标签:
首先介绍一下Flume是个神马东东。Flume可以实现从多种数据源获取数据,然后传递到不同的目标路径。通常是利用Flume传送logs到不同的地方,例如从web server收集logs文件然后传送到hadoop cluster进行分析之类的。Flume配置灵活简单,可以实现不同情况的日志传送,确实是一款不错的工具。
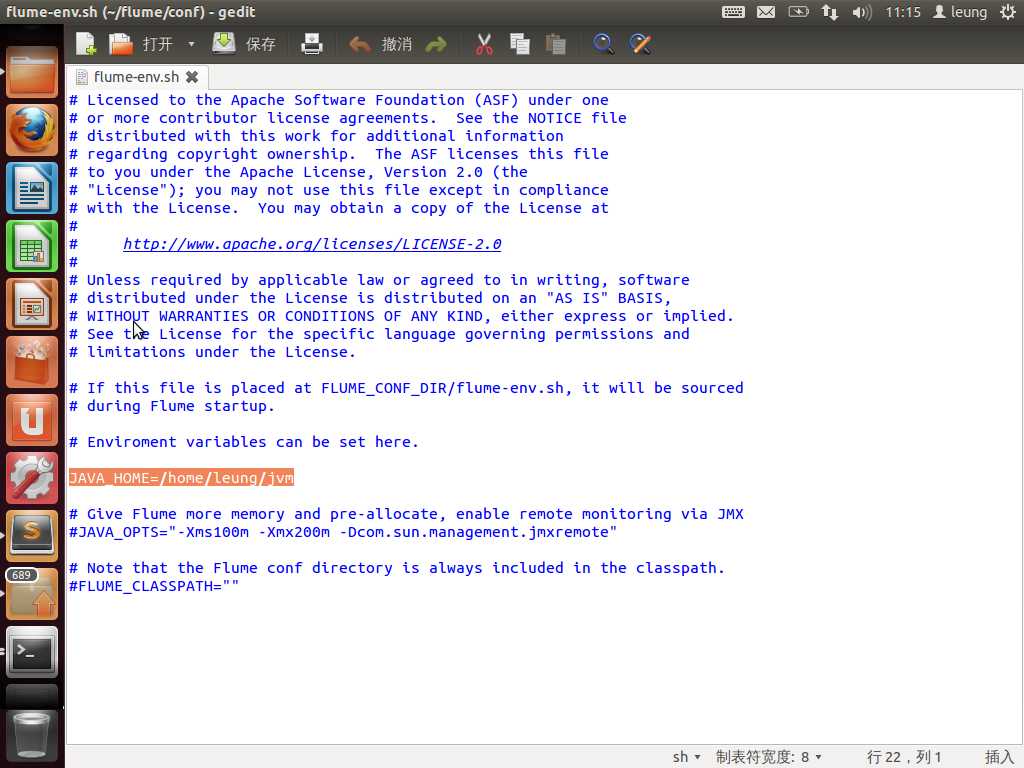
OK,接下来先看看怎么安装配置Flume。大家可以从http://flume.apache.org获取Flume的最新二进制版本。下载好后,解压,然后将flume的bin目录加到PATH中(这里默认系统已经安装好了java,并且已经将java的bin目录添加到PATH中)。最后进入flume目录中找到conf目录,将里面的flume-env.sh.template复制成flume-env.sh,然后往里面添加JAVA_HOME即可。至此就安装好了。
下面先解释一下Flume里面的几个重要角色,然后我们配置几个agent玩玩。
Flume里面有四个重要的角色,分别是source,channel,sink,event。Source负责收集数据并创建一个event,然后将event传递到指定的channel,接着event通过channel到达sink,sink负责将event的输出传递到指定的目标位置。简而言之,就是source→channel→sink→destination,其中传送的是event。
OK,先来看看一个简单agent。这个agent我们用来接收网络数据并写到flume的日志中。配置代码如下:
agent1.sources = netsource//指定source类型为netsource
agent1.sinks = logsink//指定sink类型为logsink
agent1.channels = memorychannel//指定channel类型为memorychannel,就是将数据读到内存中,然后传送
agent1.sources.netsource.type = netcat //netsource类型为netcat
agent1.sources.netsource.bind = localhost//绑定本机
agent1.sources.netsource.port = 3000//监听端口为本机的3000
agent1.sinks.logsink.type = logger//logsink的类型为logger
agent1.channels.memorychannel.type = memory //指定类型是memory
agent1.channels.memorychannel.capacity = 1000//指定数据缓存大小
agent1.channels.memorychannel.transactionCapacity = 100
agent1.sources.netsource.channels = memorychannel//指定source传送的channel
agent1.sinks.logsink.channel = memorychannel//指定sink的接收channel
将上面代码命名为agent1.conf并保持在flume的工作目录即可(我比较懒,没有新建,就直接使用下载后解压的flume目录了)。
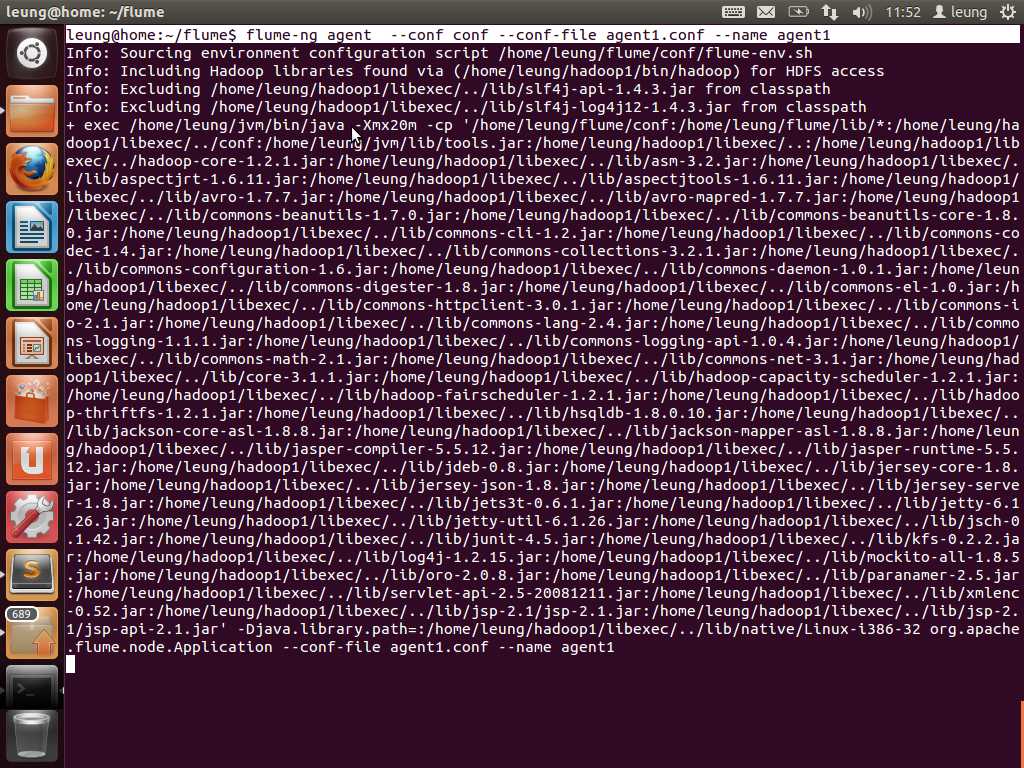
接下来启动这个agent!在终端中输入:flume-ng agent --conf conf --conf-file agent1.conf --name agent1 (--conf 指定conf目录,--conf-file指定配置文件名,--name指定agent名字)。
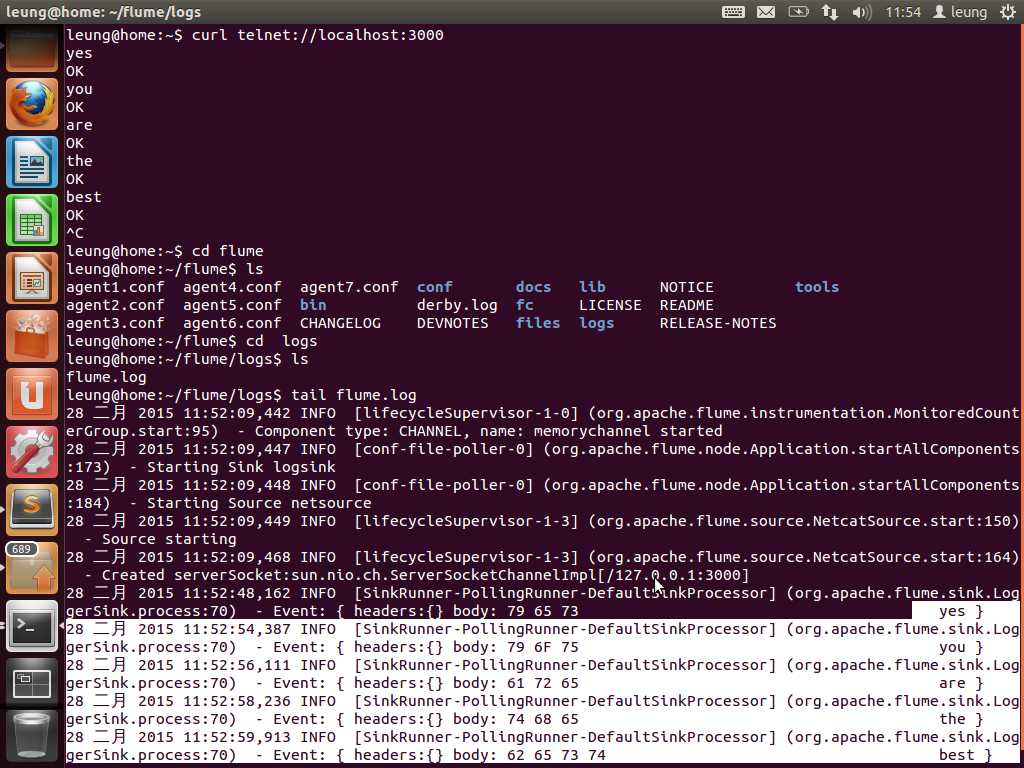
然后打开另一个终端窗口,使用curl工具从本地的3000端口输入一些数据,在到flume的日志文件中查看。即可看到数据已经已日志的格式保存到日志文件中。
到这里,我们已经完成了一个简单的抓取数据的过程。可是我们发现要进入目录读取比较麻烦,那我们干脆将数据写出到console吧。
只需要在启动命令后面加上参数-Dflume.root.logger=INFO,console即可。
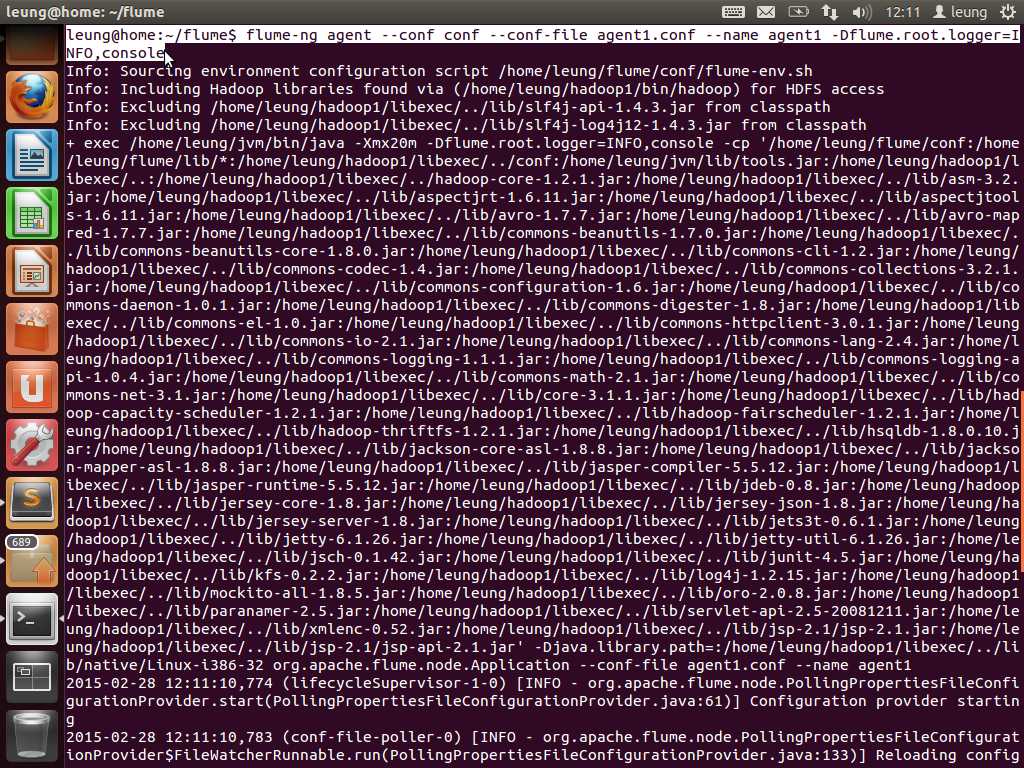
好了,我们来看看结果。可以看到,我们每次输入,内容都会在另一个终端同步显示。
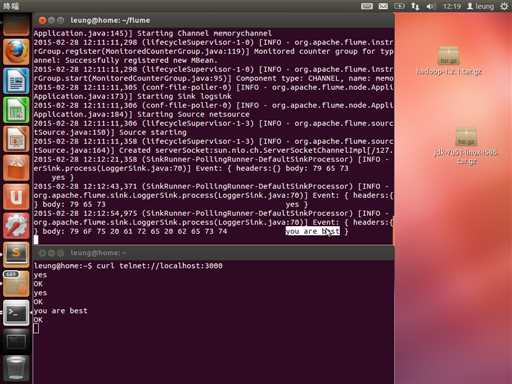
OK,这次就到这里。下一次再实现其他的agent!!谢谢大家的阅读。本人水平有限,如有纰漏,请不吝指正!不胜感激!
Data Collection with Apache Flume(一)
标签:
原文地址:http://www.cnblogs.com/UUhome/p/4305163.html