标签:
1 String str1 = "abc";// 没有创建任何对象 2 String str2 = new String("abc");// 创建了2个对象 3 String str3 = new String("abc");// 创建了1个对象 4 System.out.println(str1 == str2);// 输出:false 5 System.out.println(str1 == str3);// 输出:false 6 System.out.println(str2 == str3);// 输出:false
分析:
Java编程如何避免内存溢出?
常用数据结构:
Hashtable:
HashMap:
HashSet:
?ArrayList:
LinkedList:
Vector:
字节流与和字符流:
所有的文件在硬盘或在传输时都是以字节的方式进行的,包括图片等都是按字节的方式存储的,而字符是只有在内存中才会形成,所以在开发中,字节流使用较为广泛;在实际开发中出现的汉字问题实际上都是在字符流和字节流之间转化不统一而造成的。
从字节流转化为字符流 = byte[] 转化为String
从字符流转化为字节流 = String 转化为byte[]
对应关系如下:
Reader InputStream
├BufferedReader BufferedInputStream
│ └LineNumberReader LineNumberReader
├CharArrayReader ByteArrayInputStream
├InputStreamReader (none)
│ └FileReader FileInputStream
├FilterReader FilterInputStream
│ └PushbackReader PushbackInputStream
├PipedReader PipedInputStream
└StringReader StringBufferInputStream
Write OutputStream
├BufferedWriter BufferedOutputStream
├CharArrayWriter ByteArrayOutputStream
├OutputStreamWriter (none)
│ └FileWriter FileOutputStream
├FilterWriter FilterOutputStream
├PrintWriter PrintStream
├PipedWriter PipedOutputStream
└StringWriter (none)
字节流:
字符流:
例子:使用字节流时,即使不关闭输出流,也不影响输出:
1 public class FileOutputStreamTest { 2 public static void main(String[] args) throws Exception { 3 File filePath = new File("d:" + File.separator + "test.txt"); 4 OutputStream out = new FileOutputStream(filePath); 5 String str = "Hello World!!!"; 6 byte bytes[] = str.getBytes();// 字符串转byte数组 7 out.write(bytes); 8 // 不关闭输出流 9 // out.close(); 10 } 11 }
例子:使用字符流时,不关闭输出流时,有必要进行强制刷新(flush),否则无法正确写入内容:
1 public class FileWriterTest { 2 public static void main(String[] args) throws Exception { 3 File filePath = new File("d:" + File.separator + "test.txt"); 4 Writer out = new FileWriter(filePath); 5 String str = "Hello World!!!"; 6 out.write(str); 7 // 强制性清空缓冲区中的内容 8 // out.flush(); 9 10 // 不关闭输出流 11 // out.close(); 12 } 13 }
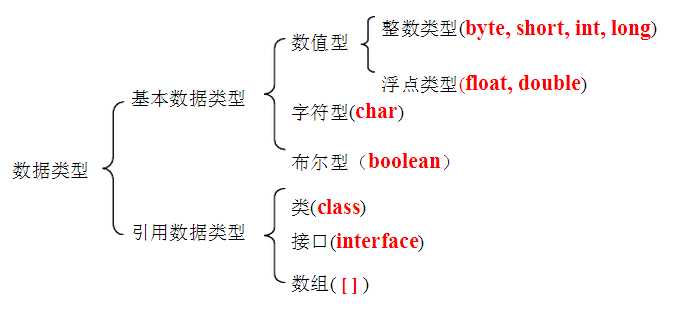
| 基本数据类型 | 大小 | 最小值 | 最大值 |
| boolean | —– | —– | —— |
| char | 16-bit | Unicode 0 | Unicode 2^16-1 |
| byte | 8-bit | -128 | +127 |
| short | 16-bit | -2^15 | +2^15-1 |
| int | 32-bit | -2^31 | +2^31-1 |
| long | 64-bit | -2^63 | +2^63-1 |
| float | 32-bit | IEEE754 | IEEE754 |
| double | 64-bit | IEEE754 | IEEE754 |
1 public class BasicTypeTest { 2 public static void main(String[] args) { 3 // byte 4 System.out.println("基本类型:byte 二进制位数:" + Byte.SIZE); 5 System.out.println("包装类:java.lang.Byte"); 6 System.out.println("最小值:Byte.MIN_VALUE=" + Byte.MIN_VALUE); 7 System.out.println("最大值:Byte.MAX_VALUE=" + Byte.MAX_VALUE); 8 System.out.println(); 9 10 // short 11 System.out.println("基本类型:short 二进制位数:" + Short.SIZE); 12 System.out.println("包装类:java.lang.Short"); 13 System.out.println("最小值:Short.MIN_VALUE=" + Short.MIN_VALUE); 14 System.out.println("最大值:Short.MAX_VALUE=" + Short.MAX_VALUE); 15 System.out.println(); 16 17 // int 18 System.out.println("基本类型:int 二进制位数:" + Integer.SIZE); 19 System.out.println("包装类:java.lang.Integer"); 20 System.out.println("最小值:Integer.MIN_VALUE=" + Integer.MIN_VALUE); 21 System.out.println("最大值:Integer.MAX_VALUE=" + Integer.MAX_VALUE); 22 System.out.println(); 23 24 // long 25 System.out.println("基本类型:long 二进制位数:" + Long.SIZE); 26 System.out.println("包装类:java.lang.Long"); 27 System.out.println("最小值:Long.MIN_VALUE=" + Long.MIN_VALUE); 28 System.out.println("最大值:Long.MAX_VALUE=" + Long.MAX_VALUE); 29 System.out.println(); 30 31 // float 32 System.out.println("基本类型:float 二进制位数:" + Float.SIZE); 33 System.out.println("包装类:java.lang.Float"); 34 System.out.println("最小值:Float.MIN_VALUE=" + Float.MIN_VALUE); 35 System.out.println("最大值:Float.MAX_VALUE=" + Float.MAX_VALUE); 36 System.out.println(); 37 38 // double 39 System.out.println("基本类型:double 二进制位数:" + Double.SIZE); 40 System.out.println("包装类:java.lang.Double"); 41 System.out.println("最小值:Double.MIN_VALUE=" + Double.MIN_VALUE); 42 System.out.println("最大值:Double.MAX_VALUE=" + Double.MAX_VALUE); 43 System.out.println(); 44 45 // char 46 System.out.println("基本类型:char 二进制位数:" + Character.SIZE); 47 System.out.println("包装类:java.lang.Character"); 48 System.out.println("最小值:Character.MIN_VALUE=" + (int) Character.MIN_VALUE);//以数值形式而不是字符形式输出 49 System.out.println("最大值:Character.MAX_VALUE=" + (int) Character.MAX_VALUE);//以数值形式而不是字符形式输出 50 } 51 }
常见的final类:
String、Math;Integer 、Long、Character 等包装类。
需要注意的是:
按特定的时间格式获取其毫秒数:
1 SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss"); 2 Date startDate = sdf.parse("2014-07-11 00:00:00"); 3 Date endDate = sdf.parse("2014-07-11 23:59:59"); 4 long startTime = startDate.getTime();//单位:毫秒 5 long endTime = endDate.getTime();//单位:毫秒
Java常见的两种解析XML的方式:
DOM-基于文档树结构的解析
例子:
1 private static void readXmlByDOM(String filePath)throws ParserConfigurationException, SAXException, IOException { 2 File file = new File(filePath); 3 DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance();// step 4 // 1:获得DOM解析器工厂,作用是创建具体的解析器 5 DocumentBuilder db = dbf.newDocumentBuilder();// step 2:获得具体的dom解析器 6 Document document = db.parse(file);// step 3:解析一个xml文档,获得Document对象(根节点) 7 // 根据标签名字访问节点 8 NodeList list = document.getElementsByTagName("test"); 9 System.out.println("list length: " + list.getLength()); 10 // 遍历每一个节点 11 for (int i = 0; i < list.getLength(); ++i) { 12 System.out.println("----------------------"); 13 Element element = (Element) list.item(i); 14 String test = element.getElementsByTagName("name").item(0) 15 .getNodeValue(); 16 System.out.println(test);// 此处输出:null 17 // 节点getNodeValue的值永远为null 18 // 解决方法:加上getFirstChild() 19 Node node1 = element.getElementsByTagName("name").item(0) 20 .getFirstChild(); 21 String content = node1.getNodeValue(); 22 System.out.println("name: " + content); 23 24 Node node2 = element.getElementsByTagName("sex").item(0) 25 .getFirstChild(); 26 content = node2.getNodeValue(); 27 System.out.println("author: " + content); 28 29 Node node3 = element.getElementsByTagName("age").item(0) 30 .getFirstChild(); 31 content = node3.getNodeValue(); 32 System.out.println("year: " + content); 33 } 34 }
SAX-基于事件流的解析
例子:
1 // 需导入dom4j包 2 private static void readXmlBySAX(String filePath) throws DocumentException { 3 SAXReader reader = new SAXReader(); 4 File file = new File(filePath); 5 Document doc = (Document) reader.read(file); 6 Element root = doc.getRootElement(); 7 Iterator iterator = root.elementIterator("test"); 8 while (iterator.hasNext()) { 9 Element element = (Element) iterator.next(); 10 String name = element.elementText("name"); 11 String sex = element.elementText("sex"); 12 Integer age = Integer.parseInt(element.elementText("age")); 13 System.out.println("----------------------"); 14 System.out.println("name: " + name); 15 System.out.println("sex: " + sex); 16 System.out.println("age: " + age); 17 } 18 }
Java的算术右移">>"和逻辑右移">>>":
例子:
1 System.out.println("=============算术右移 >> ==========="); 2 int i = 0xC0000000; 3 System.out.println("移位前:i= " + i + " = " + Integer.toBinaryString(i) + "(B)"); 4 i = i >> 28; 5 System.out.println("移位后:i= " + i + " = " + Integer.toBinaryString(i) + "(B)"); 6 7 System.out.println("---------------------------------"); 8 int j = 0x0C000000; 9 System.out.println("移位前:j= " + j + " = " + Integer.toBinaryString(j) + "(B)"); 10 j = j >> 24; 11 System.out.println("移位后:j= " + j + " = " + Integer.toBinaryString(j) + "(B)"); 12 13 System.out.println("==============逻辑右移 >>> ============="); 14 int m = 0xC0000000; 15 System.out.println("移位前:m= " + m + " = " + Integer.toBinaryString(m) + "(B)"); 16 m = m >>> 28; 17 System.out.println("移位后:m= " + m + " = " + Integer.toBinaryString(m) + "(B)"); 18 19 System.out.println("---------------------------------"); 20 int n = 0x0C000000; 21 System.out.println("移位前:n= " + n + " = " + Integer.toBinaryString(n) + "(B)"); 22 n = n >> 24; 23 System.out.println("移位后:n= " + n + " = " + Integer.toBinaryString(n) + "(B)"); 24 25 System.out.println("\n"); 26 System.out.println("==============移位符号的取模==============="); 27 int a = 0xCC000000; 28 System.out.println("移位前:a= " + a + " = " + Integer.toBinaryString(a) + "(B)"); 29 int a1 = a >> 32; 30 int a2 = a >>> 32; 31 System.out.println("算术右移32位:a1=" + a1 + " = " + Integer.toBinaryString(a1) + "(B)"); 32 System.out.println("逻辑右移32位:a2=" + a2 + " = " + Integer.toBinaryString(a2) + "(B)");
关于Java的eqauls与= =:
= = 是面向过程的操作符;equals是面向对象的操作符
= =不属于任何类,equals则是任何类(在Java中)都实现(或继承)了的一个方法;
因此,
如果要比较两个基本类型的值是否相等,请用= =;//注:基本类型无equals方法可调用
如果要比较两个对象的地址是不是一样,请用= =;
如果要比较两个对象(非基本类型)的值是否相等,请用equals;
特殊字符及其转义:
1.八进制转义序列:
\ + 1到3位5数字;范围‘\000‘~‘\377‘
\0:空字符
2.Unicode转义字符:
\u + 四个十六进制数字;0~65535
\u0000:空字符
3.特殊字符:3个
\":双引号
\‘:单引号
\\:反斜线
4.控制字符:5个
\‘ 单引号字符
\\ 反斜杠字符
\r 回车
\n 换行
\f 走纸换页
\t 横向跳格
\b 退格
点的转义:. ==> u002E
美元符号的转义:$ ==> u0024
乘方符号的转义:^ ==> u005E
左大括号的转义:{ ==> u007B
左方括号的转义:[ ==> u005B
左圆括号的转义:( ==> u0028
竖线的转义:| ==> u007C
右圆括号的转义:) ==> u0029
星号的转义:* ==> u002A
加号的转义:+ ==> u002B
问号的转义:? ==> u003F
反斜杠的转义: ==> u005C
对象锁:
类锁:
若要同时获取两种锁,同时获取类锁和对象锁是允许的,并不会产生任何问题,
但使用类锁时一定要注意,一旦产生类锁的嵌套获取的话,就会产生死锁,因为每个class在内存中都只能生成一个Class实例对象。
标签:
原文地址:http://www.cnblogs.com/xianDan/p/4292861.html