标签:
一、快速排序的描述
快速排序是基于分治策略的。对一个子数组A[p…r]快速排序的分治过程的三个步骤为:
1、分解
数组A[p…r]被划分成两个(可能空)子数组A[p…q-1]和A[q+1…r],使得A[p…q-1]中的每个元素都小于等于A[q],且小于等于A[q+1…r]中的元素。下标q也在这个划分过程中进行计算。
2、解决
通过递归调用快速排序,对子数组A[p…q-1]和A[q+1…r]排序。
3、合并
因为两个字数组就是原地排序的,将它们的合并不需要操作:整个数组A[p…r]已排序。
快速排序的参考代码如下:
1 class Solution 2 { 3 public: 4 void QuickSort(int *a, int length); 5 void QSort(int *a, int low, int high); 6 int Partition(int *a, int low, int high); 7 }; 8 9 void Solution::QuickSort(int *a, int length) 10 { 11 QSort(a, 0, length - 1); 12 } 13 14 void Solution::QSort(int *a, int low, int high) 15 { 16 if (low < high) 17 { 18 int p = Partition(a, low, high); 19 QSort(a, low, p - 1); 20 QSort(a, p + 1, high); 21 } 22 } 23 24 int Solution::Partition(int *a, int low, int high) 25 { 26 int key = a[high], tmp; 27 int i = low - 1, j; 28 29 for (j = low; j < high; ++j) 30 { 31 if (a[j] <= key) 32 { 33 i = i + 1; 34 35 tmp = a[j]; //交换a[j]和a[i] 36 a[j] = a[i]; 37 a[i] = tmp; 38 } 39 } 40 41 tmp = a[high]; //交换a[high]和a[i + 1] 42 a[high] = a[i + 1]; 43 a[i + 1] = tmp; 44 45 return i + 1; 46 }
函数Partition()的另外一种直观写法如下:
1 int Solution::Partition(int *a, int low, int high) 2 { 3 int key = a[low]; 4 5 while (low < high) 6 { 7 while (low < high && key <= a[high]) 8 { 9 --high; 10 } 11 a[low] = a[high]; 12 13 while (low < high && key >= a[low]) 14 { 15 ++low; 16 } 17 a[high] = a[low]; 18 } 19 a[low] = key; 20 21 return low; 22 }
二、快速排序的性能
快速排序的运行时间与划分是否对称有关,而后者又与选择了哪一个元素来进行划分有关。如果划分是对称的,算法从渐进意义上就与归并排序一样快;如果划分是不对称的,算法从渐进意义上就和插入算法一样慢。函数Partition()在子数组A[p…r]上的运行时间为 ,其中n=r-p+1。
,其中n=r-p+1。
1、最坏情况划分
最坏情况划分发生在划分过程中产生的两个区域分别包含n-1个元素和1个0元素的时候。假设算法的每一次递归调用都出现这种不对称划分。划分的时间代价为,对一个大小为0的数组进行递归调用的时间代价为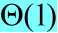 ,算法的运行时间可表示为:
,算法的运行时间可表示为:
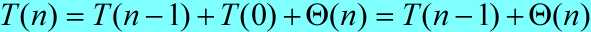 ,解出
,解出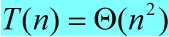 。
。
因此,如果在算法的每一层递归上,划分都是最大程度不对称的,算法的运行时间就是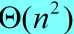 。从而,快速排序算法的最坏情况运行时间并不比插入排序的更好。例如:当输入数组已经完全排好序时,快速排序的运行时间为,插入排序的运行时间为。
。从而,快速排序算法的最坏情况运行时间并不比插入排序的更好。例如:当输入数组已经完全排好序时,快速排序的运行时间为,插入排序的运行时间为。
2、最佳情况划分
函数Partition()可能做的最平衡的划分中,得到的两个子问题的大小接近n/2。在这种情况下,快速排序运行的速度要快得多。算法的运行时间可表示为: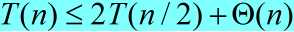 ,解出
,解出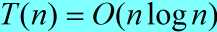 。
。
3、平衡的划分
快速排序的平均情况运行时间与其最佳情况运行时间很接近,而不是非常接近于其最坏情况运行时间。例如:假设划分过程总是产生9:1的划分,算法的运行时间可表示为: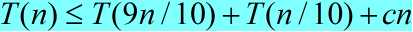 。这一递归式对应的递归树如图:
。这一递归式对应的递归树如图:
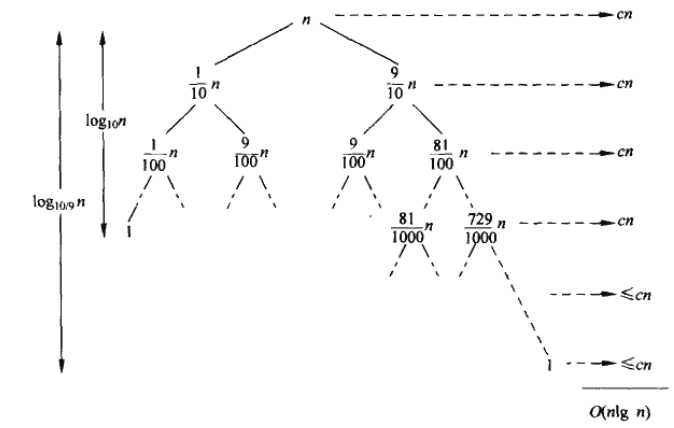
该树每层代价都是cn,直到在深度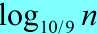 处终止。这样快速排序的总代价为
处终止。这样快速排序的总代价为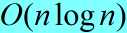 。
。
在递归的每一层上按照9:1的比例进行划分,直观上看好像相当不平衡,但从渐进意义上,这与在正中间划分的效果是一样的。事实上按照99:1划分运行时间也为,原因在于任何一种按照常数比例进行的划分都会产生深度为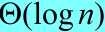 的递归树,其中每一层的代价为
的递归树,其中每一层的代价为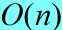 ,因而,每当按照常数比例划分时,总的运行时间都是。
,因而,每当按照常数比例划分时,总的运行时间都是。
三、结论
1、优点:因为每趟可以确定不止一个元素的位置,而且呈指数增加,所以特别快。前提:顺序存储结构。
2、改变划分元素的选取方法,至多只能改变算法平均情况下的时间性能,无法改变最坏情况下的时间性能。
3、是一种不稳定的排序算法,且不是原地排序。
4、对包含n个数的输入数组,最坏运行时间为。虽然这个最坏情况运行时间比较差,但快速排序通常是用于排序的最佳实用选择,因为其平均性能为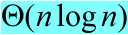 ,且记号中隐含的常数因子很小。在虚拟环境中也能很好地工作。
,且记号中隐含的常数因子很小。在虚拟环境中也能很好地工作。
标签:
原文地址:http://www.cnblogs.com/mengwang024/p/4294525.html