标签:
一. 针对两种文件的国际化处理
代码中即.m文件的国际化
首先在你需要进行国际化处理的字符串外面加一层NSLocalizedString,注意中文也是可以的哦
textfield.text = [NSString stringWithFormat:NSLocalizedString(@"使用帮助", nil)];
NSLocalizedString是一个定义在NSBundle.h中的宏,其用途是寻找当前系统语言对应的Localizable.strings文件中的某个key的值。
第一个参数是key的名字,第二个参数是对这个“键值对”的注释,在用genstrings工具生成Localizable.strings文件时会自动加上去。
当我们把所有的.m文件都修改好了,就可以动用genstrings工具了
1. 启动终端,进入工程所在目录。
2. 新建两个目录,推荐放在资源目录下。
目录名会作用到Localizable.strings文件对应的语言,不能写错了。这里zh-Hans指简体中文,注意不能用zh.lproj表示。
mkdir zh-Hans.lproj
mkdir en.lproj
3. 生成Localizable.strings文件
genstrings -o zh-Hans.lproj *.m
genstrings -o en.lproj *.m
-o <文件夹>,指定生成的Localizable.strings文件放置的目录。
*.m,扫描所有的.m文件。这里支持的文件还包括.h, .java等。
如果你认为这样就结束了,那就too naive了,实际上,上面genstrings指令只能是该目录下的文件遍历,但不能实现递归遍历,这样在一些大工程里面明显不能满足需求,于是在工程里更普遍的用法是
find ./ -name *.m | xargs genstrings -o en.lproj
这是传说中shell组合指令find+xargs,find ./ -name *.m 会递归所有.m文件并存在一个数组中,这个数组经由pipe传递给了下一个指令,而xargs会将收到的数组一一分割,并交给genstrings执行。
这样我们就可以得到如下的文件结构
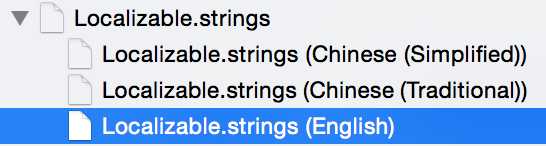
storyboard的国际化处理
看过文档或者其他介绍的都知道storyboard的国际化非常简单,这里简单介绍一下
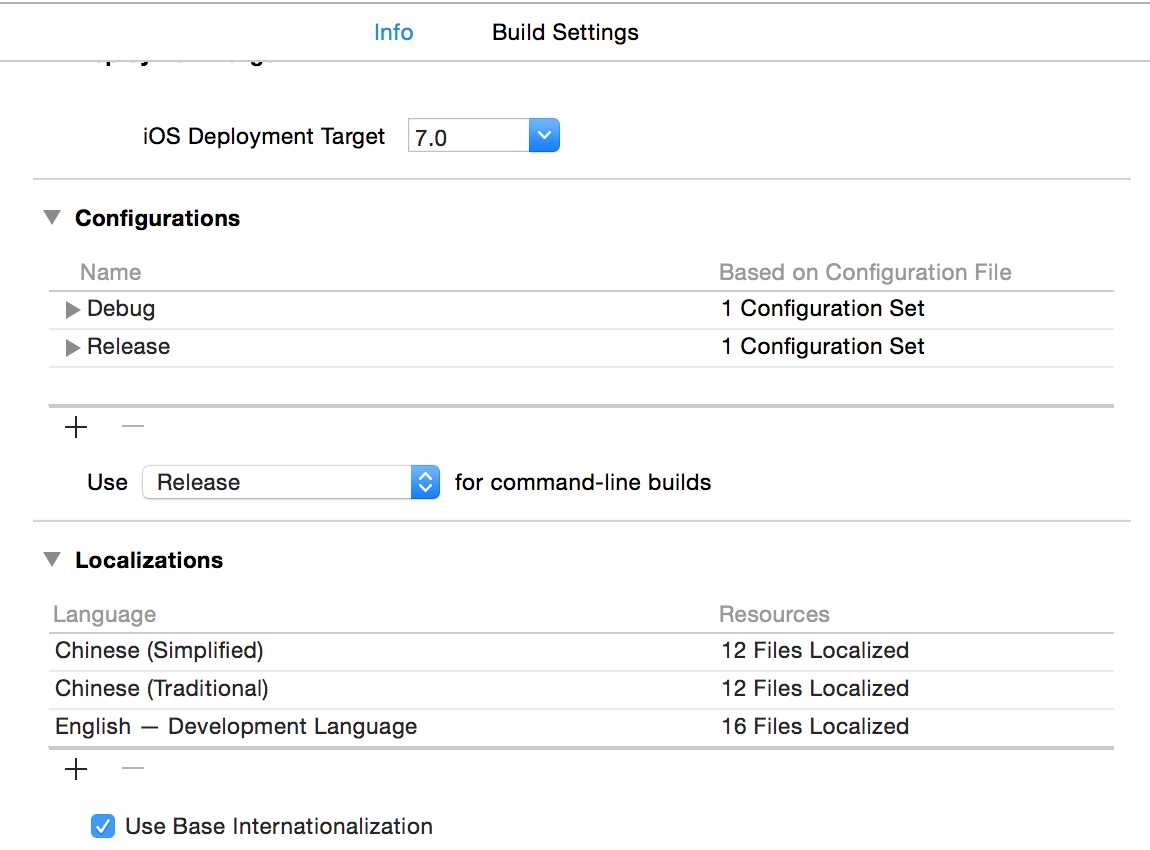
1 PROJECT -> Info -> Localizations 在这里添加你想增加的语种
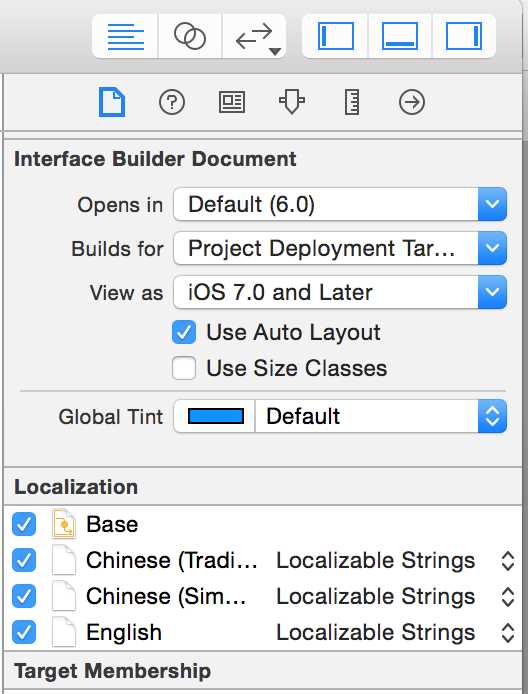
2 将storyboard的inspector栏目的localization项勾上后(图左),project的file navigator那里会多出几个文件(图右)
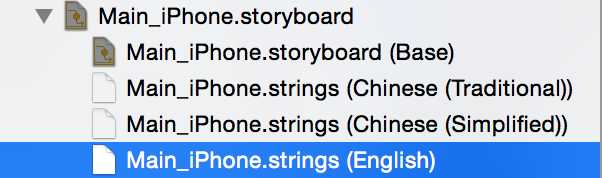

2 国际化后续优化
不足之处
到了这里其实关于iOS的国际化已经算是完成了,但你可能也发现一个问题了,上面两种方法全都是一次性生成文件,但我们的项目往往会不断地更新。重新照上面流程跑,生成的string文件会将之前翻译好的文件覆盖掉。
代码的国际化还好,毕竟一般面对新需求我们都会新建新的类和文件,只要把新代码文件脱到一个文件夹下,执行genstrings便可以得到一份对应的本地化文件,然后拿给翻译人员,最后将翻译好的键值对追加在初始的localizable.string文件尾部即可。
而storyboard的国际化便不能如此了,当然新建一个storyboard也是可以的,但如果是小改动我们一般还是会在原storyboard那里添加控件,这时候,原storyboard新增控件的国际化是我们今天要解决的重点。
解决方案
仔细观察storyboard的翻译文件,你会发现这里面也是一个个键值对,key是控件ID+状态,值就是显示文本。假设原来我们就有翻译文件A,添加控件后,我们再执行一次国际化指令,生成文件B,我们拿A和B对比,把B中多出来的键值对插入A文件的尾部,将A中有而B中没有的键值对删掉(即控件被删除),这样我们就算是更新了storyboard的翻译文件了。而这一步操作我们可以借助脚本文件来实现,XCode的Run Script也提供了脚本支持,可以让我们在Build后执行脚本。
脚本代码
#!/usr/bin/env python
# encoding: utf-8
"""
untitled.py
Created by linyu on 2015-02-13.
Copyright (c) 2015 __MyCompanyName__. All rights reserved.
"""
import imp
import sys
import os
import glob
import string
import re
import time
imp.reload(sys)
sys.setdefaultencoding(‘utf-8‘) #设置默认编码,只能是utf-8,下面\u4e00-\u9fa5要求的
KSourceFile = ‘Base.lproj/*.storyboard‘
KTargetFile = ‘*.lproj/*.strings‘
KGenerateStringsFile = ‘TempfileOfStoryboardNew.strings‘
ColonRegex = ur‘["](.*?)["]‘
KeyParamRegex = ur‘["](.*?)["](\s*)=(\s*)["](.*?)["];‘
AnotationRegexPrefix = ur‘/(.*?)/‘
def getCharaset(string_txt):
filedata = bytearray(string_txt[:4])
if len(filedata) < 4 :
return 0
if (filedata[0] == 0xEF) and (filedata[1] == 0xBB) and (filedata[2] == 0xBF):
print ‘utf-8‘
return 1
elif (filedata[0] == 0xFF) and (filedata[1] == 0xFE) and (filedata[2] == 0x00) and (filedata[3] == 0x00):
print ‘utf-32/UCS-4,little endian‘
return 3
elif (filedata[0] == 0x00) and (filedata[1] == 0x00) and (filedata[2] == 0xFE) and (filedata[3] == 0xFF):
print ‘utf-32/UCS-4,big endian‘
return 3
elif (filedata[0] == 0xFE) and (filedata[1] == 0xFF):
print ‘utf-16/UCS-2,little endian‘
return 2
elif (filedata[0] == 0xFF) and (filedata[1] == 0xFE):
print ‘utf-16/UCS-2,big endian‘
return 2
else:
print ‘can not recognize!‘
return 0
def decoder(string_txt):
var = getCharaset(string_txt)
if var == 1:
return string_txt.decode("utf-8")
elif var == 2:
return string_txt.decode("utf-16")
elif var == 3:
return string_txt.decode("utf-32")
else:
return string_txt
def constructAnotationRegex(str):
return AnotationRegexPrefix + ‘\n‘ + str
def getAnotationOfString(string_txt,suffix):
anotationRegex = constructAnotationRegex(suffix)
anotationMatch = re.search(anotationRegex,string_txt)
anotationString = ‘‘
if anotationMatch:
match = re.search(AnotationRegexPrefix,anotationMatch.group(0))
if match:
anotationString = match.group(0)
return anotationString
def compareWithFilePath(newStringPath,originalStringPath):
#read newStringfile
nspf=open(newStringPath,"r")
#newString_txt = str(nspf.read(5000000)).decode("utf-16")
newString_txt = decoder(str(nspf.read(5000000)))
nspf.close()
newString_dic = {}
anotation_dic = {}
for stfmatch in re.finditer(KeyParamRegex , newString_txt):
linestr = stfmatch.group(0)
anotationString = getAnotationOfString(newString_txt,linestr)
linematchs = re.findall(ColonRegex, linestr)
if len(linematchs) == 2:
leftvalue = linematchs[0]
rightvalue = linematchs[1]
newString_dic[leftvalue] = rightvalue
anotation_dic[leftvalue] = anotationString
#read originalStringfile
ospf=open(originalStringPath,"r")
originalString_txt = decoder(str(ospf.read(5000000)))
ospf.close()
originalString_dic = {}
for stfmatch in re.finditer(KeyParamRegex , originalString_txt):
linestr = stfmatch.group(0)
linematchs = re.findall(ColonRegex, linestr)
if len(linematchs) == 2:
leftvalue = linematchs[0]
rightvalue = linematchs[1]
originalString_dic[leftvalue] = rightvalue
#compare and remove the useless param in original string
for key in originalString_dic:
if(key not in newString_dic):
keystr = ‘"%s"‘%key
replacestr = ‘//‘+keystr
match = re.search(replacestr , originalString_txt)
if match is None:
originalString_txt = originalString_txt.replace(keystr,replacestr)
#compare and add new param to original string
executeOnce = 1
for key in newString_dic:
values = (key, newString_dic[key])
if(key not in originalString_dic):
newline = ‘‘
if executeOnce == 1:
timestamp = time.strftime(‘%Y-%m-%d %H:%M:%S‘,time.localtime(time.time()))
newline = ‘\n//##################################################################################\n‘
newline +=‘//# AutoGenStrings ‘+timestamp+‘\n‘
newline +=‘//##################################################################################\n‘
executeOnce = 0
newline += ‘\n‘+anotation_dic[key]
newline += ‘\n"%s" = "%s";\n‘%values
originalString_txt += newline
#write into origial file
sbfw=open(originalStringPath,"w")
sbfw.write(originalString_txt)
sbfw.close()
def extractFileName(file_path):
seg = file_path.split(‘/‘)
lastindex = len(seg) - 1
return seg[lastindex]
def extractFilePrefix(file_path):
seg = file_path.split(‘/‘)
lastindex = len(seg) - 1
prefix = seg[lastindex].split(‘.‘)[0]
return prefix
def generateStoryboardStringsfile(storyboard_path,tempstrings_path):
cmdstring = ‘ibtool ‘+storyboard_path+‘ --generate-strings-file ‘+tempstrings_path
if os.system(cmdstring) == 0:
return 1
def main():
filePath = sys.argv[1]
sourceFilePath = filePath + ‘/‘ + KSourceFile
sourceFile_list = glob.glob(sourceFilePath)
if len(sourceFile_list) == 0:
print ‘error dictionary,you should choose the dic upper the Base.lproj‘
return
targetFilePath = filePath + ‘/‘ + KTargetFile
targetFile_list = glob.glob(targetFilePath)
tempFile_Path = filePath + ‘/‘ + KGenerateStringsFile
if len(targetFile_list) == 0:
print ‘error framework , no .lproj dic was found‘
return
for sourcePath in sourceFile_list:
sourceprefix = extractFilePrefix(sourcePath)
sourcename = extractFileName(sourcePath)
print ‘init with %s‘%sourcename
if generateStoryboardStringsfile(sourcePath,tempFile_Path) == 1:
print ‘- - genstrings %s successfully‘%sourcename
for targetPath in targetFile_list:
targetprefix = extractFilePrefix(targetPath)
targetname = extractFileName(targetPath)
if cmp(sourceprefix,targetprefix) == 0:
print ‘- - dealing with %s‘%targetPath
compareWithFilePath(tempFile_Path,targetPath)
print ‘finish with %s‘%sourcename
os.remove(tempFile_Path)
else:
print ‘- - genstrings %s error‘%sourcename
if __name__ == ‘__main__‘:
main()
1 新建一个文件夹RunScript,存放python脚本,放在工程文件的目录下,如图:
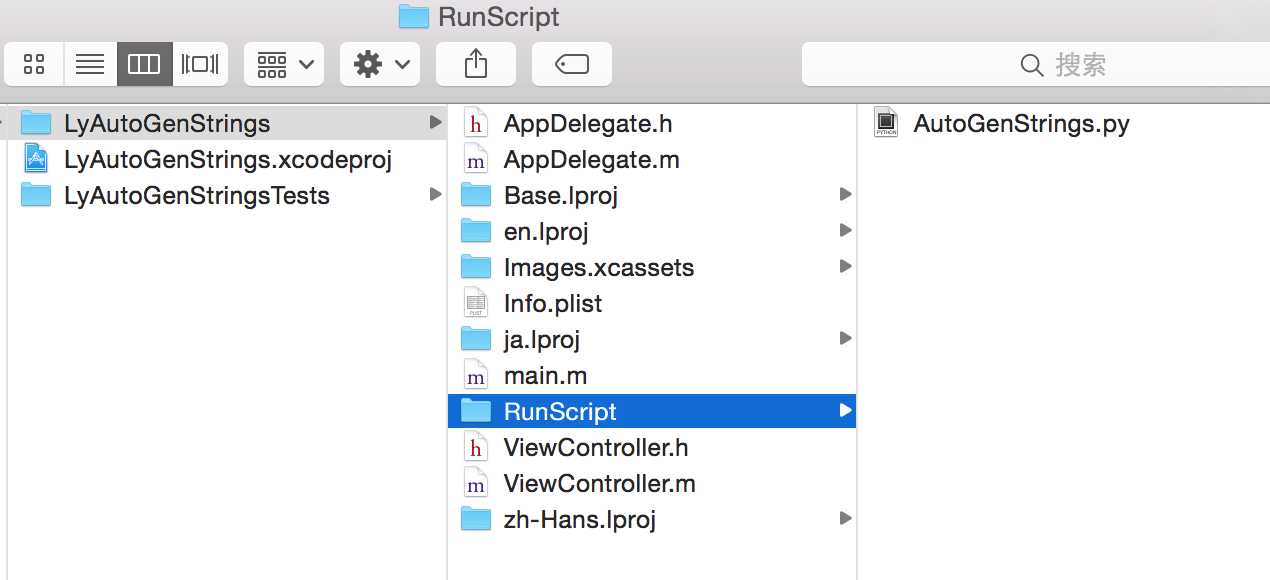
为了直观可以顺便把该文件夹拖入工程中(不做也可以)
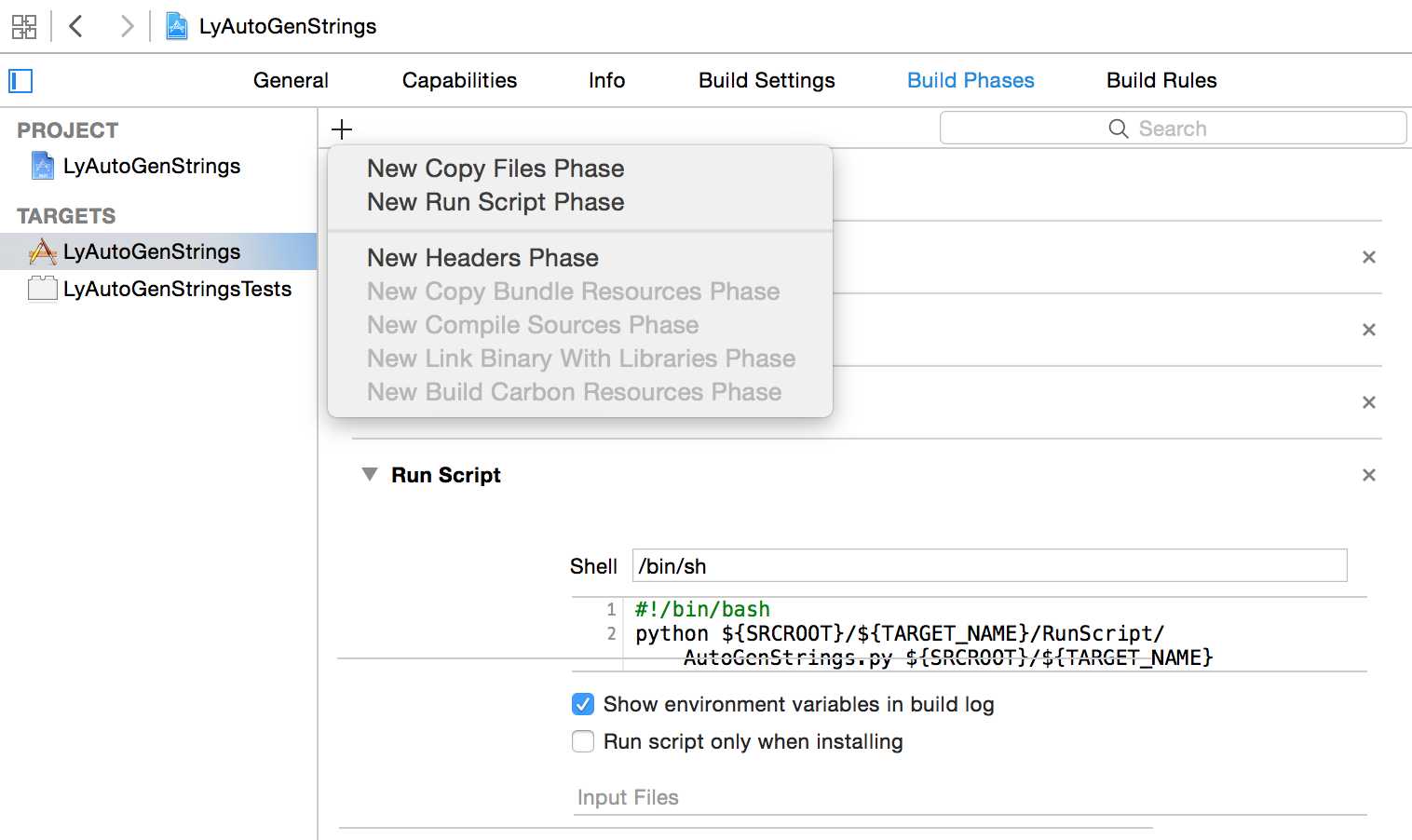
2 Target->Build Phases->New Run Script Phase,在shell里面写入下面指令
python ${SRCROOT}/${TARGET_NAME}/RunScript/AutoGenStrings.py ${SRCROOT}/${TARGET_NAME}
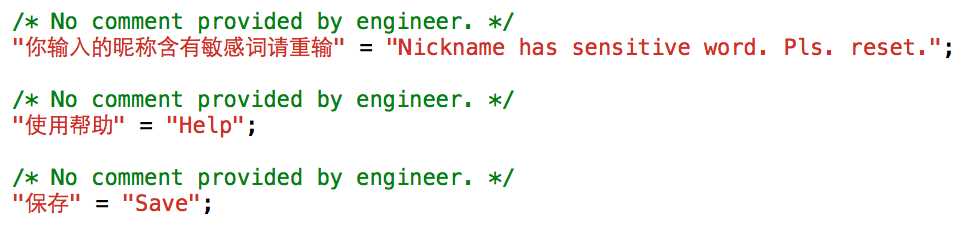
3 在Storyboard中添加一个textfield控件,再Bulid一下,成功后我们打开翻译文件,发增加了如下文本

4 我们没有必要每次Build都运行一次脚本,所以当你不需要的时候,可以在步骤2选上Run Script Only when installing,这样他就不会跑脚本,具体原因有兴趣的可以自行百度一下。
以下是相关程序的GitHub地址:
https://github.com/linyu92/MyGitHub
标签:
原文地址:http://www.cnblogs.com/levilinxi/p/4296712.html