标签:
先上一个例子,这段代码是为了评估一个预测模型写的,详细评价说明在
https://www.kaggle.com/c/how-much-did-it-rain/details/evaluation,
它的核心是要计算
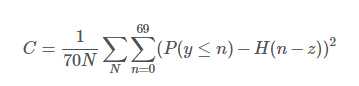
在实际计算过程中,n很大(1126694),以至于单进程直接计算时间消耗巨大(14分10秒),
所以这里参考mapReduce的思想,尝试使用多进程的方式进行计算,即每个进程计算一部分n,最后将结果相加再计算C
代码如下:
import csv import sys import logging import argparse import numpy as np import multiprocessing import time # configure logging logger = logging.getLogger("example") handler = logging.StreamHandler(sys.stderr) handler.setFormatter(logging.Formatter( ‘%(asctime)s %(levelname)s %(name)s: %(message)s‘)) logger.addHandler(handler) logger.setLevel(logging.DEBUG) def H(n, z): return (n-z) >= 0 def evaluate(args, start, end): ‘‘‘handle range[start, end)‘‘‘ logger.info("Started %d to %d" %(start, end)) expReader = open(‘train_exp.csv‘,‘r‘) expReader.readline() for i in range(start): expReader.readline() predFile = open(args.predict) for i in range(start+1): predFile.readline() predReader = csv.reader(predFile, delimiter=‘,‘) squareErrorSum = 0 totalLines = end - start for i, row in enumerate(predReader): if i == totalLines: logger.info("Completed %d to %d" %(start, end)) break expId, exp = expReader.readline().strip().split(‘,‘) exp = float(exp) predId = row[0] row = np.array(row, dtype=‘float‘) assert expId == predId lineSum = 0 for j in xrange(1,71): n = j - 1 squareErrorSum += (row[j]-H(n,exp))**2 lineSum += (row[j]-H(n,exp))**2 logger.info(‘SquareErrorSum %d to %d: %f‘ %(start, end, squareErrorSum)) return squareErrorSum def fileCmp(args): ‘‘‘check number of lines in two files are same‘‘‘ for count, line in enumerate(open(‘train_exp.csv‘)): pass expLines = count + 1 - 1 #discare header for count, line in enumerate(open(args.predict)): pass predictLines = count + 1 - 1 print ‘Lines(exp, predict):‘, expLines, predictLines assert expLines == predictLines evaluate.Lines = expLines if __name__ == "__main__": # set up logger parser = argparse.ArgumentParser(description=__doc__) parser.add_argument(‘--predict‘, help=("path to an predict probability file, this will " "predict_changeTimePeriod.csv")) args = parser.parse_args() fileCmp(args) pool = multiprocessing.Pool(processes=multiprocessing.cpu_count()) result = [] blocks = multiprocessing.cpu_count() linesABlock = evaluate.Lines / blocks for i in xrange(blocks-1): result.append(pool.apply_async(evaluate, (args, i*linesABlock, (i+1)*linesABlock))) result.append(pool.apply_async(evaluate, (args, (i+1)*linesABlock, evaluate.Lines+1))) pool.close() pool.join() result = [res.get() for res in result] print result print ‘evaluate.Lines‘, evaluate.Lines score = sum(result) / (70*evaluate.Lines) print "score:", score
这里是有几个CPU核心就分成几个进程进行计算,希望尽量榨干CPU的计算能力。实际上运行过程中CPU的占用率也一直是100%
测试后计算结果与单进程一致,计算时间缩短为11分47秒,快了16.8%。
提升没有想象中的大。
经过尝试直接用StringIO将原文件每个进程加载一份到内存在进行处理速度也没有进一步提升,结合CPU的100%占用率考虑看起来是因为计算能力还不够。
看来计算密集密集型的工作还是需要用C来写的:)
标签:
原文地址:http://www.cnblogs.com/instant7/p/4312786.html