally {
mainLock.unlock();
}
if (t == null)
returnfalse;
t.start();
returntrue;
}
private Thread addThread(Runnable firstTask) {
//Worker实现了Runnable接口,且持有任务
Worker w = new Worker(firstTask);
//基于Worker创建一个新的工作线程
Thread t = threadFactory.newThread(w);
if (t != null) {
//Worker又反过来持有工作线程
w.thread = t;
//将工作者(线程)放入池中(HashSet<Worker>)
workers.add(w);
int nt = ++poolSize;
if (nt > largestPoolSize)
largestPoolSize = nt;
}
return t;
}
下面是ThreadPoolExecutor的内部类Worker的相关方法:
/**
* Main run loop
*/
publicvoid run() {
try {
Runnable task = firstTask;
firstTask = null;
//不停的从任务队列中获取任务并执行
while (task != null || (task = getTask()) != null) {
runTask(task);//执行任务,直接调用任务接口(Ruunable,如果是Callable,则在执行前会转换成FutureTask接口)的run方法
task = null;
}
} finally {
workerDone(this);
}
}
//为正在运行的工作线程从任务队列中获取下一个任务
Runnable getTask() {
for (;;) {
try {
int state = runState;
if (state > SHUTDOWN)
returnnull;
Runnable r;
if (state == SHUTDOWN) // Help drain queue
r = workQueue.poll();
elseif (poolSize > corePoolSize || allowCoreThreadTimeOut)
r = workQueue.poll(keepAliveTime, TimeUnit.NANOSECONDS);
else
r = workQueue.take();//从队列中阻塞获取任务
if (r != null)
return r;
if (workerCanExit()) {
if (runState >= SHUTDOWN) // Wake up others
interruptIdleWorkers();//中断所有其他工作线程
returnnull;
}
// Else retry
} catch (InterruptedException ie) {
// On interruption, re-check runState
}
}
}
下面自己定义一个线程工厂:
public class MyThreadFactory implements ThreadFactory {
private final String poolName;
public MyThreadFactory(String poolName) {
this.poolName = poolName;//线程池名称
}
public Thread newThread(Runnable runnable) {//参数为工作者Worker
return new MyAppThread(runnable, poolName);
}
}
public class MyAppThread extends Thread {//扩展Thread,该线程将成为池中的工作线程 public static final String DEFAULT_NAME = "MyAppThread";//线程池默认名称
private static volatile boolean debugLifecycle = false;//是否需要记录日志
private static final AtomicInteger created = new AtomicInteger();//已创建线程数
private static final AtomicInteger alive = new AtomicInteger();//正在运行的线程数
private static final Logger log = Logger.getAnonymousLogger();//匿名日志记录器
public MyAppThread(Runnable r) { this(r, DEFAULT_NAME); }
public MyAppThread(Runnable runnable, String name) {
super(runnable, name + "-" + created.incrementAndGet());
setUncaughtExceptionHandler(//未捕获异常处理器
new Thread.UncaughtExceptionHandler() {
public void uncaughtException(Thread t,
Throwable e) {
log.log(Level.SEVERE,//如果出现异常记录异常日志
"UNCAUGHT in thread " + t.getName(), e);
}
});
}
public void run() {
// 从主存中复制debug,确保它的值在这个方法里是一致的
boolean debug = debugLifecycle;
if (debug) log.log(Level.FINE, "Created "+getName());
try {
alive.incrementAndGet();//正在运行的线程数量加1
super.run();//调用ThreadPoolExecutor.Worker的run方法
} finally {
alive.decrementAndGet();//运行完后减1
if (debug) log.log(Level.FINE, "Exiting "+getName());
}
}
public static int getThreadsCreated() { return created.get(); }
public static int getThreadsAlive() { return alive.get(); }
public static boolean getDebug() { return debugLifecycle; }
public static void setDebug(boolean b) { debugLifecycle = b; }
}
大多数通过ThreadPoolExecutor构造函数传入的参数(如核心池大小、最大池大小、存活时间、线程工厂、拒绝执行处理器),都可以在创建后通过相应的setters方法进行修改。如果Executor是通过Executors中的某个工厂方法(如newFixedThreadPool、newCachedThreadPool,但newSingleThreadExecutor除外),你可以像下面程序那样,首先把结果转型为ThreadPoolExecutor,然后访问setters方法。
ExecutorService exec = Executors.newCachedThreadPool();
if (exec instanceof ThreadPoolExecutor)
((ThreadPoolExecutor) exec).setCorePoolSize(10);
else
throw new AssertionError("Oops, bad assumption");
Executors中包括了一个unconfigurableExecutorService(ExecutorService executor)的工厂方法,它返回一个DelegatedExecutorService的实现,它只暴露出了ExecutorService接口(实质上就是接口窄化),因此不能进行一步配置。newSingleThreadExecutor也是这样,返回的实现是对ThreadPoolExecutor实例再次封装,而不是原始的ThreadPoolExecutor,这样你也不能再进一步的进行配置了,因为毕竟单线程池只需要一个线程即可,如果暴露了ThreadPoolExecutor接口,则可能因用户修改而造成其他的问题。
你也可以将上面的这种包装技术用在你自己的Executor中,来执行策略被修改。如果将ExecutorService暴露给你不信任的代码,如果不不希望它会被修改,可以使用unconfigurableExecutorService来包装它。
ThreadPoolExecutor提供了几个“钩子”让子类去重写——beforeExecute, afterExecute、terminate——这里可扩展它的行为。
执行任务的线程会调用钩子函数beforeExecute, afterExecute,它们会在ThreadPoolExecutor.Worker.runTask中被调用,以下是Worker.runTask方法片断:
beforeExecute(thread, task);//执行任务前调用beforeExecute钩子。注,如果该方法抛出一个RuntimeException,任务将不被执行,afterExecute钩子也不会被执行。
try {
task.run();//执行任务
ran = true;
afterExecute(task, null);//任务执行完成后调用afterExecute钩子
++completedTasks;
} catch (RuntimeException ex) {
if (!ran)
afterExecute(task, ex);//如果任务执行失败,则也会调用afterExecute钩子,注,如果抛出的是Error将不会执行。
throw ex;
}
terminate钩子会在线程池关闭时调用(shutdown、shutdownNow)。它可用来释放Executor在生命周期里分配到的资源,还可以发出通知、记录日志或者完成统计信息。
public class TimingThreadPool extends ThreadPoolExecutor {
//开始时间必须是ThreadLocal型的变量,因为这个变量是记录每个线程执行任务时间
private final ThreadLocal<Long> startTime = new ThreadLocal<Long>();
private final Logger log = Logger.getLogger("TimingThreadPool");
private final AtomicLong numTasks = new AtomicLong();
private final AtomicLong totalTime = new AtomicLong();
//在执行任务前调用,如果抛出异常,则不会再执行任务与后面的afterExecute
protected void beforeExecute(Thread t, Runnable r) {
super.beforeExecute(t, r);
log.fine(String.format("Thread %s: start %s", t, r));
startTime.set(System.nanoTime());//每个任务的开始时间
}
//在调用任务后调用,不管任务是成功还是失败都会执行
protected void afterExecute(Runnable r, Throwable t) {
try {
long endTime = System.nanoTime();
long taskTime = endTime - startTime.get();//每个任务的结束时间
numTasks.incrementAndGet();//已完成的任务数
totalTime.addAndGet(taskTime);//任务执行累计时间
log.fine(String.format("Thread %s: end %s, time=%dns", t, r,
taskTime));
} finally {
super.afterExecute(r, t);
}
}
//池关闭时调用
protected void terminated() {
try {
log.info(String.format("Terminated: avg time=%dns", totalTime.get()
/ numTasks.get()));//任务的平均时间
} finally {
super.terminated();
}
}
}
如果一个循环的每次迭代都是独立的,并且我们不必等待所有的迭代都完成后再一起处理,那么我们可以使用Executor把一个的循环转化为并行的循环:
void processSequentially(List<Element> elements) {//转换前
for (Element e : elements)
process(e);
}
void processInParallel(Executor exec, List<Element> elements) {//转换后
for (final Element e : elements)
exec.execute(new Runnable() {
public void run() { process(e); }//耗时处理
});
}
上面是不必等待所有任务都执行完后再处理,当然如果你需要提交一批任务并等待它们完成,那么可以使用ExecutorService.invokeAll;如果只要提交一批任务后只要有结果就开始处理时,可以使用CompletionService来获取结果,就像《示例:使用CompletionService的页面渲染器》中的Renderer。
循环并行化同样还可以应用于一些递归设计中,下面是以深度优先遍历一棵树,并在每个节点上执行计算,把结果放入一个容器:
public<T> void sequentialRecursive(List<Node<T>> nodes,
Collection<T> results) {//顺序深度遍历
for (Node<T> n : nodes) {
results.add(n.compute());//串行计算
sequentialRecursive(n.getChildren(), results);//递归
}
}
public<T> void parallelRecursive(final Executor exec,
List<Node<T>> nodes,
final Collection<T> results) {
for (final Node<T> n : nodes) {//顺序深度遍历
exec.execute(new Runnable() {
public void run() {
results.add(n.compute());//并行计算
}
});
parallelRecursive(exec, n.getChildren(), results); //递归
}
}
等待上面并行运行的结果:
public<T> Collection<T> getParallelResults(List<Node<T>> nodes)
throws InterruptedException {
ExecutorService exec = Executors.newCachedThreadPool();
Queue<T> resultQueue = new ConcurrentLinkedQueue<T>();
parallelRecursive(exec, nodes, resultQueue);
exec.shutdown();//计算完后关闭池
//虽然设置了超时,但时间为Long.MAX_VALUE,所以这里一直阻塞到所有并行计算都完成
exec.awaitTermination(Long.MAX_VALUE, TimeUnit.SECONDS);
return resultQueue;
}
使用线程最主要的目的是提高性能,充分利用空闲的资源,同时也能提高系统的响应性。
尽管多线程的目的是提高性能,与间线程方法相比,使用多线程总会引入一些性能上的开销:与协调线程相关的开销(加锁、信号、内存同步),增加的上下文切换,线程的创建与消亡,以及调度的开销。所以如果过度使用可能适得其反。
如果可运行的线程数大于CPU的数量,那么OS最终会强行换出正在执行的线程,从而使其他线程能够使用CPU,这会引起上下文切换,它会保存当前运行线程的执行上下文,并重建新调入线程的执行上下文。切换上下文是要付出代价的,线程的调度需要操控OS与JVM中共享的数据结构,你的程序与OS、JVM使用相同的CPU,CPU在JVM和OS的代码花费越多时间,意味着用于你的程序的时间就越少。
当线程因为竞争一个锁而阻塞时,JVM通常会将这个线程挂起,允许它被换出。如果线程频繁发生阻塞,那线程就不能将分给它的时钟用完。一个程序发生越多的阻塞(阻塞I/O、等待竞争锁、或者等待条件变量),与受限于CPU的程序相比,就会造成越多的上下文切换,这增加了调度的开锁,并减少了吞量。
切换上下文真正的开锁根据不同的平台而不同,但在大多数处理器中,开销相当于5000到10000个时钟周期,或者几微秒。Unix系统的vmstat命令与Windows系统的perfmon工具都能报告上下文切换次数和内核战用的时间等信息,高内核占用率(超过10%)通常表示频繁的调度活动,这很可能是由I/O阻塞或竞争锁引起的。
串行化会损害可伸缩性,上下文切换会损害性能。竞争锁会同时导致这两种损失,所以减少锁的竞争能够改进性能和可伸缩性。减少锁的竞争3种方式:
1、 减少持有锁的时间;
2、 减少请求锁的频率;
3、 或者用协调机制取代独占锁,从而允许更强的并发性。
减少锁竞争的有效方法是尽可能缩短把持锁的时间。这可以通过把锁无关的代码移出到synchronized块来实现,尤其是那些花费时间长的操作,以前阻塞操作。
减少锁的粒度,可以通过分拆锁(一个分成两个,适用于中等竞争强度的锁)和分离锁(一个分成多个,适用于竞争激烈的锁)来实现,这样就会减少对同一锁的调用频度,可伸缩性得以提高,这比使用一个锁来锁住整个对象具有高并发性。
ConcurrentHashMap就采用了锁分离技术,它使用了一个包含16个锁的Array,每个锁都守护Hash Bucket的1/16;Bucket N 由第 N mod 16个锁来守护,这会把对于锁的请求减少到约为原来的1/16。这项技术能够支持16个并发的Writer。锁分离的一个负作用就是对整容器进行操作时,进行独占访问更加的困难,并且可能更加的昂贵。
减少上下文切换的开销关键在于将阻塞方法的调用放入另一线程中进行调用。
java程序中串行化首要的来源是独占的资源锁,所以可伸缩性通常可能通过以下这些方法提升:减少用于获取锁的时间、减少锁的粒度、减少锁的占用时间、或者用非独占锁(ReadWriteLock)或非阻塞锁来取代独占锁。
下面是一个使用Semaphore(信号量)实现的有界缓存(在实际工作中应该使用ArrayBlockingQueue 或 LinkedBlockingQueue):
public class BoundedBuffer<E> {
//可用信号量、空间信号量
private final Semaphore availableItems, availableSpaces;
private final E[] items;//缓存
private int putPosition = 0, takePosition = 0;//放、取索引位置
public BoundedBuffer(int capacity) {
availableItems = new Semaphore(0);//初始时没有可用的元素
availableSpaces = new Semaphore(capacity);//初始时空间信号量为最大容量
items = (E[]) new Object[capacity];
}
public boolean isEmpty() {
//如果可用信号量为0,则表示缓存为空
return availableItems.availablePermits() == 0;
}
public boolean isFull() {
//如果空间信号量为0,表示缓存已满
return availableSpaces.availablePermits() == 0;
}
public void put(E x) throws InterruptedException {
availableSpaces.acquire();//阻塞获取空间信号量
doInsert(x);
availableItems.release();//可用信号量加1
}
public E take() throws InterruptedException {
availableItems.acquire();
E item = doExtract();
availableSpaces.release();
return item;
}
private synchronized void doInsert(E x) {
int i = putPosition;
items[i] = x;
putPosition = (++i == items.length) ? 0 : i;
}
private synchronized E doExtract() {
int i = takePosition;
E x = items[i];
items[i] = null;//加快垃圾回收
takePosition = (++i == items.length) ? 0 : i;
return x;
}
}
public class BoundedBufferTest extends TestCase {
//刚构造好的缓存是否为空测试
public void testIsEmptyWhenConstructed() {
BoundedBuffer<Integer> bb = new BoundedBuffer<Integer>(10);
assertTrue(bb.isEmpty());
assertFalse(bb.isFull());
}
//测试是否满
public void testIsFullAfterPuts() throws InterruptedException {
BoundedBuffer<Integer> bb = new BoundedBuffer<Integer>(10);
for (int i = 0; i < 10; i++)
bb.put(i);
assertTrue(bb.isFull());
assertFalse(bb.isEmpty());
}
}
public void testTakeBlocksWhenEmpty() {
final BoundedBuffer<Integer> bb = new BoundedBuffer<Integer>(10);
Thread taker = new Thread() {
public void run() {
try {
int unused = bb.take();
fail(); // 如果运行到这里,就说明有错误,fail会抛出异常
} catch (InterruptedException success) { }
}};
try {
taker.start();
Thread.sleep(1);
taker.interrupt();//中断阻塞线程
taker.join(10);//等待阻塞线程完成
assertFalse(taker.isAlive());//断言阻塞线程已终止
} catch (Exception unexpected) {
fail();
}
}
public class PutTakeTest extends TestCase {
protected static final ExecutorService pool = Executors
.newCachedThreadPool();
protected CyclicBarrier barrier;//为了尽量做到真正并发,使用屏障
protected final BoundedBuffer<Integer> bb;
protected final int nTrials, nPairs;//元素个数、生产与消费线程数
protected final AtomicInteger putSum = new AtomicInteger(0);//放入元素检验和
protected final AtomicInteger takeSum = new AtomicInteger(0);//取出元素检验和
public static void main(String[] args) throws Exception {
new PutTakeTest(10, 10, 100000).test(); // sample parameters
pool.shutdown();
}
public PutTakeTest(int capacity, int npairs, int ntrials) {
this.bb = new BoundedBuffer<Integer>(capacity);
this.nTrials = ntrials;
this.nPairs = npairs;
this.barrier = new CyclicBarrier(npairs * 2 + 1);
}
void test() {
try {
for (int i = 0; i < nPairs; i++) {
pool.execute(new Producer());//提交生产任务
pool.execute(new Consumer());//提交消费任务
}
barrier.await(); // 等待所有线程都准备好
barrier.await(); // 等待所有线程完成,即所有线程都执行到这里时才能往下执行
assertEquals(putSum.get(), takeSum.get());//如果不等,则会抛异常
} catch (Exception e) {
throw new RuntimeException(e);
}
}
class Producer implements Runnable {
public void run() {
try {
//等待所有生产-消费线程、还有主线程都准备好后才可以往后执行
barrier.await();
// 种子,即起始值
int seed = (this.hashCode() ^ (int) System.nanoTime());
int sum = 0;//线程内部检验和
for (int i = nTrials; i > 0; --i) {
bb.put(seed);//入队
/*
* 累计放入检验和,为了不影响原程序,这里不要直接使用全局的
* putSum来累计,而是等每个线程试验完后再将内部统计的结果一
* 次性存入
*/
sum += seed;
seed = xorShift(seed);//根据种子随机产生下一个将要放入的元素
}
//试验完成后将每个线程的内部检验和再次累计到全局检验和
putSum.getAndAdd(sum);
//等待所有生产-消费线程、还有主线程都完成后才可以往后执行
barrier.await();
} catch (Exception e) {
throw new RuntimeException(e);
}
}
}
class Consumer implements Runnable {
public void run() {
try {
//等待所有生产-消费线程、还有主线程都准备好后才可以往后执行
barrier.await();
int sum = 0;
for (int i = nTrials; i > 0; --i) {
sum += bb.take();
}
takeSum.getAndAdd(sum);
//等待所有生产-消费线程、还有主线程都完成后才可以往后执行
barrier.await();
} catch (Exception e) {
throw new RuntimeException(e);
}
}
}
/*
* 测试时尽量不是使用类库中的随机函数,大多数的随机数生成器都是线程安全的,
* 使用它们可能会影响原本的性能测试。在这里我们也不必要使用高先是的随机性。
* 所以使用简单而快的随机算法在这里是必要的。
*/
static int xorShift(int y) {
y ^= (y << 6);
y ^= (y >>> 21);
y ^= (y << 7);
return y;
}
}
//大对象
class Big { double[] data = new double[100000]; }
void testLeak() throws InterruptedException {
BoundedBuffer<Big> bb = new BoundedBuffer<Big>(CAPACITY);
//使用前堆大小快照,这里可以调用第三方堆追踪(heap-profiling)工具来记录。堆追踪工具会强制进行垃圾回收,然后记录下堆大小和内存用量信息
int heapSize1 = /* snapshot heap */ ;
for (int i = 0; i < CAPACITY; i++)
bb.put(new Big());
for (int i = 0; i < CAPACITY; i++)
bb.take();
int heapSize2 = /* snapshot heap */ ;
assertTrue(Math.abs(heapSize1-heapSize2) < THRESHOLD);
}
使用回调扩展Executor框架。测试一个线程池,涉及到对其执行策略斩大量要素的代码(当需要时就创建额外的线程,不需要时就不创建;当需要时就回收空闲线程)。回调用户提供的代码,有助于创建测试用例。
class TestingThreadFactory implements ThreadFactory {
public final AtomicInteger numCreated = new AtomicInteger();//记录已创建的工作线程数
private final ThreadFactory factory
= Executors.defaultThreadFactory();
public Thread newThread(Runnable r) {//Executor框架在创建工作线程时回调此方法
numCreated.incrementAndGet();
return factory.newThread(r);
}
}
我们还可以扩展这个例子,让它返回一个可以记录自身何时终结的自定义Thread(重写Object的终结方法?),这样测试用例还可以验证线程是否遵守了执行策略,在适当的时候被回收。
使用Thread.yield,让线程从Thread.yield调用点切换到另一线程,有助于发现Bug,该方法只适合用于测试环境中。下面使用该方法在取出与存入间切换到另一线程:
public synchronized void transferCredits(Account from,
Account to,
int amount) {
from.setBalance(from.getBalance() - amount);
if (random.nextInt(1000) > THRESHOLD)
Thread.yield();//切换到另一线程
to.setBalance(to.getBalance() + amount);
}
扩展上面的PutTakeTest,给它加上时间测量特性。测试性能时的时间最好取多个线程的平均消耗时间,这样会精确一些。在PutTakeTest中我们已经使用了CyclicBarrier去同时启动和结束工作者线程了,所以我们只要使用一个关卡动作(在所有线程都达关卡点后开始执行的动作)来记录启动和结束时间,就完成了对该测试的扩展。下面是扩展后的PutTakeTest:
public class TimedPutTakeTest extends PutTakeTest {
private BarrierTimer timer = new BarrierTimer();
public TimedPutTakeTest(int cap, int pairs, int trials) {
super(cap, pairs, trials);
barrier = new CyclicBarrier(nPairs * 2 + 1, timer);
}
public void test() {
try {
timer.clear();
for (int i = 0; i < nPairs; i++) {
pool.execute(new PutTakeTest.Producer());
pool.execute(new PutTakeTest.Consumer());
}
barrier.await();//等待所有线程都准备好后开始往下执行
barrier.await();//等待所有线都执行完后开始往下执行
//每个元素完成处理所需要的时间
long nsPerItem = timer.getTime() / (nPairs * (long) nTrials);
System.out.print("Throughput: " + nsPerItem + " ns/item");
assertEquals(putSum.get(), takeSum.get());
} catch (Exception e) {
throw new RuntimeException(e);
}
}
public static void main(String[] args) throws Exception {
int tpt = 100000; // 每对线程(生产-消费)需处理的元素个数
//测试缓存容量分别为1、10、100、1000的情况
for (int cap = 1; cap <= 1000; cap *= 10) {
System.out.println("Capacity: " + cap);
//测试工作线程数1、2、4、8、16、32、64、128的情况
for (int pairs = 1; pairs <= 128; pairs *= 2) {
TimedPutTakeTest t = new TimedPutTakeTest(cap, pairs, tpt);
System.out.print("Pairs: " + pairs + "\t");
//测试两次
t.test();//第一次
System.out.print("\t");
Thread.sleep(1000);
t.test();//第二次
System.out.println();
Thread.sleep(1000);
}
}
PutTakeTest.pool.shutdown();
}
//关卡动作,在最后一个线程达到后执行。在该测试中会执行两次:
//一次是执行任务前,二是所有任务都执行完后
static class BarrierTimer implements Runnable {
private boolean started;//是否是第一次执行关卡活动
private long startTime, endTime;
public synchronized void run() {
long t = System.nanoTime();
if (!started) {//第一次关卡活动走该分支
started = true;
startTime = t;
} else
//第二次关卡活动走该分支
endTime = t;
}
public synchronized void clear() {
started = false;
}
public synchronized long getTime() {//任务所耗时间
return endTime - startTime;
}
}
}/*
Capacity: 1
Pairs: 1 Throughput: 7135 ns/item Throughput: 7090 ns/item
Pairs: 2 Throughput: 7127 ns/item Throughput: 7186 ns/item
Pairs: 4 Throughput: 7206 ns/item Throughput: 7193 ns/item
Pairs: 8 Throughput: 7204 ns/item Throughput: 7193 ns/item
Pairs: 16 Throughput: 7222 ns/item Throughput: 7183 ns/item
Pairs: 32 Throughput: 7290 ns/item Throughput: 7259 ns/item
Pairs: 64 Throughput: 7341 ns/item Throughput: 7550 ns/item
Pairs: 128 Throughput: 9574 ns/item Throughput: 9522 ns/item
Capacity: 10
Pairs: 1 Throughput: 783 ns/item Throughput: 767 ns/item
Pairs: 2 Throughput: 757 ns/item Throughput: 797 ns/item
Pairs: 4 Throughput: 769 ns/item Throughput: 789 ns/item
Pairs: 8 Throughput: 785 ns/item Throughput: 812 ns/item
Pairs: 16 Throughput: 799 ns/item Throughput: 819 ns/item
Pairs: 32 Throughput: 845 ns/item Throughput: 843 ns/item
Pairs: 64 Throughput: 833 ns/item Throughput: 836 ns/item
Pairs: 128 Throughput: 939 ns/item Throughput: 966 ns/item
Capacity: 100
Pairs: 1 Throughput: 753 ns/item Throughput: 743 ns/item
Pairs: 2 Throughput: 743 ns/item Throughput: 737 ns/item
Pairs: 4 Throughput: 742 ns/item Throughput: 735 ns/item
Pairs: 8 Throughput: 738 ns/item Throughput: 723 ns/item
Pairs: 16 Throughput: 735 ns/item Throughput: 732 ns/item
Pairs: 32 Throughput: 731 ns/item Throughput: 729 ns/item
Pairs: 64 Throughput: 753 ns/item Throughput: 755 ns/item
Pairs: 128 Throughput: 735 ns/item Throughput: 738 ns/item
Capacity: 1000
Pairs: 1 Throughput: 735 ns/item Throughput: 725 ns/item
Pairs: 2 Throughput: 749 ns/item Throughput: 714 ns/item
Pairs: 4 Throughput: 743 ns/item Throughput: 747 ns/item
Pairs: 8 Throughput: 746 ns/item Throughput: 753 ns/item
Pairs: 16 Throughput: 751 ns/item Throughput: 754 ns/item
Pairs: 32 Throughput: 754 ns/item Throughput: 740 ns/item
Pairs: 64 Throughput: 752 ns/item Throughput: 755 ns/item
Pairs: 128 Throughput: 747 ns/item Throughput: 750 ns/item
*/
不同容量缓存下TimedPutTakeTest运行效果:
虽然上面的BoundedBuffer是一种相当可靠的实现,它的运行机制也非常合理,但是它还不足以和ArrayBlockingQueue 与LinkedBlockingQueue相提并论,这也解释了为什么这种缓存算法没有被选入类库中。并发类库中的算法已经被选择并调整到最佳性能状态了。BoundedBuffer性能不高的主要原因:put和take操作分别都有多个操作可能遇到竞争——获取一个信号量,获取一个锁、释放信号量。
在测试的过程中发现LinkedBlockingQueue的伸缩性好于ArrayBlockingQueue,这主要是因为链接队列的put和take操作允许有比基于数组的队列更好的并发访问,好的链接队列算法允许队列的头和尾彼此独立地更新。LinkedBlockingQueue中好的并发算法抵消了创建节点元素的开销,这似乎与传统性能调优相违背。
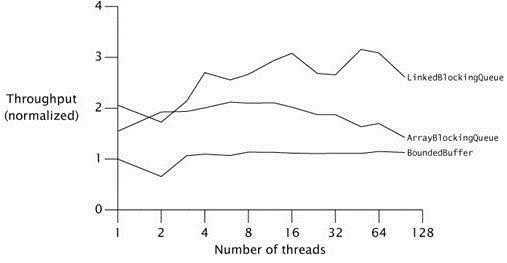
在1.5前,用于调节共享对象访问的机制只有synchronized与volatile。在1.5中,提供了新的选择ReentrantLock。
ReentrantLock并不是作为内部锁机制的替代,而是当内部锁被证明受到局限时,提供可选择的高级特性。
与内部加锁机制不同,Lock提供了无条件的、可轮询的、定时的、可中断的锁操作,所有加锁和解锁的方法都显示的。
public interface Lock {
void lock();
void lockInterruptibly() throws InterruptedException;
boolean tryLock();
boolean tryLock(long timeout, TimeUnit unit)
throws InterruptedException;
void unlock();
Condition newCondition();
}
为什么要创建与内部锁如此相似的机制呢?内部锁在大部分情况下都能很好的工作,但是一些功能上的局限——不能中断那些正在等待获取锁的线程,并且在请求锁失败的情况睛,还必有无限等待。内部锁必须在获取它的代码块中被释放,这在一方面确实很好地简化了代码,与异常处理机制能够进行良好的互动,但是在某些情况下,一个更灵活的加锁机制提供了更好的活性与性能,因为它可以跨方法级来释放。
Lock lock = new ReentrantLock();
...
lock.lock();
try {
// update object state
// catch exceptions and restore invariants if necessary
} finally {
lock.unlock();//一定要记得在finally块里释放
}
显示锁不像内部锁那样退出块时会自动释放,因为显示锁根本就没有记录锁本应被释放的位置和时间,这就是ReentrantLock不能完全替换synchronized的原因:它更加的“危险”,因为当程序的控制权离开了守护的块时,不会自动清除。
线程在调用lock()方法来获得另一个线程所持有的锁时,会发生阻塞,你应该对这样方式获得锁更加谨慎。而tryLock方法试图获得一个锁,如果成功则返回true,否则立即返回false,并且线程可以立即离开去做其他的事情。
可定时的与立即锁,是由tryLock方法实现,与无条件的锁获取相比,它具有更完善的恢复机制。在内部锁中,死锁是致命的——唯一的恢复方法是重新启动程序,唯一的预防方法是在构建程序时不要出错。所以不可能允许不一致的锁。可定时的与可轮询的锁提供了另一个选择:可以规避死锁的发生。
立即锁—— Lock.tryLock():即使已将此锁定设置为使用公平排序策略,但是调用 tryLock() 仍将立即获取锁定(如果有可用的),而不管其他线程当前是否正在等待该锁定。在某些情况下,此“闯入”行为可能会打破公平性,如果希望遵守此锁定的公平设置,则使用 tryLock(0, TimeUnit.SECONDS) ,它几乎是等效的。
下面使用立即锁来解决动态的顺序死锁问题,如果使用内部锁机制,当传递两个参数交换位置时就会出现死锁,但下面可以很好的解决死锁这个问题:
public boolean transferMoney(Account fromAcct, Account toAcct)
throws Exception {
while (true) {
if (fromAcct.lock.tryLock()) {
try {
if (toAcct.lock.tryLock()) {
try {
fromAcct.debit(amount);//取出
toAcct.credit(amount);//存入
return true;
} finally {
toAcct.lock.unlock();
}
}
} finally {
fromAcct.lock.unlock();
}
}
if (System.nanoTime() < stopTime)
return false;
NANOSECONDS.sleep(1);
}
}
超时锁—— Lock.tryLock(long timeout, TimeUnit unit):如果该锁定没有被另一个线程保持,并且立即返回 true 值,否则等待直到获取到锁或超时或被中断为止。如果为了使用公平的排序策略,已经设置此锁定,并且其他线程都在等待该锁定,则不会获取一个可用的锁定,这与 tryLock() 方法相反。如果想使用一个允许闯入公平锁定的定时 tryLock,那么可以将定时形式和不定时形式组合在一起:
if (lock.tryLock() || lock.tryLock(timeout, unit) ) { ... }
并且如果当前线程,在进入此方法时已经设置了该线程的中断状态,或者在等待获取锁定的同时轮循检测发现中断请求时则抛出 InterruptedException,并且清除当前线程的已中断状态。如果超出了指定的等待时间,则返回值为 false。如果该时间小于或等于 0,则此方法根本不会等待。所以超时锁是一个非常有用的锁,因为它允许程序打破死锁。
中断锁 —— Lock.lockInterruptibly():该锁与lock相似,但可以被中断。它又相当于一个超时为无限的tryLocky方法。如果线程未被中断,也不能获取到锁,就会一直阻塞下去,直到获取到锁或发生中断请求。如果当前线程在进入此方法时已经设置了该线程的中断状态,或者在等待获取锁定的同时轮循检测发现中断请求时则抛出 InterruptedException
(其他两种不会抛此种异常),并且清除当前线程的已中断状态。
公平锁——在你构建一个ReentrantLock时,你可以指定你需要一个公平锁策略:
Lock fairLock = new ReentrantLock(true);
公平锁策略会优待那些等待了最长时间的线程。但是,保证公平性可能会大大影响性能。因此,在默认情况,锁也不需要是公平的。
即便你使用了公平锁,你也不能保证线程调度器是公平的。如果线程调度器选择忽略一个等待了很长时间的线程,那么该线程就没有机会得到锁的公平对待。虽然公平锁听起来不错,但公平锁比普通锁要慢很多。因此,只有理由充分的情况下,才使用公平锁。
在1.5中,ReentrantLock在竞争上的性能要远远优于内部锁,但在1.6中改善了内部锁的算法,类似于ReentrantLock使用的算法,从而大大弥补了不可伸缩性的不足。
在1.5中,内部锁的性能在从单线程(无竞争)到多线程的变化过程中,性能急剧下降;ReentrantLock的性能下降要小得多,显示出了更好的可伸缩性。但是在1.6中就完全不同了——内部锁不再因竞争导致“崩溃”,两者的伸缩比例基本相等。
总之,ReentrantLock的性能看起来用过内部锁,1.6中略微用过,而1.5大大超过,那为什么不放弃使用synchronized,而使用新的并发ReentrantLock呢?内部锁相比于显式锁仍然具有很大的优势。这个标示更为人们所熟悉,也更简洁,而且很多现有的程序已经在使用内部锁了。而且ReentrantLock是最危险的同步工具;如果你忘记在finally块中调用unlock,将造成安全隐患。
只有在内部锁不能满足使用时,ReentrantLock才被作为更高级的工具。当你需要以下高级特性时,才应该使用:可定时的、可轮询的(可立即返回的)与可中断的锁,公平队列,或者是非块结构的锁。否则,请使用synchronized。
内置锁的另一个优点就是:线程转储支持得很好,1.5中ReentrantLock还不支持,但在1.6中ReentrantLock也得到了解决,它提供了一个管理和调试接口,锁可能使用这个接口进行注册,并通过其他管理和调试接口,从线程转储中得到ReentrantLock的加锁信息。
JVM使用线程转储可以帮助你识别死锁的发生。线程转储包括每个运行中线程的栈追踪信息,以及与之相关发生的异常。线程转储也包括锁的信息,比如,哪个锁由哪个线程获得,其中获得这些锁的栈结构,以及阻塞线程正在等待的锁究竟是哪一个(即使你没有遇到死锁,这些信息在调试中也是有用处的;周期性的触发线程转储可以让你观察到程序加锁的行为)。在生成线程转储之前,JVM在“正在等待(is-waiting-for)”关系(有向)图中搜索循环来寻找死锁,如果发现了死锁,它就会包括死锁的识别信息,其中哪些线程参了这个锁,以及死锁发生的位置。
在Unix平台,你可以通过向JVM的进程发送SIGQUIT信号(kill -3)来触发线程转储,或者是在Unix平台下Ctrl - \ 键,在Windows平台下按 Ctrl – Break 键。下面是在某次死锁时线程转储结果:
...
Found one Java-level deadlock:
=============================
"Thread-1":
waiting to lock monitor 0x00a8710c (object 0x22b0f4b8, a java.lang.Object),
which is held by "Thread-0"
"Thread-0":
waiting to lock monitor 0x00a870ec (object 0x22b0f4c0, a java.lang.Object),
which is held by "Thread-1"
Java stack information for the threads listed above:
===================================================
"Thread-1":
at test.TestDeathLock.deathLock(TestDeathLock.java:9)
- waiting to lock <0x22b0f4b8> (a java.lang.Object)
- locked <0x22b0f4c0> (a java.lang.Object)
at test.TestDeathLock$2.run(TestDeathLock.java:29)
"Thread-0":
at test.TestDeathLock.deathLock(TestDeathLock.java:9)
- waiting to lock <0x22b0f4c0> (a java.lang.Object)
- locked <0x22b0f4b8> (a java.lang.Object)
at test.TestDeathLock$1.run(TestDeathLock.java:22)
Found 1 deadlock.
未来的性能改进可能更倾向于synchronized而不是ReentrantLock,因为synchronized是内置于JVM的,它能够进行优化。因此就性能的原因选择ReentrantLock而不是synchronized,这是不正确的决定。
ReentrantLock实现了标准的互斥锁(它好比是独占锁):一次最多只有一个线程能够持有相同ReentrantLock。互斥锁避免了“写/写”和“写/读”的重叠,但是同样也避开了“读/读”的重叠,但实质上“读/读”在绝大多数情况下是允许的。
读-写锁允许的情况:一个资源能够被多个读者访问,或者一个写者访问,但两者不能同时进行。
读-写锁的设计是用来进行性能改进的,使得特定情况下能够有更好的并发性。在实践中,当有很多线程都从某个数据结构中读取数据而很少有线程对其进行修改时,ReentrantReadWriteLock能够提高并发性能;在其他情况下运行的情况比独占锁要稍差一些,这归因于它更大的复杂性。
Lock readLock():得到一个可被多个读操作共用的读锁,但它会排斥所有写操作。
Lock writeLock():得到一个写锁,它会排斥所有其他的读操作和写操作。
在使用某些种类的 Collection 时,可以使用 ReentrantReadWriteLock 来提高并发性。当读取者线程访问它的次数多于写入者线程时很值得一试,现实中,ConcurrentHashMap的性能已经足够好了,所以你可以使用它,而不必使用这个新的解决方案,只有你需要的是别的Map时,那么这技术是非常有用的。下面使用ReentrantReadWriteLock构建的Map,允许多个get操作并发执行:
public class ReadWriteMap<K,V> {
private Map<K,V> map;
private ReadWriteLock lock = new ReentrantReadWriteLock();
private Lock readLock = lock.readLock();
private Lock writeLock = lock.writeLock();
public ReadWriteMap(Map<K,V> map){
this.map = map;
}
public V get(K key){
readLock.lock();
try{
return map.get(key);
}
finally{
readLock.unlock();
}
}
public void put(K key,V value){
writeLock.lock();
try{
map.put(key, value);
}
finally{
writeLock.unlock();
}
}
}
重入还允许从写入锁定降级为读取锁定,其实现方式是:先获取写入锁定,然后获取读取锁定(此时前面的写锁会自动降级为读锁),最后释放写入锁定。但是,从读取锁定升级到写入锁定是不可能的,因为容易引起死锁。
下面的代码展示了如何利用重入来执行升级缓存后的锁定降级(为简单起见,省略了异常处理):class CachedData {
Object data;
volatile boolean cacheValid;
ReentrantReadWriteLock rwl = new ReentrantReadWriteLock();
void processCachedData() {
/*
* 获取读锁,或以允许多个线程进入(读区间)。这里是为了同步访问 cacheValid共
* 享数据,如果已产生写锁(即已有线程进入到写区间后)则阻塞
*/
rwl.readLock().lock();
if (!cacheValid) {// 读数据
/*
* 在获取写锁前一定要先解锁,并且所有已获取该读锁的所有线程都需释放后,
* 才能获取写锁
*/
rwl.readLock().unlock();
// 获取写锁,在这之前读区间上的所有线程需释放所有的读锁
rwl.writeLock().lock();
if (!cacheValid) { // recheck
data = ...//写数据
cacheValid = true;// 写数据
}
// 准备进入读区间,现在写锁开始降级为读锁,所以才能在没有释放写锁时获
// 取读锁,这里不能将下面两行位置交换,因为如果这样则不能保证读原子性了
rwl.readLock().lock(); // 因为写锁降级,在获取读锁前不需要先释放写锁
rwl.writeLock().unlock(); // 释放写锁,但读锁仍然还在
}
use(data);//使用数据
rwl.readLock().unlock();// 使用完后释放读锁
}
}
写锁降级多用在对一片数据操作时,前部分需要写,而后部分只需要读,但读操作以需要与前部分数据保持一致与同步,所以此时就需要用来锁降级,就像上面那样。
下面是一个经典的基于队列的循环缓存,后面会有几个版本都是从它继承而来的。该版本没有对放入元素与取出元素进行任务约束,比如队满后不能再放入,队空后不能再取出。
//未加任何约束的缓冲队列
public abstract class BaseBoundedBuffer<V> {
private final V[] buf;//缓存
private int tail;//队尾
private int head;//队首
private int count;//元素个数
protected BaseBoundedBuffer(int capacity) {
this.buf = (V[]) new Object[capacity];
}
protected synchronized final void doPut(V v) {//入队
buf[tail] = v;//在队尾添加
if (++tail == buf.length)//如果满了,从头开始
tail = 0;
++count;
}
protected synchronized final V doTake() {//出队
V v = buf[head];//从队首取出
buf[head] = null;//GC
if (++head == buf.length)//如果到尾了,则从头开始
head = 0;
--count;
return v;
}
public synchronized final boolean isFull() {//队列是否满
return count == buf.length;
}
public synchronized final boolean isEmpty() {//队列是否空
return count == 0;
}
}
@ThreadSafe
public class GrumpyBoundedBuffer<V> extends BaseBoundedBuffer<V> {
public GrumpyBoundedBuffer(int size) { super(size); }
public synchronized void put(V v) throws BufferFullException {
if (isFull())//如果队列满后再次添加则向调用者抛出异常
throw new BufferFullException();
doPut(v);
}
public synchronized V take() throws BufferEmptyException {
if (isEmpty())//如果队列空后再次取出时则向调用者抛出异常
throw new BufferEmptyException();
return doTake();
}
}
尽管这种方法实现起来足够简单,但用起来却令人厌烦。异常应该用于异常条件中,与其把缓存满称作是有限缓存的一个异常条件,还不如把红灯称作是交通灯的异常条件。如果外界使用,则需要如下做:
while (true) {//不停地轮询,会造成忙等
try {
V item = buffer.take();
// use item
break;
} catch (BufferEmptyException e) {
Thread.sleep(SLEEP_GRANULARITY);//可能会睡过头
}
}
@ThreadSafe
public class SleepyBoundedBuffer<V> extends BaseBoundedBuffer<V> {
public SleepyBoundedBuffer(int size) { super(size); }
public void put(V v) throws InterruptedException {
while (true) {
synchronized (this) {
if (!isFull()) {
doPut(v);
return;
}
}
Thread.sleep(SLEEP_GRANULARITY);
}
}
public V take() throws InterruptedException {
while (true) {
synchronized (this) {
if (!isEmpty())
return doTake();
}
Thread.sleep(SLEEP_GRANULARITY);
}
}
}
这个封装了对约束条件的检查,简化了缓存的使用——这向正确的方向上迈出了一步。这个版本还是有延时的问题。如果选择休眠的时间间隔短,响应性越好,但是CPU的消耗也越高。
条件队列可以让一线程,以某种方式等待相关条件变成真。不同于传统的队列,它们的元素是数据项,而条件队列的元素是等待相关条件的线程。
就像每个Java对象都能当作锁一样,每个对象也能当作条件队列,Object中的wait、notify、notifyAll方法构成了内部条件队列的API。一个对象的内部锁与它的内部条件队列是相关的:为了能够调用对象X中的任一个条件队列方法,你必须持有对象X的锁。
Object.wait会自动释放锁,并请求OS挂起当前线程,让其他线程获得该锁进而修改对象的状态。当它被唤醒时,它会在返回要求重新获得锁。
调用notify的结果是:JVM会从在这个条件队列中等待的众多线程中挑选一个,并把它唤醒;而调用notifyAll会唤醒所有正在这个条件队列中等待的线程。由于你调用notify和notifyAll时必须持有条件队列对象的锁,这导致等待线程此时不能重新获得锁,无法从wait返回,因此该通知线程应该尽快释放锁,以确保等待线程尽可能快地解除阻塞。
@ThreadSafe
public class BoundedBuffer<V> extends BaseBoundedBuffer<V> {
public BoundedBuffer(int size) { super(size); }
// BLOCKS-UNTIL: not-full
public synchronized void put(V v) throws InterruptedException {
while (isFull())//如果满,则等待
wait();
doPut(v);
notifyAll();//并在放入后马上通知其他线程
}
// BLOCKS-UNTIL: not-empty
public synchronized V take() throws InterruptedException {
while (isEmpty())//如果为空,则等待
wait();
V v = doTake();
notifyAll();
return v;
}
}
用于生产环境的版本还应该包括的put和take版本,这样如果阻塞操作不能丰预计时间内完成,则超时。版本的put和take可以通过Object.wait的限时版本来实现,这很简单。
前面章节TestHarness中的“开始阀门闭锁”的构建,是通过将计数器初始化为1,创建了一个二元闭锁:它只有两种状态,初始状态和终止状态。闭锁会阻止线程通过开始阀门,直到阀门被打开,此时所有的线程都可以通过。虽然闭锁机制通常都能够准确地满足我们的需要,但是在闭锁的行为下构建的“阀门”一旦被打开,就不能再重新关闭,有时这会成为一个缺陷。
//可打开可关闭的阀门
public class ThreadGate {
private boolean isOpen;
private int generation;
public synchronized void close() {
isOpen = false;
}
public synchronized void open() {
++generation;
isOpen = true;
notifyAll();
}
public synchronized void await() throws InterruptedException {
/*
* 在检测等待条件前先将generation记录下来,以便在唤醒并获取锁后再次
* 检测条件isOpen不满足时(即关闭),被阻塞的线程还是能继续通过。因为
* 如果没有定义generation变量,当调用都打开阀门后又立即关闭,这会导致
* 唤醒过来的线程不能正常通过阀门,所以确保只要是阻塞在该阀门上的所有线
* 程在获得打开后的通知时就一定能通过,不会再被阻塞
*/
int arrivalGeneration = generation;
while (!isOpen && arrivalGeneration == generation)
wait();
}
}
一个Condition对象是与一个Lock对象相关联的,就像等待队列与单独的内部锁相关联一样,可以通过Lock的newCondition方法来得到一个Condition,以下是接口:
public interface Condition {
void await() throws InterruptedException;
boolean await(long time, TimeUnit unit)
throws InterruptedException;
long awaitNanos(long nanosTimeout) throws InterruptedException;
void awaitUninterruptibly();
boolean awaitUntil(Date deadline) throws InterruptedException;
void signal();
void signalAll();
}
long awaitNanos(long nanosTimeout):参数nanosTimeout为最长等待时间,单位为纳秒;如果超时,则返回一个小于或等于 0 的值,否则返回此方法返回时所剩余时间的估计值,该值绝对小于 nanosTimeout 参数,可以用此值来确定在等待返回但等待条件再次被打破的情况下,再次等待的时间,总共等待的时间绝对不超过nanosTimeout(如果条件再次被打破时再等待nanosTimeout,则不需要使用此方法,直接使用await即可)。此方法的典型用法采用以下形式:
synchronized boolean aMethod(long timeout, TimeUnit unit) {
long nanosTimeout = unit.toNanos(timeout);//转换成纳秒
while (!conditionBeingWaitedFor) {
if (nanosTimeout > 0)
nanosTimeout = theCondition.awaitNanos(nanosTimeout);//每次等待的时间逐渐减少,这与使用wait或await超时版是不一样的
else//此种情况属于超时时间用完且等待的条件还不满足时,会直接返回调用者
return false;
}
// ...
}
免中断等待:如果等待的线程被中断,condition.await方法将抛出一个InterruptedException异常。如果你希望在出现这种情况时线程能够继续等待(等待条件满足。似乎不太合理),那么可以使用condition.awaitUninterruptibly方法来代替await。
使用Condition重写前面的循环队列BaseBoundedBuffer:
public class ConditionBoundedBuffer<T> {
protected final Lock lock = new ReentrantLock();
private final Condition notFull = lock.newCondition();//条件:count < items.length
private final Condition notEmpty = lock.newCondition();//条件:count > 0
private final T[] items = (T[]) new Object[100];
private int tail, head, count;
public void put(T x) throws InterruptedException {
lock.lock();
try {
while (count == items.length)
notFull.await();//等到条件count < items.length满足
items[tail] = x;
if (++tail == items.length)
tail = 0;
++count;
notEmpty.signal();//通知读取等待线程
} finally {
lock.unlock();
}
}
public T take() throws InterruptedException {
lock.lock();
try {
while (count == 0)
notEmpty.await();//等到条件count > 0满足
T x = items[head];
items[head] = null;
if (++head == items.length)
head = 0;
--count;
notFull.signal();//通知写入等待线程
return x;
} finally {
lock.unlock();
}
}
}
ConditionBoundedBuffer的行为和BaseBoundedBuffer是相同的,通过把两个条件分离到两个等待集中,Condition简化了使用单一通知的条件,使用更有效的signal,而不是signalAll,这会减少相当数量的上下文切换。
ReentrantLock 和 Semaphore这两个类有很多共同点,它们都扮演了“阀门”的角色,每次只允许有限数目的线程通过它。线程到达阀门后,可以允许通过(lock或acquire成功返回),可以等待(lock或acquire阻塞),也可以被取消(tryLock或tryAcquire返回false、超时版tryLock或tryAcquire),它们也都允许可中断、不可中断、限时的请求,也都可以构造成公平还是非公平性的锁。从这些共同点看,你或许认为Semaphore是基于ReentrantLock来实现的,或者是ReentrantLock只是一个只有一个许可的Semaphore,这是完全可以的,下面就是使用lock实现一个计数信号量:
public class SemaphoreOnLock {//基于Lock的Semaphore实现
private final Lock lock = new ReentrantLock();
//条件:permits > 0
private final Condition permitsAvailable = lock.newCondition();
private int permits;//许可数
SemaphoreOnLock(int initialPermits) {
lock.lock();
try {
permits = initialPermits;
} finally {
lock.unlock();
}
}
//颁发许可,条件是:permits > 0
public void acquire() throws InterruptedException {
lock.lock();
try {
while (permits <= 0)//如果没有许可,则等待
permitsAvailable.await();
--permits;//用一个少一个
} finally {
lock.unlock();
}
}
//归还许可
public void release() {
lock.lock();
try {
++permits;
permitsAvailable.signal();
} finally {
lock.unlock();
}
}
}
当然也可以使用计数许可来实现一个Lock:
public class LockOnSemaphore {//基于Semaphore的Lock实现
//具有一个信号量的Semaphore就相当于Lock
private final Semaphore s = new Semaphore(1);
//获取锁
public void lock() throws InterruptedException {
s.acquire();
}
//释放锁
public void unLock() {
s.release();
}
}
事实上,与很多的Synchronizer一样,它们都是基于实现了同一基类的AbstractQueuedSynchronizer的类来实现的。AQS是一个用来构建Lock和Synchronizer的抽象类,使用它能够简单且高效地构造出应用广泛的大量的Synchronizer。不仅Lock和Synchronizer是构建在AQS上的,其他的还有CountDownLatch、ReentrantReadWriteLock、SynchronousQueue与FutureTask。
AQS解决了实现一个Synchronizer的大量实现,比如等待线程的FIFO队列。单独的Synchronizer可以定义一个灵活的标准,用来描述线程是否应该允许通过还是需要等待。
用AQS构建Synchronizer会有很多的好处。不仅仅是它能极大地减少实现过程中消耗的精力,而且你再了没必像没有使用AQS构建Synchronizer时那样,去对付多个竞争点了。在SemaphoreOnLock中,请求许可的操作在两个地方可能会阻塞:一是信号量的状态需要被锁保护,另外是当许可不可用时。使用AQS构建的Synchronizer只可能在一个点发生阻塞,这样降低了上下文切换的开销,并提高了吞量。AQS的设计充分考虑了可伸缩性, java.util.concurrentk中的所有构建于AQS之上的synchronizers都获得了收益。
状态信息可以通过protected类型的getState、setState和compareAndSetState等方法进行操作。这些可以用来表现出任何状态,例如,ReentrantLock用它来表现拥有它的线程已经请求了多少次锁,Semaphore用它来表现剩余的许可数,FutureTask用它来表现任务的状态(尚未开始、运行、完成和取消)。Synchronizer也可以自己管理一些额外的状态变量,例如,ReentrantLock保存了当前锁的所有者的追踪信息,这样它就能区分出是重进入的还是竞争的条件锁。
AQS中的获取操作可以是独占的,就像ReentrantLock一样,也可能是非独占的,就像Semaphore和CountDownLatch一样,这取决于不同的synchronizers。
一个获取操作分为两步,第一步,Synchronizer需判断当前状态是否允许被获取,如果是,就让线程执行,如果不是,获取操作阻塞或失败。这个判断是由Synchronizer的语义来决定的。举例来说,如果想成功地获取锁,锁必须是未被占有的,而如果想成功地获取闭锁,闭锁必须未处于终止状态。第二步包括了可能需要更新的状态,一个已获取获取Synchronizer的线程会影响到其他线程是否能够获取它。例如,获取锁的操作将锁的状态从“未被占有”改为“已被占有”;从Semaphore中获取许可的操作会减少剩余许可的数量。另一方面,一个线程对闭锁的请求操作不会影响到其他线程是否能够获取它,所以获取闭锁的操作不会改变闭锁的状态。
支持独占获取的Synchronizer应该实现tryAcquire、tryRelease和isHeldExclusively这向个protected方法,而支持共享获取的Synchronizer应该实现tryAcquireShared 和tryReleaseShared。AQS中的acquire、acquireShared、 release和 releaseShared这些方法,会去调用Synchronizer子类中的try-版本(tryAcquire、tryRelease、tryAcquireShared、tryReleaseShared,也就是需我们重写的这些保护方法),以此决定是否执行该操作。Synchronizer的子类会根据tryAcquire、tryRelease、tryAcquireShared、tryReleaseShared的语义,调用getState、setState和compareAndSetState来检查并更新状态从而来实现这些方法,然后基类AQS可以通过返回的状态值来得知这次“尝试获取”或“尝试释放”是否成功。举例来说,从tryAcquireShared返回一个负值,说明获取操作失败,返回0说明Synchronizer是被独占获取的,返回正值说明Synchronizer是被非独占获取的。对于tryRelease和tryReleaseShared方法来说,如果能够释放或解除一些正在阻塞尝试获取Synchronizer的线程,那么这两个方法将返回true。
protected boolean tryAcquire(int arg):试图以独占模式获取对象状态。此方法应该检查是否允许它在独占模式下获取对象状态,如果允许,则获取它。此方法由执行 acquire 的线程来调用,如果此方法返回false,则 acquire 方法将线程加入队列(如果还没有将它加入队列),直到获得其他某个线程释放了该线程的信号。如果不支持独占模式则抛出UnsupportedOperationException。参数arg该值总是传递给 acquire 方法的那个值。
tryAcquireShared基本上与tryAcquire一样,只不过是共享模式获取对象状态。
protected boolean isHeldExclusively():如果对于当前(正调用的)线程,同步是以独占方式进行的,则返回 true。此方法通过AbstractQueuedSynchronizer.ConditionObject 中非阻塞方法来调用的。默认实现将抛出 UnsupportedOperationException。此方法只是 AbstractQueuedSynchronizer.ConditionObject 方法内进行内部调用,因此,如果不使用条件,则不需要定义它。
以下是一个非再进入的互斥锁定类,它使用值 0 表示未锁定状态,使用 1 表示锁定状态。它还支持一些条件并公开了一个检测方法:
class Mutex implements Lock, java.io.Serializable {
// Our internal helper class
private static class Sync extends AbstractQueuedSynchronizer {
// Report whether in locked state
protected boolean isHeldExclusively() {
return getState() == 1;
}
// Acquire the lock if state is zero
public boolean tryAcquire(int acquires) {
assert acquires == 1; // Otherwise unused
return compareAndSetState(0, 1);
}
// Release the lock by setting state to zero
protected boolean tryRelease(int releases) {
assert releases == 1; // Otherwise unused
if (getState() == 0) throw new IllegalMonitorStateException();
setState(0);
return true;
}
// Provide a Condition
Condition newCondition() { return new ConditionObject(); }
// Deserialize properly
private void readObject(ObjectInputStream s) throws IOException, ClassNotFoundException {
s.defaultReadObject();
setState(0); // reset to unlocked state
}
}
// The sync object does all the hard work. We just forward to it.
private final Sync sync = new Sync();
public void lock() { sync.acquire(1); }
public boolean tryLock() { return sync.tryAcquire(1); }
public void unlock() { sync.release(1); }
public Condition newCondition() { return sync.newCondition(); }
public boolean isLocked() { return sync.isHeldExclusively(); }
public boolean hasQueuedThreads() { return sync.hasQueuedThreads(); }
public void lockInterruptibly() throws InterruptedException {
sync.acquireInterruptibly(1);
}
public boolean tryLock(long timeout, TimeUnit unit) throws InterruptedException {
return sync.tryAcquireNanos(1, unit.toNanos(timeout));
}
}
public class OneShotLatch {
private final Sync sync = new Sync();
public void signal() {//释放锁
sync.releaseShared(0);
}
public void await() throws InterruptedException {//获取锁
sync.acquireSharedInterruptibly(0);
}
private class Sync extends AbstractQueuedSynchronizer {
protected int tryAcquireShared(int ignored) {
// 如果 state == 1 则表示闭锁成功打开,否则将调用失败的线程放入阻塞队列中
return (getState() == 1) ? 1 : -1;
}
protected boolean tryReleaseShared(int ignored) {
setState(1); // 闭锁现已被打开
return true; // 现在,其他线程可以获得闭锁
}
}
}
上面闭锁初始状态是关闭的,刚开始时任何调用await的线程都会阻塞,直到signal被调用。一旦闭锁被一个signal调用打开,待选中的线程就会被释放,而且随后到来的线程也被允许通行。
在OneShotLatch中,AQS类管理着闭锁的状态:关闭(0)或打开(1)。await方法调用AQS的acquireSharedInterruptibly,它又调用OneShotLatch中的tryAcquireShared方法,tryAcquireShared的实现必须返回一个值,表明请求操作能否进行,如果闭锁已经事先打开,tryAcquireShared会返回成功,并允许线程通过;否则它会返回一个负值,表明请求尝试失败。AQS的acquireSharedInterruptibly方法将处理失败的线程(tryAcquireShared返回为负值的线程)放入一个队列中,该队列中的元素都是等待中的线程。类似地,signal会调用releaseShared,进而导致tryReleaseShared被调用,这里的tryReleaseShared实现是无条件地把闭锁的状态设置为打开,其返回表明了Synchronizer完全被释放的状态。
Java.util.concurrent包中的许多类,如Semaphore 和 ConcurrentLinkedQueue,都提供了比使用synchronized更好的性能和可伸缩性,这些性能提升的原始来源是:原子变量和非阻塞的同步机制
。
非阻塞算法使用低层原子化的机器指令取代锁,比如比较并交换,从保证数据在并发访问下的一致性。
与基于锁的方案相比,非阻塞算法的设计和实现较复杂,但它们在可伸缩性和活跃度上占有很大的优势,因为非阻塞算法可以让多个线程在竞争相同资源时不会发生阻塞,所以它能在更精华的层面上调整粒度,并能大大减少调度的开销。
在1.5中,使用原子变量类,比如AtomicInteger 和 AtomicReference,能够高效地构建非阻塞算法。
尽管现在的JVM对非竞争锁的获取与进行了很大的优化,但是如果有多个线程同时请求锁,会此起锁的竞争,造成线程的频繁挂起与恢复,而挂起和恢复线程会带来很大的开销,并通常伴有冗长的中断。
volatile变量与锁相比是更轻量的同步机制,因为它们不会引起上下文的切换和线程调度。然而,volatile变量与锁相比有一些局限性:尽管它们提供了相似的可见性保证,但是它们不能用于构建原子化的复合操作,即不具有原子性。这意味着当一个变量依赖其他变量时,或者当变量的新值依赖于旧值时,是不能用volatile变量的。这些都限制了bolatile变量的使用,因此,它们不能用于实现可靠的通用工具,如计数器。
加锁还有其他的缺点,当一个线程正在等待锁时,它不能做任何其他的事,如果一个线程在持有锁的情况下发生了延迟,那么其他所有需要该锁的线程都不能前进了,就有可能造成死锁。
加锁对于细粒度的操作而言,仍然是重量级的,因为它们还是会引起少量的不必要的线程上下文切换与短暂的延时。
独占锁是一项悲观的技术——它假设最坏情况,会通过获得正确的锁来避免其他线程的打扰,直到作出保证才能继续进行。
对于细粒度的操作(即只有很少几条指令,如i++),有另外一种选择通常更加有效——乐观的解决方法。这个方法依赖于冲突监测,从而能判定更新的过程中是否存在来自于其他成员的干涉,在冲突发生的情况下,操作失败,并会重试,这会更效率,因为毕竟冲突时间还是比较少的。
早期的处理器具有原子化的“测试并设置(test-and-set)”、“获取并增加(fetch-and-increment)”以及“交换(swap)”指令,现在,几乎所有现代的处理器都具有一些形式的原子化的“读-改-写”指令,比如“比较并交换(compare-and-swap)”和“加载链接/存储条件(load-linked/store-conditional)”,操作系统和JVM使用这些指令来实现锁和并发的数据结构,但直到1.5以前这些还不能直接被Java类所使用。
包括IA32(intel 32位处理器)和Sparc(全称为“可扩充处理器架构”Scalable Processor ARChitecture,是RISC——精简指令集计算机,微处理器架构之一)在内的大多数处理器使用的架构方案都实现了“比较并交换(CAS)”指令。其他的处理器,比如PowerPC,是用一对指令实现了相同的功能:加载链接/存储条件。
CAS有3个操作数——操作的内存位置V、旧的预期值A和新值B,当且仅当V符合旧预期值A时,CAS用新值B原子化地更新V的值,否则它什么都不会做,在任何一种情况下——成功还是失败,都会返回当前V中的值(应该是旧的值)。CAS的意思是:“我认为V的值应该是A,如果是,那么将其赋值为B,若不是,则不修改,但要告诉我错了”。CAS是一项乐观技术——它抱着成功的希望进行更新,并且如果另一个线程在上次检查后更新了该变量,它也能够发现错误。SimulatedCAS阐释了CAS语义(但并非真正的实现或执行方式,注,处理器硬件的CAS也是原子性的)。
@ThreadSafe
public class SimulatedCAS {//模拟CAS操作
@GuardedBy("this") private int value;
public synchronized int get() { return value; }
public synchronized int compareAndSwap(int expectedValue,
int newValue) {//相当于处理器的CAS原子化操作
int oldValue = value;
if (oldValue == expectedValue)
value = newValue;
return oldValue;
}
public synchronized boolean compareAndSet(int expectedValue,
int newValue) {
return (expectedValue
== compareAndSwap(expectedValue, newValue));
}
}
当多个线程试图使用CAS同时更新相同的变量时,其中一个会胜出,并更新变量的值,而其他的都会失败,失败的线程不会被挂起。它们会被告知这次失败,但允许再尝试。因为一个线程在竞争CAS时失败不会被阻塞,它可以决定是否重试,或什么也不做。
使用CAS的典型模式是:首先从V中读取值A,并由A得到新的值B,然后使用CAS原子化地把V的值由A改变成B,只要这期间没有其他线程改变V的值。因为CAS能够发现来自其他线程的影响,所以即使不使用锁,它也能够解决原子化地实现读-写-改的问题。下面就来看一个例子:
@ThreadSafe
public class CasCounter {
private SimulatedCAS value;
public int getValue() {
return value.get();
}
public int increment() {
int v;
do {
v = value.get();
}
while (v != value.compareAndSwap(v, v + 1));
return v + 1;
}
}
CasCounter利用CAS实现了线程安全的计数器功能(实际中我们使用AtomicInteger就可以了)。自增操作遵循了经典形式——取得旧值,要所它计算出新值(加1),并使用CAS设定新值。如果CAS失败,也不会阻塞,立即重试该操作(理论上,如果其他民线程一直在CAS的竞争中处于优势,执行线程本应会重试任意多次,事实上,这个类型的饥饿很少发生)。
初看起来,基于CAS的计数器看起来比基于锁的计数器性能差一些:它具有更多的操作和更复杂的控制流,表面看来还依赖于复杂的CAS操作,但是,实际上(硬件中的CAS)基于CAS的计数器,性能上远远胜过了基于锁的计数器,即使在很小的竞争或没有竞争的情况下。加锁的语法可能比较简洁,但是JVM和OS管理锁的工作却并不简单。
CAS最重要的缺点是:它强迫调用者处理竞争(重试、回退、放弃)。
CAS的性能随处理器的数量变化很大。CAS的性能是一个不断改变的标准,不仅在不同的处理器的体系架构之间,就是在相同的处理器的不同版本之间也会发生改变。厂商迫于竞争的压力,在近几年还会持续提高CAS的性能。总之,即使是获取和释放无竞争锁的开销大约也是CAS的两倍。
在1.5前,若不编写本机代码,是无法做到这一点的,在1.5中,底层的CAS操作将在int、long和对象的引用上体现出来,并且JVM把它们编译为底层硬件提供的最有效的方法。在支持CAS的平台上,运行期间把它们内联成合适的机器指令;在最坏的情况下,如果CAS指令不可用,JVM会使用自旋锁。这些底层的JVM支持都已经用于那些具有原子化变量的类(AtomicXXX),从而为数字类型和引用类型提供了有效的CAS操作,而且,这些原子变量类还用于直接或间接地实现java.util.concurrent中大部分类。
原子变量比锁更精巧,更轻量,并且在多处理系统中,对实现高性能的并发代码非常关键。它不会引起线程的挂起和重新调度,在使用原子变量取代锁的算法中,线程更不易出现延迟,如果它们遇到竞争,也更容易恢复。
原子变量类,提供了广义的volatile变量,以支持原子的、条件的读-写-改操作。在竞争条件下原子变量类提供了更好的可伸缩性,因为它可以直接利用硬件对并发的支持。
原子变量类共有12个,分成4组:计量器、域更新、数组、复合变量。最常用的原子变量是计量器:AtomicInteger、 AtomicLong、 AtomicBoolean 和 AtomicReference,他们都支持CAS(对于short或byte,把它们的值强转为int,对于浮点数,使用floatToIntBits或doubleToLongBits再来操作它们)。
原子化的数组类(AtomicIntegerArray、AtomicLongArray、AtomicReferenceArray<E>),它们的元素可以像计量器那样被原子化地更新。原子数组类为数组的元素提供了volatile访问语义,这是普通数组所没有的特性——volatile类型的数组只针对数组的引用具有volatile语义,而不是它的元素。
原子类不是 java.lang.Integer 和相关类的通用替换方法。它们没有定义像 hashCode 和 compareTo 之类的方法。(因为原子变量是可变的,所以对于哈希表键来说,它们不是好的选择。)另外,仅为那些通常在应用程序中使用的类型才提供这样的原子类。例如,没有表示 byte 的原子类。这种情况不常见,如果要这样做,可以使用 AtomicInteger 来保持 byte 值,并进行适当的强制转换。也可以使用 Float.floatToIntBits 和 Float.intBitstoFloat 转换来保持 float 值,使用 Double.doubleToLongBits 和 Double.longBitsToDouble 转换来保持 double 值。
使用CAS避免多元的不变约束:
public class CasNumberRange {
private static class IntPair {
// 约束条件: lower <= upper
final int lower;
final int upper;
public IntPair(int lower, int upper) {
this.lower = lower;
this.upper = upper;
}
}
//使用AtomicReference对引用进行原子化操作
private final AtomicReference<IntPair> values =
new AtomicReference<IntPair>(new IntPair(0, 0));
public int getLower() {
return values.get().lower;
}
public int getUpper() {
return values.get().upper;
}
public void setLower(int i) {
while (true) {
IntPair oldv = values.get();//取出原来的值,即后面操作的基准点
if (i > oldv.upper)
throw new IllegalArgumentException("Can‘t set lower to " + i + " > upper");
IntPair newv = new IntPair(i, oldv.upper);
if (values.compareAndSet(oldv, newv))//如果基点没有被其他线程更改,则成功
return;
}
}
public void setUpper(int i) {
while (true) {
IntPair oldv = values.get();
if (i < oldv.lower)
throw new IllegalArgumentException("Can‘t set upper to " + i + " < lower");
IntPair newv = new IntPair(oldv.lower, i);
if (values.compareAndSet(oldv, newv))
return;
}
}
}
一个线程的失败或挂起不应该影响其他线程的失败或挂起,这样的算法被称为非阻塞算法,如果算法的每一步骤中都有一些线程能够继续执行,那么这样的算法称为锁自由算法。在线程间使用CAS进行协调,这样的算法如果构建正确的话,它既是非阻塞的,又是锁自由的。
非阻塞算法对死锁和优先级倒置有“免疫性”。到目前止,我们已经见到了一个非阻塞算法:CasCounter。好的非阻塞算法已经在多种常见的数据结构上体现了:包括栈、队列、优先级队列、哈希表。
实现同等功能前提下,非阻塞算法被认为比基于锁的算法更加复杂,创建非阻塞算法的前提是为维护数据的一致性,解决如何把原子化范围缩小到一个“唯一”变量。
栈是最简单的链式数据结构:每个元素都只知道它后面紧随的元素,而不必知道前面的元素。下面显示了如何使用原子引用来构建栈:
public class ConcurrentStack<E> {//非阻塞栈
//栈顶元素,永远指向栈顶,入栈与出栈都只能从栈顶开始
AtomicReference<Node<E>> top = new AtomicReference<Node<E>>();
//非阻塞的入栈操作
public void push(E item) {
//创建新的元素
Node<E> newHead = new Node<E>(item);
Node<E> oldHead;
do {
//当前栈顶元素,也即这次操作的基准点,操作期间不能改变
oldHead = top.get();
newHead.next = oldHead;//让新元素成为栈顶
//如果基准点被其他线程修改后就会失败,失败后再重试
} while (!top.compareAndSet(oldHead, newHead));
}
//非阻塞的出栈操作
public E pop() {
Node<E> oldHead;
Node<E> newHead;
do {
oldHead = top.get();//取栈顶元素,即基准点
if (oldHead == null)
return null;
newHead = oldHead.next;
//如果基准点没有变化,则成功
} while (!top.compareAndSet(oldHead, newHead));
return oldHead.item;//返回栈顶元素值
}
//节点元素
private static class Node<E> {
public final E item;
public Node<E> next;
public Node(E item) {
this.item = item;
}
}
}
CasCounter和ConcurrentStack阐明了非阻塞算法的所有特性:一些任务的完成具有不确定性,并可能必须重做。
在ConcurrentStack等中用到的非阻塞算法,其线程安全性源于:compareAndSet即能提供原子性,又能提供可见性保证,这与加锁的特性一样。当一个线程取栈元素时时,它通过调用同一个AtomicReference的get方法来实现,它具有与读取volatile变量相同的内存效应,所以任何线程修改都能够安全地发布给其他正在获取栈元素的线程。
到目前为止,我们已经见到了两个非阻塞算法,即计数器和栈。构建非阻塞算法的关键是:缩小原子化的范围到唯一的变量。在计数器中,这很简单,在栈中,实现这一点也非常明显,但是对于一些更复杂的数据结构,比如队列、哈希表、或者树,它可能变得不好处理了。
一个链表队列比栈更加复杂,因为它需要支持首尾(从尾插入,从首取出)的快速访问,为了实现,它会维护独立的队首指针和队尾指针。
在成功加入新的元素时,需要调节两个指针,一是队尾元素的next指针需指向新的元素,二是原来的tail指针也要指向新添加的元素,这两个动作还要求是原子性的(在这两个操作间,队列处于中间状态,在第二个操作完成后才处于稳定状态)。初看起来,这不能通过原子变量来实现,彼此分离的CAS操作需要更新两个指针,并且如果第一个成功,第二个失败,队列将处于不一致的状态。并且即使两个都成功了,另一线程也可能在两个操作之间访问队列,所以为链接队列构建非阻塞算法需要考虑到这两种情况。
技巧一:即使在多步更新中,也要确保数据结构总能处于一致状态,即要确保插入时队列处于稳定状态。这样,如果线程B到达时发现线程A在更新中,B就开始等待(通过反复检查队列是否算处于稳定状态),使用CAS算法,即使B等待也不会影响到其他线程的操作。
技巧二:确保如果B到达时发现数据结构正在被A修改,B可以以数据结构中足够的信息来帮助A来完成更新操作。如果B帮助A其操作,那么B可以进行自己的操作,而不用等待A的操作完成。当A恢复后试图完成其操作,会发现B已经替它完成了。
具有两个元素的稳定队列:
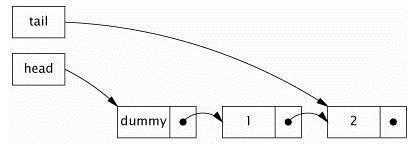
插入期间,队列处于中间状态:
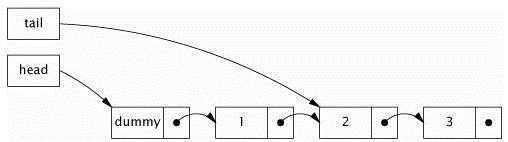
插入完成后,队列再一次回到稳定状态:
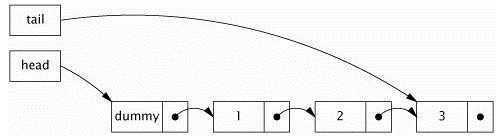
队尾指针tail可能指向哨兵节点(如果队列为空)、也可能指向最后一个节点(队列处于非空且稳定状态时)、也可能指向倒数第二个元素(队列处于插入时中间状态)。
public class LinkedQueue<E> {
private static class Node<E> {
final E item;
final AtomicReference<Node<E>> next;
public Node(E item, Node<E> next) {
this.item = item;
this.next = new AtomicReference<Node<E>>(next);
}
}
//哑元,用于区分队首与队尾,特别是在循环队列中
private final Node<E> dummy = new Node<E>(null, null);
private final AtomicReference<Node<E>> head = new AtomicReference<Node<E>>(
dummy);//头指针,出队时用
private final AtomicReference<Node<E>> tail = new AtomicReference<Node<E>>(
dummy);//尾指针,入队时用
public boolean put(E item) {//入队
Node<E> newNode = new Node<E>(item, null);
while (true) {//在除尾插入新的元素直到成功
//当前队尾元素
Node<E> curTail = tail.get();
/*
* 当前队尾元素的next域,一般为null,但有可能不为null,
* 因为有可能其他线程已经上一语句与下一语句间添加了新
* 的元素,即此时队列处于中间状态
*/
Node<E> tailNext = curTail.next.get();
/*
* 再一次检查上面两行语句的操作还是否有效,因为很有可在此刻尾指针已经
* 向后移动了(比如其他线程已经执行了B 或 D 处语句),所以下面的操作都
* 是要基于尾节点是curTail才可以。(想了一下,其实这里不需要这个判断
* 也是可以的,因为下面执行到 B 或 C 时自然会失败,这样做只是为了提高
* 成功的效率)
*/
if (curTail == tail.get()) {
if (tailNext != null) {// A
/*
* 队列处于中间状态,尝试调整队尾指针,这里
* 需要使用compareAndSet原子操作来进行,因为
* 有可以在进行时 D 处已经调整完成
*/
tail.compareAndSet(curTail, tailNext);// B
} else {
// 队列处于稳定状态,尝试在队尾插入新的节点
if (curTail.next.compareAndSet(null, newNode)) {// C
/*
* 插入尝试成功,再开始尝试调整队尾指针,这里完全
* 有可能不需要再调整了,因为上面 B 行已经帮这里调
* 整过了
*/
tail.compareAndSet(curTail, newNode);// D
return true;
}
}
}
}
}
}
上面LinkedQueue阐释了类库中的ConcurrentLinkedQueue类的算法,但是真正的实现与它略有区别,ConcurrentLinkedQueue并未使用原子化的引用(AtomicReference),而是使用普通的volatile引用来代替下一个节点next字段,并通过基于反射实现的AtomicReferenceFieldUpdater来进行更新next字段的:
private class Node<E> {
private final E item;
private volatile Node<E> next;
public Node(E item) {
this.item = item;
}
boolean casNext(Node<E> cmp, Node<E> val) {
return nextUpdater.compareAndSet(this, cmp, val);
}
void setNext(Node<E> val) {
nextUpdater.set(this, val);
}
}
private static AtomicReferenceFieldUpdater<Node, Node> nextUpdater//用来对next字段进行更新
= AtomicReferenceFieldUpdater.newUpdater(Node.class, Node.class, "next");
原子化的域更新器类(AtomicReferenceFieldUpdater、AtomicIntegerFieldUpdater 和 AtomicLongFieldUpdater),代表那些是已存在的volatile域的基于反射技术的“视图”,使用CAS能够用于已有的volatile域。但更新器提供的原子性保护比普通的原子类(如AtomicReference)差一些,因为你不能保证那些底层的volatile变量不被直接修改,换句话说,你只能通过这些volatile这是所对应的域更新器对象来操作它们都能得到保证。
使用域更新器来原子化操作volatile变量的好处是性能相对于直接使用原子变量的性能要好一些,对于频繁创建、短周期的的对象,比如队列的next链接节点,减少为每个Node都需创建一个AtomicReference,这对于减少插入操作的开销是非常有效的。然面,几乎在所有的情况下,普通原子变量已表现相当不错了——仅仅在很少的情况下才需要使用原子化的域更新器(当你想要保留现有类的序列化模式时)。
标签:
原文地址:http://www.cnblogs.com/jiangzhengjun/p/4289498.html