标签:
在某海量数据分析系统中,使用AC多模改进算法做多模匹配,作为数据分类和分发的第一道关口。部署时间较长后,内存占用较大,预处理时间随模式串数量的增加呈指数级增长,到达10W条模式串的时候已经无法正常运行。为满足需求,研究算法性能,在AC改进算法无法打成需求的情况下,研究WM匹配算法并进行改进,测试可支持10万级别的规则加载。并测试内存占用、预处理时间、匹配时间、文本检索效率等其他性能参数。
AC算法是基于有限自动的多模算法,在预处理阶段把模式集P装换为一个模式匹配机,称为AC自动机。AC自动机由一系列状态组成,每个状态用一个数字表示。具体的算法如下描述。
1) 计算出所有模式串的最短长度记为m
2) 构造模式树
for 每一个模式串
处理节点 = 根节点
From 尾字符 to 头字符
If (处理节点的一个子节点 == 当前处理字符)
处理下一个节点
else
创建新的节点存放处理字符 添加到 处理节点的子节点中
将当前模式串 添加到 处理节点指向的链表(模式串相同的链表)
3) 跳转表Shift1
Shift1表的大小是256,等于模式串字母表的大小。用于存放模式树中根节点的子节点匹配失败时的跳转步数。
for ( j = 0; j< 256; j++)
Shift1[j] = m
for 每一个模式串
for ( j = 0; j < 模式串长度; j++)
if (Shift1 [字符] > 模式串长度 – j – 1 )
Shift1 [字符] = 模式串长度 – j – 1
4) 跳转表Shift2
Shift2 存放的是非根节点的子节点匹配失败时的跳转步数。每个节点都有一个Shift2表。
处理节点A = 根节点
对模式树广度遍历
For 处理节点A的 空子节点(X)
处理节点A的Shift2[X] = m + 树的深度
设 当前失败节点F = 处理节点A的父亲节点的失败节点
While当前失败节点F 不是 根节点
if 当前失败节点F 存在 处理节点A的字符
处理节点的失败节点 = 当前失败节点
当前失败节点的Shift2[X] = Min(当前失败节点的Shift2[X] , 处理节点A的深度)
Break;
当前失败节点 = 当前失败节点的父亲节点的失败节点
If当前失败节点 是根节点
处理节点的失败节点 = 根节点
For 每个模式串结尾状态节点 t
If t的失败节点 state 不为根节点
对以state为根节点的树中的节点 r
r 节点的Shift2[X] = Min( t节点的深度+ state节点的深度- r节点深度,Shift2[X])
处理节点 = 根节点
处理字符 = 主串T的第m个字符
while 处理字符 <= T 的最后一个字符
If 处理节点的子节点 = 处理字符
While处理节点 != 根节点
If处理节点指向的链表非空
链表指向的模式串 全部 匹配中
处理节点 = 处理节点的失败节点
处理节点 = 处理节点的子节点
处理字符 = 处理字符的前一个字符
Else
if 处理节点 是 根节点
处理字符 = 处理字符 + Shift1[处理字符]
处理节点 = 根节点
Else
处理字符 = 处理字符 + Shift2[处理字符]
处理节点 = 根节点
输入模式串 :{ they , she , his , hers }
1) 预处理阶段
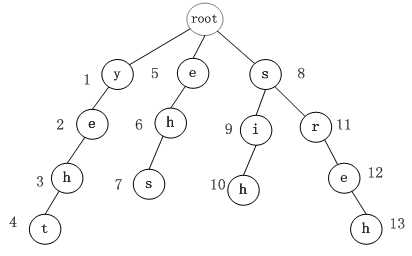
|
Shift1位置 |
值 |
|
t |
3 |
|
h |
1 |
|
e |
0 |
|
y |
0 |
|
s |
0 |
|
i |
1 |
|
r |
1 |
|
others |
3 |
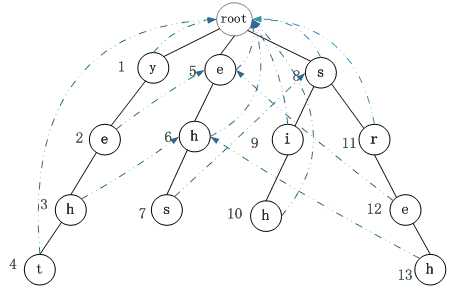
图1:失败指针
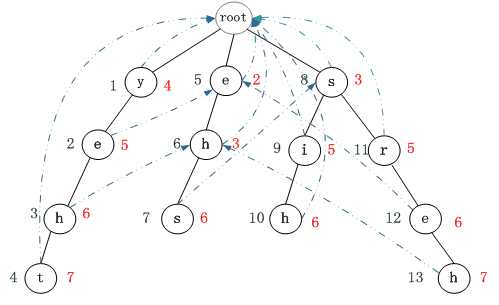
图2:Shift2初始化
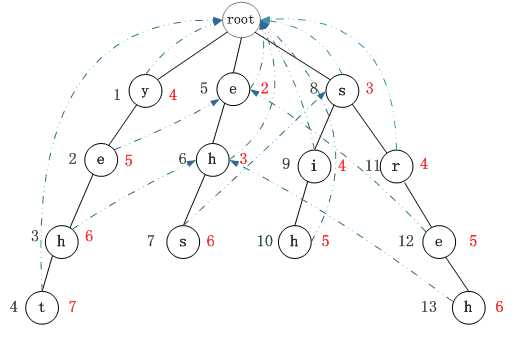
图2:进一步处理Shift2表
WM主要是利用SHIFT、HASH、PREFIX三张表。SHIFT[]就是一跳转表,一张记录向右滑动距离的表。HASH和PRIFIX表是对模式串的后缀及前缀分别做的索引。匹配时当SHIFT[i]=0时,说明模式串patterns肯定有暂时匹配上的,这时HASH[]表用来指明谁暂时匹配上了,然后对暂时匹配中的每一个模式串匹配进一步匹配。主要是先用PREFIX表匹配前缀,如果前缀也匹配上了,再匹配整个模式串。具体如下:
1) 计算出所有模式串的最短长度记为m,选择WM算法的处理块大小为B = 2。(B一般为2或3)
2) 构造Hash表
Hash[i]存放一个指向链表的指针,链表存着这样的patterns(第m-2、m-1、m 三位通过hash function计算是i)。Hash []表大小为256*256*256。
3) 构造Shift表
Shift表的大小是256*256。
Shift表中初始值赋值为m-B+1
for 每一个模式串
for (j = m-1; j > = B-1 ; j--)
对模式串中第 j-1、j 两个字符计算hash值,记为n
Shift[n] = min (Shift[n] , m-1-j)
4) 构造Prefix表
Prefix[i]存放第i个模式串的首B个字符的哈希值。匹配时用于匹配中了后缀之后再匹配前缀,可以减少匹配整个模式串的可能。
从待匹配主串T 的第m-B个字符开始处理,当前处理字符位置为 i,总长度为LN。
i = m-B
while i <= LN-B
对第i 、i+1 两个字符计算hash值,记为n
从Shift表中取出 Shift[n]的值,表示跳转的步数,记为 shift
While shift > 0
i += shift
if i > LN-B
return 匹配中的模式
n = 第i 、i+1 两个字符计算hash值
shift = Shift[n]
n = 第i-1、 i 、i+1 三个字符计算hash值
此处表示匹配中当前处理字符,从Hash表中Hash[n]获取对应的模式串
While 模式串存在
判断模式串的头两个字符和主串中对应的字符是否相等
如果相等
判断整个模式串和主串的相应位置
相等,表示匹配中,存入匹配中的数组
取模式串的下一个模式串next
n = 第i+1、i+2两个字符计算hash值
shift = Shift[n] + 1
i += shif
|
算法 |
内存占用 |
预处理时间 |
匹配效率 |
模式串限制 |
|
AC改进算法 |
比较大 |
大 O(N*L*L) |
高 模式串内容无影响 |
无 |
|
WM改进算法 |
小 |
小 O(N*m) |
较高 模式串内容有影响 |
最短长度不能小于2,且长度最好是相差不大 |
注:表中的L是模式串的平均长度,m是模式串的最短长度,N是模式串的个数。
随机产生的字符串。字母从
abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ1234567890.,;*&^$#@!随即选取。
CPU:E56系列(四核) *2
内存:16G
系统硬盘:500G SATA
存储:450G SAS*6
测试两种算法占用内存和加载时间
1、字符串长度10-20,测试字符串条数10000条
|
初始化空间 |
AC算法加载条数 |
WM算法加载条数 |
AC内存 |
WM内存 |
AC加载耗时 |
WM加载耗时 |
|
10240 |
4847 |
10000 |
222m |
71m |
40.01s |
0.17s |
|
9000 |
2394 |
9000 |
124m |
71m |
11.54s |
0.13s |
|
5000 |
2394 |
5000 |
111m |
68m |
11.14s |
0.14s |
|
2000 |
2000 |
2000 |
97m |
67m |
8.10s |
0.14s |
2、字符串长度20-40,测试字符串条数10000条
|
初始化空间 |
AC加载条数 |
WM加载条数 |
AC内存 |
WM内存 |
AC加载耗时 |
WM加载耗时 |
|
10240 |
2261 |
10000 |
214m |
71m |
20.13s |
0.17s |
|
9000 |
1133 |
9000 |
118m |
71m |
6.28s |
0.14s |
|
5000 |
1133 |
5000 |
111m |
68m |
6.34s |
0.14s |
|
2000 |
1133 |
2000 |
102m |
67m |
6.28s |
0.13s |
测试两种算法的匹配速度
1. 初始化为10240,加载字符串长度6-30,匹配次数100000次
|
待匹配串长度 |
加载规则条数 |
AC加载时间 |
WM加载时间 |
AC总匹配耗时 |
WM总匹配耗时 |
|
100 |
100 |
1.3s |
0.1s |
1.0s |
0.58s |
|
100 |
200 |
1.3s |
0.11s |
1.1s |
0.52s |
|
100 |
400 |
1.6s |
0.13s |
1.2s |
0.53s |
|
100 |
800 |
3.0s |
0.13s |
1.3s |
0.65s |
|
100 |
1600 |
8.1s |
0.13s |
1.5s |
0.78s |
|
100 |
3200 |
27s |
0.13s |
1.6s |
0.91s |
|
100 |
6400 |
|
0.17s |
|
1.2s |
规则条数是2447,虚拟机内存1G
a) 预处理性能测试
|
算法 |
开辟空间 |
成功加载条数 |
内存占用 |
加载时间 |
|
AC改进算法 |
10240 |
2092 |
162m |
5.4s |
|
WM改进算法 |
3000 |
2447 |
67m |
0.1s |
b) 匹配性能测试,匹配次数是100000。
|
匹配字符 |
匹配字符长度 |
AC改进算法总耗时 |
WM改进算法总耗时 |
|
某类账号A |
20 |
0.1s |
2.5s |
|
某类账号B |
10 |
0.1s |
0.07s |
|
URL |
21 |
0.1s |
0.52s |
|
某类账号C |
15 |
0.1s |
0.18s |
|
26字母 |
26 |
0.03s |
0.03s |
规则条数是3171,虚拟机内存1G
a) 预处理性能测试
|
算法 |
开辟空间 |
成功加载条数 |
内存占用 |
加载时间 |
|
AC改进算法 |
10240 |
3171 |
185m |
14.4s |
|
WM改进算法 |
4000 |
3171 |
67m |
0.1s |
b) 匹配性能测试,匹配次数100000次。
|
匹配协议 |
匹配字符长度 |
AC改进算法总耗时 |
WM改进算法总耗时 |
|
某类账号A |
32 |
0.2s |
1.1s |
|
某类账号B |
24 |
0.2s |
0.1s |
|
TEL |
17 |
0.15s |
1.2s |
|
某类账号C |
55 |
0.5s |
0.8s |
|
26字母 |
26 |
0.02s |
0.02s |
根据以上测试结果发现,以下方面影响到整个匹配程序的性能:
内存占用:WM改进算法比AC改进算法的内存小很多。
预处理: WM改进算法比AC改进算法的预处理时间小很多。
匹配速度:WM算法的匹配速度跟加载的模式串内容有很大的关系。
AC算法跟加载的模式串内容无关。
前缀:如果前缀内容大量相似,WM改进算法的Shift表和HASH表冲突比较多,匹配慢。
标签:
原文地址:http://www.cnblogs.com/njuzhoubing/p/4298769.html