标签:
SQL Server Column Store Indeses
SQL Server 11增加了新特性列存储索引和相关的查询操作符。批量行处理来提高数据仓库的查询性能。
传统的数据库系统使用行存储的,heap,btree都是。这种数据组织方式对于,只处理到一部分数据的事务处理表现很好,但是并不适应数据仓库的,数据仓库通常是对扫描很多记录,但是只涉及到某一些行。这个时候列方式组织就能执行的很好。因为可以读取需要的列,并且列存储的数据可以得到很好的压缩。
SQL Server列存储索引是纯粹的列存储,不是混合的。不同的列被存放在不同的page下。
使用1TB测试数据库(TPC-DS),catalog_sales包含1.44billion条数据,使用星型结构来测试列存储索引的性能提升,只对事实表做列存储索引,其他表都是行存储。在40核启用了超线程,256GB内存,磁盘性能在10GB/sec设备上测试。
SELECT w_city ,w_state ,d_year ,SUM(cs_sales_price) AS cs_sales_price
FROM Warehouse ,catalog_sales ,date_dim
WHERE w_warehouse_sk = cs_warehouse_skAND cs_sold_date_sk = d_date_skAND w_state = ‘SD‘AND d_year = 2002
GROUP BY w_city , w_state ,d_year
ORDER BY d_year , w_state , w_city;
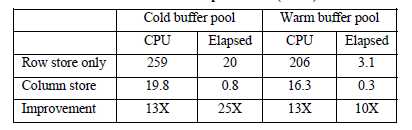
比较容易看出性能,在improvement行中可以看出,CPU花费少了13倍,在cold情况下执行时间少了25倍。
在SQL Server 11之前所有的索引都是以行存储的。不管是btree还是heap。
列存储,以新的索引类型引入到SQL Server列存储索引。设计的目的是为了加快列的扫描。
列存储保存方式如下:
1. 把行转化为column segment,先把行分为一个个的row groups,每个groups由1million数据。每个row group独立的进行编码和压缩。生产一个压缩的column segment,里面只包含一个列。
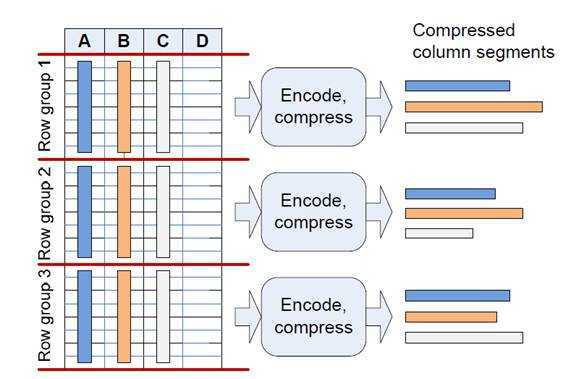
如图表分为3个row group,独立的进行编码和压缩,生成9个压缩的column segments。
2. 然后使用现有的blob存储机制来保存这些压缩的column segments。Segment目录用来跟踪每个segment的位置,这样每个segment可以很容易的被定位。这个segment目录被保存在系统表可以使用sys.column_store_segments来查看,视图里面也保存了一些元数据。
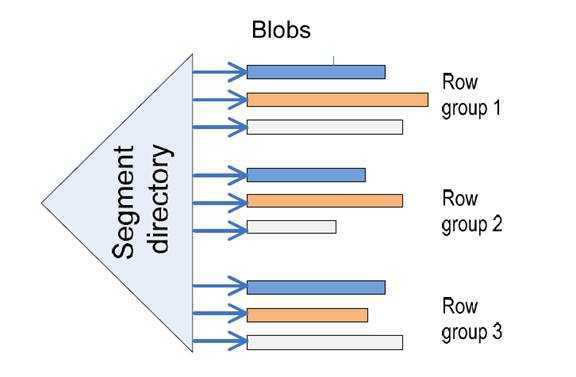
数据存储是使用压缩的方式来减少存储空间和I/O消耗。可以选择允许column segment直接使用不需要解压缩。压缩步骤如下:
1.对所有的column的值进行编码。
2.优化行的顺序。
3.对每个行进行压缩。
编码就是把列值转化为唯一的类型:32bit或者64bit。支持2个类型的encode:基于字典的编码和基于值的编码。
基于字典的编码把不同的值转为连续的int值的集合。存入数据目录,本质上是存入以dataids为索引的一个数组中。每个数据字典保存在独立的blob中,可以使用sys.column_store_dictionaries查看。
基于值的编码应用在int或者decimal数据类型上。把某个范围的值弄小。基于值的编码由2部分组成:基值和指数。
一旦指数被选中,column segment上的值就会被调整。
重要的性能提升主要是来自于压缩,数据使用RLE压缩(run-length encoding)。RLE在许多一样的数据在一起的时候压缩表现会很好。因为在row groups中顺序是不重要的,所以可以随意的重新组织顺序来提高压缩效率。
我们使用vertipaq算法来重新重新组织row group中的顺序,提高RLE的压缩性能。
一旦row group中的行被重新排序,就可以使用RLE来压缩。
Blob存储的column segment或者字典可能跨多个page,当我们读入内存的时候column segment和字典被保存在新的cache中用来保存大对象,而不是基于page 的buffer pool中。而且每个对象都是连续的,没有空隙。
为了提高I/O性能,预读可以被应用在segment内和多个segment上。对于磁盘存储,可以使用额外的压缩,是否使用额外的压缩,需要在I/O和cpu之间平衡。
标准的查询处理是基于行的,一次处理一行,为了减少cpu,使用了新的处理方式,以批处理的方式一次性处理一批行。批处理方式适用于OLAP但是不会取代行处理在OLTP中的地位。
SQL Server没有去创建一个新的引擎,而是在原来的引擎上面做扩展。有以下好处:
1.用户不需要花时间在新的引擎上,和不需要再2个引擎上做转化。
2.极大的减少了实现引擎的花费
3.查询计划可以混合两个操作。
4.查询可以自动的在batch和row操作间转化。
5.所有的特性相容。
新的batch有独立的访问方法有不同的数据源支持,列存储索引的访问方法支持谓词和bitmap过滤。Batch模式一般适用于数据密集的计算,计算复制的过滤条件,select列表,join和聚合。
新的访问方法有新的优化,如:延迟字符串实例化和透明使用新的迭代器。虽然批处理方式可以减少cpu处理时间,但是达不到目标。
有一些额外的优化方式:
1.新的迭代器针对最新的cpu进行优化,增加内存的吞吐量。
2.bitmap过滤的实现。
3.runtime资源管理被提升,可以让操作以更灵活的方式共享。
和其他索引不同,列存储索引不能很好的支持point query和range scan,因为列存储索引没有顺序,没有统计信息。列存储索引值提供高压缩的数据来减少cpu和io,对于scan可以从列存储索引上提升性能。
是否使用batch处理方式由查询分析器决定,也可以混合row和batch处理,但是2者之间的转化是有花费的,因此mssql会限制转化次数。
为了在生成的图形计划中区分batch和row,加入了一个新的属性,用这个属性来区分是batch还是row。,也可以决定是否有必要做转化。所有的batch操作要求输入都是batch,row操作输入都是row。
除了batch处理方法,也引入的新的方法来控制多个join。Sql server优化器视图把inner join转化为一个多维join操作。好处是可以一次性处理整个join graph。
1.我们先通过join的表达式和谓词来识别那个join key 是唯一的。使用识别的唯一信息来判断哪些是事实表,哪些是维度表,事实表不会有唯一信息。
2.然后从最小的事实表开始展开join graph,尽量多的覆盖维度表,在事实表周围形成一个雪花型。然后处理另外一个试试表。
3.之后,我们会有多个雪花型join,然后从最大的事实表开始,递归的把周围的雪花以维度表方式加入,开始形成最终的执行计划。首先,识别哪些join值得创建bitmap过滤,一旦识别就创建一个right deep join树,把维度表放在左边,事实表放在右边。每个维度表可能都是一个雪花型,然后以递归的方式分解每一个雪花。在每个join上,确定条件,检查是否可以使用batch,如果不行则用row模式。若到达了,所有吧可以batch的放在下面,其他的放在上面。
参考:
SQL Server Column Store Indexes
SQL Server Column Store Indeses
标签:
原文地址:http://www.cnblogs.com/Amaranthus/p/4294085.html