标签:
目录
1. Linux文件系统简介 2. 通用文件模型 3. VFS相关数据结构 4. 处理VFS对象 5. 标准函数
1. Linux文件系统简介
Linux系统由数以万计的文件组成,其数据存储在硬盘或者其他块设备(例如ZIP驱动、软驱、光盘等)。存储使用了层次式文件系统,文件系统使用目录结构组织存储的数据,并将其他元信息(例如所有者、访问权限等)与实际数据关联起来
Linux支持许多不同的文件系统
1. Ext2 2. Ext3 3. ReiserFS 4. XFS 5. VFAT(兼容DOS) ..
不同文件系统锁基于的概念抽象差别很大,例如Ext2基于"Inode",它对每个文件哦度构造了一个单独的管理结构即"Inode",这些元信息也存储到磁盘上。inode包含了文件所有的元信息,以及指向相关数据块的指针,目录可以表示为普通文件,其数据包括了指向目录下所有文件的inode指针,因而层次结构得以建立。相比之下,ReiserFS广泛应用了树形结构来提供同样的层次功能
内核提供了一个额外的软件抽象层,将各种底层文件系统的具体特性与应用层包括内核自身隔离开来,该软件层称为VFS(Virtual Filesystem/Virtual Filesystem Switch 虚拟文件系统/虚拟文件系统交换器)。VFS既是向下的接口(所有文件系统都必须实现该接口,以此来和内核通信),同时也是向上的接口(用户进程通过系统调用访问的对外接口 实现系统调用功能)

为支持各种本机文件系统,且在同时允许访问其他操作系统的文件,Linux内核在用户进程(或C标准库)和文件系统实现之间引入了一个抽象层,该抽象层称之为虚拟文件系统(Virtual File System VFS)
VFS的任务很复杂,一方面,它用来提供一种操作文件、目录及其他对象的统一方法。另一方面,它必须能够与各种方法给出的具体文件系统的实现进行兼容,这导致了VFS在实现上的复杂性。但VFS带来的好处是使得Linux内核更加灵活了
Linux内核支持很多种文件系统
1. ext2 是Linux使用的,性能很好的文件系统,用于固定文件系统和可活动文件系统。它是作为ext文件系统的扩展而设计的。ext2在Linux所支持的文件系统中,提供最好的性能(在速度和CPU使用方面),ext2是Linux目前的主要文件系统 2. ext3文件系统 是对ext2增加日志功能后的扩展。它向前、向后兼容ext2。意为ext2不用丢失数据和格式化就可以转换为ext3,ext3也可以转换为ext2而不用丢失数据(只要重新安装该分区就行了) 3. proc 是一种假的文件系统,用于和内核数据结构接口,它不占用磁盘空间。参考 man proc 4. Devpts 是一个虚拟的文件系统,一般安装在/dev/pts。为了得到一个虚拟终端,进程打开/dev/ptmx,然后就可使用虚拟终端 5. raiserfs 是Linux内核2.4.1以后(2001年1 月)支持的,一种全新的日志文件系统 6. swap文件系统 swap文件系统用于Linux的交换分区。在Linux中,使用整个交换分区来提供虚拟内存,其分区大小一般应是系统物理内存的2倍,在安装Linux 操作系统时,就应创分交换分区,它是Linux正常运行所必需的,其类型必须是swap,交换分区由操作系统自行管理 7. vfat文件系统 vfat是Linux对DOS、Windows系统下的FAT(包括fat16和Fat32)文件系统的一个统称 8. NFS文件系统 NFS即网络文件系统,用于在UNIX系统间通过网络进行文件共享,用户可将网络中NFS服务器提供的共享目录挂载到本地的文件目录中,从而实现操作和访问NFS文件系统中的内容 9. ISO 9660文件系统 文件系统中光盘所使用的标准文件系统,是一种针对ISO9660标准的CD-ROM文件系统,Linux对该文件系统也有很好的支持,不仅能读取光盘和光盘ISO映像文件,而且还支持在Linux环境中刻录光盘
0x1: 文件系统类型
文件系统一般可以分为以下几种
1. 基于磁盘的文件系统(Disk-based Filesystem) 是在非易失介质存储文件的经典方式,用以在多次会话之间保持文件的内容。实际上,大多数文件系统都由此 2. 虚拟文件系统(Virtual Filesystem) 在内核中生成,是一种使用户应用程序与内核通信的方法。proc文件系统就是这一类的最好示例,它不需要任何种类的硬件设备上分配存储空间,而是内核建立了一个层次化的文件结构,其中的项包含了与系统特定部分相关的信息 ll /proc/version /* 占用空间: 0字节 -r--r--r--. 1 root root 0 Feb 27 23:39 /proc/version */ cat /proc/version /* 从内核内存中的数据结构提取出来 Linux version 2.6.32-504.el6.x86_64 (mockbuild@c6b9.bsys.dev.centos.org) (gcc version 4.4.7 20120313 (Red Hat 4.4.7-11) (GCC) ) #1 SMP Wed Oct 15 04:27:16 UTC 2014 */ 3. 网络文件系统(Network Filesystem) 基于磁盘的文件系统和虚拟文件系统之间的折中。这种文件系统允许访问另一台计算机上的数据,该计算机通过网络连接到本地计算机。它仍然需要文件长度、文件在目录层次中的位置、文件的其他重要信息。它也必须提供函数,使得用户进程能够执行通常的文件相关操作,如打开、读、删除等。由于VFS抽象层的存在,用户空间进程不会看到本地文件系统和网络文件系统之间的区别
2. 通用文件模型
VFS不仅为文件系统提供了方法和抽象,还支持文件系统中对象(或文件)的统一视图。由于各个文件系统的底层实现不同,文件在不同的底层文件系统环境下特性存在微秒的差异
1. 并非所有文件系统都支持同样的功能,而有些操作对"普通"文件是不可缺少的,却对某些对象完全没有意义,例如集成到VFS中的命名管道 2. 并非每一种文件系统都支持VFS中的所有抽象,例如设备文件无法存储在源自其他系统的文件系统中(例如FAT),因为FAT的设计没有考虑到设备文件这类对象
VFS的设计思想是提供一种结构模型,包含一个强大文件系统所应具备的所有组件,但该模型只存在于虚拟中,必须使用各种对象和函数指针与每种文件系统适配。所有文件系统的实现都必须提供与VFS定义的结构配合的例程,以弥合两种视图之间的差异
需要明白的是,虚拟文件系统的结构并非是凭空创造出来的,而是基于描述经典文件系统所使用的结构。VFS抽象层的组织和Ext2文件系统类似,这对基于完全不同概念的文件系统(例如ReiserFS、XFS)来说,会更加困难,但处理Ext2文件系统时会提高性能,因为在Ext2和VFS结构之间转换,几乎不会损失时间
在处理文件时,内核空间和用户空间所使用的主要对象是不同的
1. 对用户程序来说 一个文件由一个"文件描述符"标识,文件描述符是一个整数,在所有有关文件的操作中用作标识文件的参数。文件描述符是在打开文件时由内核分配的,只在一个进程内部有效,两个进程可以使用同样的文件描述符,但二者并不指向同一个文件,基于同一个描述符来共享文件是不可能的 2. 对内核来说 内核处理文件的关键是inode,每个文件(目录)都有且只有一个对应的inode,其中包含元数据(如访问权限、上次修改时间、等等)和指向文件数据的指针。但inode并不包含文件名
关于Linux下inode、链接的相关知识,请参阅另一篇文章
http://www.cnblogs.com/LittleHann/p/4208619.html
0x1: 编程接口
用户进程和内核的VFS实现之间由"系统调用"组成,其中大多数涉及对文件、目录和一般意义上的文件系统的操作,和文件操作相关的系统调用请参阅另一篇文章
http://www.cnblogs.com/LittleHann/p/3850653.html //搜索:0x3: 系统调用分类
文件使用之前,必须用open或openat系统调用打开,在成功打开文件之后,内核向用户层返回一个非负的整数,这种分配的文件描述符起始于3(0表示标准输入、1表示标准输出、2表示标准错误输出)。在文件已经打开后,其名称就没有用处了(文件名只是在利用inode进行文件遍历的时候起过滤作用),它现在由文件描述符唯一标识,所有其他库函数都需要传递文件描述符作为一个参数(进一步传递到系统调用)
尽管传统上文件描述符在内核中足以标识一个文件,但是由于多个命名空间(namespace)和容器(container)的引入,在不同层次命名空间中看到的同一个进程中的文件描述符(fd)是不同的,因为对文件的唯一表示由一个特殊的数据结构(struct file)提供
系统调用read需要将文件描述符作为第一个参数,以标识读取数据的来源
在一个打开文件中的当前位置保存在"文件位置指针(f_pos)",这是一个整数,指定了当前位置与文件起始点的偏移量。对随机存取文件而言,该指针可以设置成任何值,只要不超出文件存储容量范围即可,这用于支持对文件数据的随机访问。其他文件类型,如命名管道或字符设备的设备文件,不支持这种做法,它们只能从头至尾顺序读取
系统调用close关闭与文件的"连接"(释放文件描述符,以便在后续打开其他文件时使用)
关于struct file数据结构的相关知识,请参阅另一篇文章
http://www.cnblogs.com/LittleHann/p/3865490.html //搜索:0x1: struct file
0x2: 将文件作为通用接口(万物皆文件)
*nix似乎基于少量审慎选择的范型而建立的,一个非常重要的隐喻贯穿内核的始终(特别是VFS),尤其是在有关输入和输出机制的实现方面
大多数内核导出、用户程序使用的函数都可以通过(VFS)定义的文件接口访问,以下是使用文件作为其主要通信手段的一部分内核子系统
1. 字符和块设备 2. 进程之间的管道 3. 用于所有网络协议的套接字 4. 用户交互式输入和输出的终端
要注意的是,上述的某些对象不一定联系到文件系统中的某个项。例如,管道是通过特殊的系统调用生成,然后由内核中VFS的数据结构中管理,管道并不对应于一个可以用通常的rm、ls等命令访问的真正的文件系统项
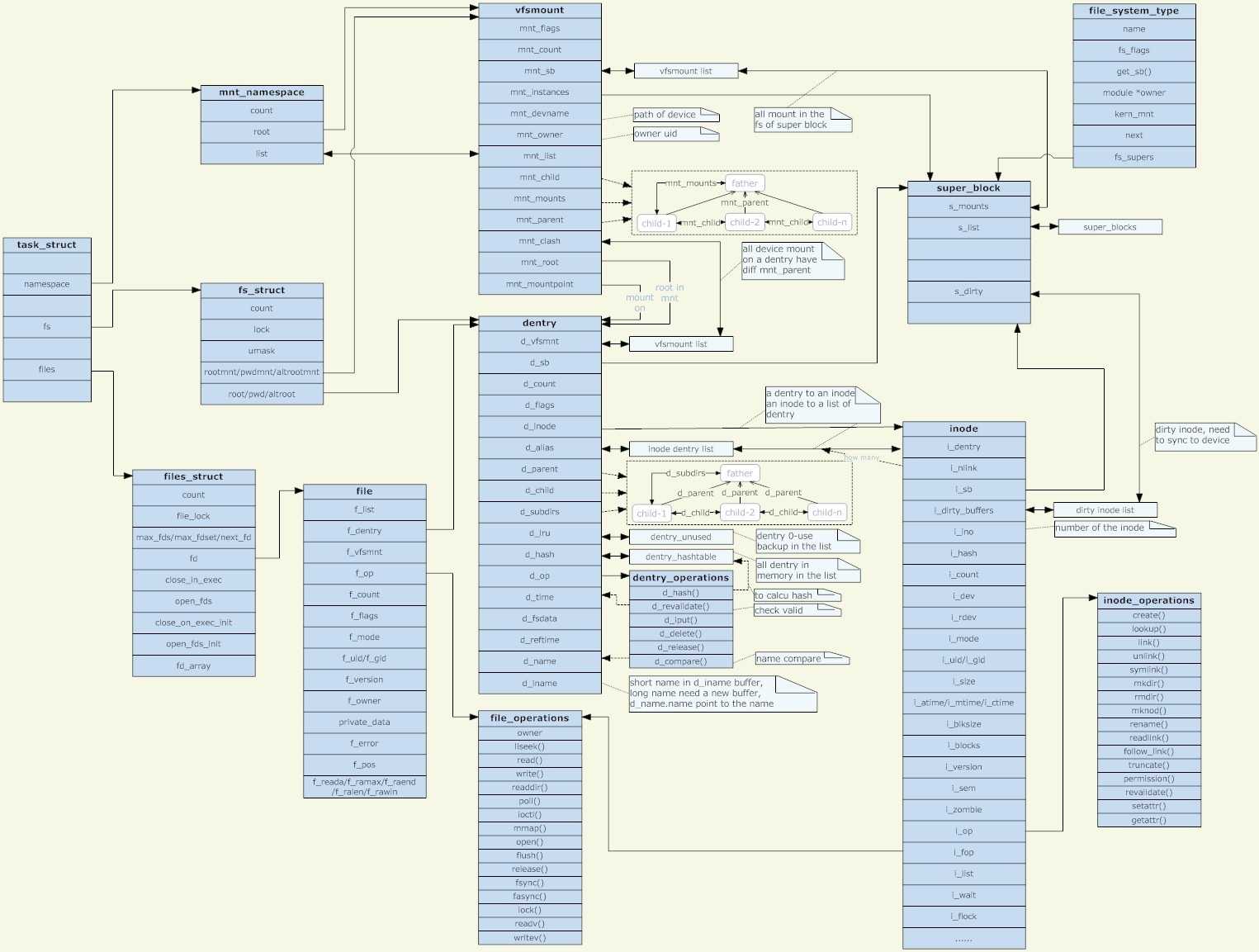
3. VFS相关数据结构
0x1: 结构概观
VFS由两个部分组成: 文件、文件系统,这些都需要管理和抽象
1. 文件的表示 inode是内核选择用于表示文件内容和相关元数据的方法,理论上,实现这个概念只需要一个大的数据结构,其中包含了所有必要的数据,但实际上,linux内核将数据结构分散到一些列较小的、布局清晰的结构中 在抽象对底层文件系统的访问时,并未使用固定的函数,而是使用了函数指针。这些函数指针保存在两个结构中,包括了所有相关的函数,因为实际数据是通过具体文件系统的实现操作的,调用接口总是保持不变,但实际的工作是由特定于实现的函数完成的 1) inode操作: "struct inode"->"const struct inode_operations *i_op" 特定于inode操作有关,负责管理结构性的操作,例如创建链接、文件重命名、在目录中生成新文件、删除文件 2) 文件操作: "struct file"->"const struct file_operations *f_op;" 特定于文件的数据内容的操作,它们包含一些常用的操作(如读和写)、设置文件位置指针、创建内存映射等操作 除此之外,还需要其他结构来保存与inode相关的信息,特别重要的是与每个inode关联的数据段,其中存储了文件的内容或目录项表。每个inode还包含了一个指向底层文件系统的超级快对象的指针(struct super_block *i_sb;),用于执行对inode本身的操作(这些操作也是通过函数指针数组实现的) 因为打开的文件总是分配到系统中的一个特定的进程,内核必须在数据结构中存储文件和进程之间的关联,我们知道,task_struct包含了一个成员,保存了所有打开的文件的一个数组 各个文件系统的实现也能在VFS inode中存储自身的数据(不通过VFS层操作) /* http://www.cnblogs.com/LittleHann/p/3865490.html 搜索:0x2: struct inode 搜索:0x1: struct file */ 2. 文件系统和超级块信息 VFS支持的文件系统类型通过一种特殊的内核对象连接进来,该对象提供了一种读取"超级块"的方法,除了文件系统的关键信息(块长度、最大文件长度、..),超级块还包含了读、写、操作inode的函数指针 内核还建立了一个链表,包含所有"活动"(active、或者称为"已装载(mounted)")文件系统的超级块实例 超级块结构的一个重要成员是一个列表,包括相关文件系统中所有修改过的inode(脏inode),根据该列表很容易标识已经修改过的文件和目录,以便将其写回到存储介质,回写必须经过协调,保证在一定程度上最小化开销 1) 因为这是一个非常费时的操作,硬盘、软盘驱动器及其他介质与系统其余组件相比,速度慢了几个数量级 2) 另一方面,如果写回修改数据的间隔时间太长也可能带来严重后果,因为系统崩溃(停电)会导致不能恢复的数据丢失 内核会周期性扫描脏块(dirty inode)的列表,并将修改传输(同步)到底层硬件 /* http://www.cnblogs.com/LittleHann/p/3865490.html 搜索:0x10: struct super_block */
值得注意的,inode和file结构体都包含了file_operations结构的指针,而inode还额外包含inode_operations结构指针
0x2: 特定于进程的信息
文件描述符(fd)用于在一个进程内唯一地标识打开的文件,这使得内核能够在用户进程中的描述符和内核内部使用的结构之间,建立一种关联
struct task_struct { ... /* 文件系统信息,整数成员link_count、total_link_count用于在查找环形链表时防止无限循环 */ int link_count, total_link_count; //用来表示进程与文件系统的联系,包括当前目录和根目录、以及chroot有关的信息 struct fs_struct *fs; //表示进程当前打开的文件 struct files_struct *files; //命名空间 strcut nsproxy *nsproxy; ... }
由于命名空间、容器的引入,从容器(container)角度看似"全局"的每个资源,都由内核包装起来,分别由每个容器进行管理,表现出一种虚拟的分组独立的概念。虚拟文件系统(VFS)同样也受此影响,因为各个容器可能装载点的不同导致不同的目录层次结构(即在不同命名空间中看到的目录结构不同),对应的信息包含在ns_proxy->mnt_namespacez中
关于命名空间的相关知识,请参阅另一篇文章
http://www.cnblogs.com/LittleHann/p/4026781.html //搜索:2. Linux命名空间
0x3: 文件操作
文件不能只存储信息,必须容许操作其中的信息。从用户的角度来看,文件操作由标准库的函数执行。这些函数指示内核执行体统调用(VFS提供的系统调用),然后VFS系统调用执行所需的操作,当然各个文件系统实现的接口可能不同,因而VFS层提供了抽象的操作,以便将通用文件对象与具体文件系统实现的底层机制关联起来
用于抽象文件操作的结构必须尽可能通用,以考虑到各种各样的目标文件。同时,它不能带有过多只适用于特定文件类型的专门操作。尽管如此,仍然必须满足各种文件(普通文件、设备文件、..)的特殊需求,以便充分利用。可见,VFS的数据机构是一个承上启下的关键层
各个file实例都包含一个指向struct file_operation实例的指针,该结构保存了指向所有可能文件操作的函数指针
如果一个对象使用这里给出的结构作为接口,那么并不必实现所有的操作,例如进程间管道只提供了少量的操作,因为剩余的操作根本没有意义,例如无法对管道读取目录内容,因此readdir对于管道文件是不可用的。有两种方法可以指定某个方法不可用
1. 将函数指针设置为NULL 2. 将函数指针指向一个占位函数,该函数直接返回错误值
0x4: VFS命名空间
我们知道,内核提供了实现容器的底层机制,单一的系统可以提供很多容器,但容器中的进程无法感知容器外部的情况,也无法得知所在容器有关的信息,容器彼此完全独立,从VFS的角度来看,这意味着需要针对每个容器分别跟踪装载的文件系统,单一的全局视图是不够的
VFS命名空间是所有已经装载的、构成某个容器目录树的文件系统的集合
通常调用fork、clone建立的进程会继承其父进程的命名空间(即默认情况,新进程和父进程会存在于同一个命名空间中),但可以设置CLONE_NEWNS标志,以建立一个新的VFS命名空间
关于VFS命名空间的相关知识,请参阅另一篇文章
http://www.cnblogs.com/LittleHann/p/3865490.html //搜索:0x3: struct nsproxy
命名空间操作(mount、umount)并不作用于内核的全局数据结构,而是操作当前命名空间的实例,可以通过task_strcut的同名成员访问,改变会影响命名空间的所有成员,因为一个命名空间中的所有进程共享同一个命名空间实例
0x5: 目录项缓存: dentry缓存
我们知道,若干dentry描绘了一个树型的目录结构(dentry树),这就是用户所看到的目录结构,每个dentry指向一个索引节点(inode)结构。然而,这些dentry结构并不是常驻内存的,因为整个目录结构可能会非常大,以致于内存根本装不下。Linux的处理方式为
1. 初始状态下: 系统中只有代表根目录的dentry和它所指向的inode 2. 当要打开一个文件: 文件路径中对应的节点都是不存在的,根目录的dentry无法找到需要的子节点(它现在还没有子节点),这时候就要通过inode->i_op中的lookup方法来寻找需要的inode的子节点,找到以后(此时inode已被载入内存),再创建一个dentry与之关联上
由这一过程可见,其实是先有inode再有dentry。inode本身是存在于文件系统的存储介质上的,而dentry则是在内存中生成的。dentry的存在加速了对inode的查询
每个dentry对象都属于下列几种状态之一
1. 未使用(unused)状态 该dentry对象的引用计数d_count的值为0,但其d_inode指针仍然指向相关的的索引节点。该目录项仍然包含有效的信息,只是当前没有人引用他。这种dentry对象在回收内存时可能会被释放 2. 正在使用(inuse)状态 处于该状态下的dentry对象的引用计数d_count大于0,且其d_inode指向相关的inode对象。这种dentry对象不能被释放 3. 负(negative)状态 与目录项(dentry)相关的inode对象不复存在(相应的磁盘索引节点可能已经被删除),dentry对象的d_inode指针为NULL。但这种dentry对象仍然保存在dcache中,以便后续对同一文件名的查找能够快速完成。这种dentry对象在回收内存时将首先被释放
为了提高目录项对象的处理效率,加速对重复的路径的访问,引入dentry cache(简称dcache),即目录项高速缓。它主要由两个数据结构组成:
1. 哈希链表(dentry_hashtable): 内存中所有活动的dentry实例在保存在一个散列表中,该散列表使用fs/dcache.c中的全局变量dentry_hashtable实现,dcache中的所有dentry对象都通过d_hash指针域链到相应的dentry哈希链表中。d_hash是一种溢出链,用于解决散列碰撞 2. 未使用的dentry对象链表(dentry_unused): 内核中还有另一个dentry链表,表头是全局变量dentry_unused(在fs/dcache.c中初始化) dcache中所有处于unused状态和negative状态的dentry对象都通过其d_lru指针域链入dentry_unused链表(super_block->s_dentry_lru)中。该链表也称为LRU链表 为了保证内存的充分利用,在内存中生成的dentry将在无人使用时被释放。d_count字段记录了dentry的引用计数,引用为0时,dentry将被释放。 这里的释放dentry并不是直接销毁并回收,而是将dentry放入目录项高速缓的LRU链表中(即dentry_unused指向的链表中)。当队列过大,或系统内存紧缺时,最近最少使用的一些dentry才真正被释放
目录项高速缓存dcache是索引节点缓存icache(inode cache)的主控器(master),即dcache中的dentry对象控制着icache中的inode对象的生命期转换。无论何时,只要一个目录项对象存在于dcache中(非negative状态),则相应的inode就将总是存在,因为inode的引用计数i_count总是大于0。当dcache中的一个dentry被释放时,针对相应inode对象的iput()方法就会被调用
当寻找一个文件路径时,对于其中经历的每一个节点,有三种情况:
1. 对应的dentry引用计数尚未减为0,它们还在dentry树中,直接使用即可 2. 如果对应的dentry不在dentry树中,则试图从LRU队列去寻找。LRU队列中的dentry同时被散列到一个散列表中,以便查找。查找到需要的dentry后,这个dentry被从LRU队列中拿出来,重新添加到dentry树中 3. 如果对应的dentry在LRU队列中也找不到,则只好去文件系统的存储介质里面查找inode了。找到以后dentry被创建,并添加以dentry树中
dentry结构不仅使得易于处理文件系统,对提高系统性能也很关键,它们通过最小化与底层文件系统实现的通信,加速了VFS的处理。每个由VFS发送到底层实现的请求,都会导致创建一个新的dentry对象,以保存请求的结果,这些对象保存在一个缓存中,在下一次需要时可以更快速地访问,这样操作就能够更快速地执行
0x6: dentry管理
关于struct dentry结构的相关知识,请参阅另一篇文章
http://www.cnblogs.com/LittleHann/p/3865490.html //搜索:0x7: struct dentry
各个dentry实例组成了一个网络(层次目录网络),与文件系统的结构形成一定的映射关系。在内核中需要获取有关文件的信息时,使用dentry对象很方便,dentry更多地体现了linux目录组织关系,但它不是表示文件及文件内容,这一职责分配给了inode,使用dentry对象很容易找到inode实例
Relevant Link:
http://blog.csdn.net/denzilxu/article/details/9188003 http://www.cnblogs.com/hzl6255/archive/2012/12/31/2840854.html
4. 处理VFS对象
0x1: 文件系统操作
尽管"文件操作"对所有应用程序来说都属于标准功能,但"文件系统操作"只限于少量几个系统程序,即用于装载和卸载文件系统的mount、unmount程序。同时还必须考虑到另一个重要的方面,即文件文件在内核中是以模块化形式实现的,这意味着可以将文件系统编译到内核中,而内核自身在编译时也完全可以限制不支持某个特定的文件系统。因此,每个文件系统在使用以前必须注册到内核,这样内核能够了解可用的文件系统,并按需调用装载功能(mount)
1. 注册文件系统
在文件系统注册到内核时,文件系统是编译为模块(LKM),或者持久编译到内核中,都没有差别。如果不考虑注册的时间(持久编译到内核的文件系统在启动时注册,模块化文件系统在相关模块载入内核时注册),在两种情况下所用的技术是同样的
\linux-2.6.32.63\fs\filesystems.c
/** * register_filesystem - register a new filesystem * @fs: the file system structure * * Adds the file system passed to the list of file systems the kernel * is aware of for mount and other syscalls. Returns 0 on success, * or a negative errno code on an error. * * The &struct file_system_type that is passed is linked into the kernel * structures and must not be freed until the file system has been * unregistered. */ int register_filesystem(struct file_system_type * fs) { int res = 0; struct file_system_type ** p; BUG_ON(strchr(fs->name, ‘.‘)); if (fs->next) return -EBUSY; //所有文件系统都保存在一个单链表中,各个文件系统的名称存储为字符串 INIT_LIST_HEAD(&fs->fs_supers); write_lock(&file_systems_lock); /* 在新的文件系统注册到内核时,将逐元素扫描该单链表 1. 到达链表尾部: 将描述新文件系统的对象置于链表末尾,完成了向内核的注册 2. 找到对应的文件系统: 返回一个适当的错误信息,表明一个文件系统不能被注册两次 */ p = find_filesystem(fs->name, strlen(fs->name)); if (*p) res = -EBUSY; else *p = fs; write_unlock(&file_systems_lock); return res; } EXPORT_SYMBOL(register_filesystem);
关于"struct file_system_type"的相关知识,请参阅另一篇文章
http://www.cnblogs.com/LittleHann/p/3865490.html //搜索:0x11: struct file_system_type
2. 装载和卸载
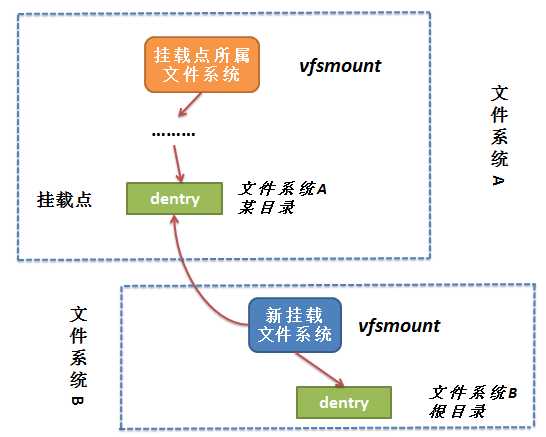
目录树的装载和卸载比仅仅注册文件系统要复杂得多,因为后者(注册文件系统)只需要向一个链表添加对象,而前者(目录树的装载和卸载)需要对内核的内部数据结构执行很多操作,所以要复杂得多。文件系统的装载由mount系统调用发起,在详细讨论各个步骤之前,我们需要阐明在现存目录树中装载新的文件系统必须执行的任务,我们还需要讨论用于描述装载点的数据结构
vfsmount结构
unix采用了一种单一的文件系统层次结构,新的文件系统可以集成到其中

使用mount指令可查询目录树中各种文件系统的装载情况
在这里例子中,/mnt和/cdrom目录被称为"装载点",因为这是附接(装载)文件系统的位置。每个装载的文件系统都有一个"本地根目录",其中包含了系统目录(例如对于cdrom这个装载点来说,它的系统目录就是src、libs)。在将文件系统装载到一个目录时,装载点的内容被替换为即将装载的文件系统的相对根目录的内容,前一个目录数据消失,直至新文件系统卸载才重新出现(在此期间旧文件系统的数据不会被改变,但是无法访问)
从这个例子中可以看到,装载是可以嵌套的,光盘装载在/mnt/cdrom目录中,这意味着ISO9660文件系统的相对根目录装载在一个reiser文件系统内部,因而与用作全局根目录的ext2文件系统是完全分离的
在内核其他部分常见的父子关系,也可以用于更好地描述两个文件系统之间的关系
1. ext2是/mnt中的reiserfs的父文件系统 2. /mnt/cdrom中包含的是/mnt的子文件系统,与根文件系统ext2
每个装载的文件系统都对应于一个vfsmount结构的实例,关于结构体定义的相关知识,请参阅另一篇文章
http://www.cnblogs.com/LittleHann/p/3865490.html //搜索:0x8: struct vfsmount
超级块管理
在装载新的文件系统时,vfsmount并不是唯一需要在内存中创建的结构,装载操作开始于超级块的读取。file_system_type对象中保存的read_super函数指针返回一个类型为super_block的对象,用于在内存中表示一个超级块,它是借助底层实现产生的
关于struct super_block的相关知识,请参阅另一篇文章
http://www.cnblogs.com/LittleHann/p/3865490.html 搜索:0x10: struct super_block
mount系统调用
mount系统调用的入口点是sys_mount函数,\linux-2.6.32.63\fs\namespace.c
SYSCALL_DEFINE5(mount, char __user *, dev_name, char __user *, dir_name, char __user *, type, unsigned long, flags, void __user *, data) { int ret; char *kernel_type; char *kernel_dir; char *kernel_dev; unsigned long data_page; /*从用户空间复制到系统空间*/ /* 以下几个函数将用户态参数拷贝至内核态,在后面需要使用这些参数,包括: 1. kernel_type: 挂载文件系统类型,如ext3 2. kernel_dir: 载点路径 3. dev_name: 设备名称 4. data_pages: 选项信息 */ ret = copy_mount_string(type, &kernel_type); if (ret < 0) goto out_type; kernel_dir = getname(dir_name); if (IS_ERR(kernel_dir)) { ret = PTR_ERR(kernel_dir); goto out_dir; } ret = copy_mount_string(dev_name, &kernel_dev); if (ret < 0) goto out_dev; /*用户空间复制到系统空间,拷贝整个页面*/ ret = copy_mount_options(data, &data_page); if (ret < 0) goto out_data; /*操作主体 调用do_mount 完成主要挂载工作*/ ret = do_mount(kernel_dev, kernel_dir, kernel_type, flags, (void *) data_page); free_page(data_page); out_data: kfree(kernel_dev); out_dev: putname(kernel_dir); out_dir: kfree(kernel_type); out_type: return ret; }

调用do_mount 完成主要挂载工作
long do_mount(char *dev_name, char *dir_name, char *type_page, unsigned long flags, void *data_page) { struct path path; int retval = 0; int mnt_flags = 0; /* Discard magic */ if ((flags & MS_MGC_MSK) == MS_MGC_VAL) flags &= ~MS_MGC_MSK; /* Basic sanity checks */ if (!dir_name || !*dir_name || !memchr(dir_name, 0, PAGE_SIZE)) return -EINVAL; if (data_page) ((char *)data_page)[PAGE_SIZE - 1] = 0; /* Default to relatime unless overriden */ if (!(flags & MS_NOATIME)) mnt_flags |= MNT_RELATIME; /* Separate the per-mountpoint flags */ if (flags & MS_NOSUID) mnt_flags |= MNT_NOSUID; if (flags & MS_NODEV) mnt_flags |= MNT_NODEV; if (flags & MS_NOEXEC) mnt_flags |= MNT_NOEXEC; if (flags & MS_NOATIME) mnt_flags |= MNT_NOATIME; if (flags & MS_NODIRATIME) mnt_flags |= MNT_NODIRATIME; if (flags & MS_STRICTATIME) mnt_flags &= ~(MNT_RELATIME | MNT_NOATIME); if (flags & MS_RDONLY) mnt_flags |= MNT_READONLY; flags &= ~(MS_NOSUID | MS_NOEXEC | MS_NODEV | MS_ACTIVE | MS_NOATIME | MS_NODIRATIME | MS_RELATIME| MS_KERNMOUNT | MS_STRICTATIME); /* ... and get the mountpoint */ /*获得安装点path结构,用kern_path(),根据挂载点名称查找其dentry等信息 */ retval = kern_path(dir_name, LOOKUP_FOLLOW, &path); if (retval) return retval; //LSM的hook挂载点 retval = security_sb_mount(dev_name, &path, type_page, flags, data_page); if (retval) goto dput_out; //对于挂载标志的检查和初始化 if (flags & MS_REMOUNT) //修改已经存在的文件系统参数,即改变超级块对象s_flags字段的安装标志 retval = do_remount(&path, flags & ~MS_REMOUNT, mnt_flags, data_page); else if (flags & MS_BIND) //要求在系统目录树的另一个安装点上得文件或目录能够可见 retval = do_loopback(&path, dev_name, flags & MS_REC); else if (flags & (MS_SHARED | MS_PRIVATE | MS_SLAVE | MS_UNBINDABLE)) retval = do_change_type(&path, flags); else if (flags & MS_MOVE) //改变已安装文件的安装点* retval = do_move_mount(&path, dev_name); else retval = do_new_mount(&path, type_page, flags, mnt_flags, dev_name, data_page); dput_out: path_put(&path); return retval; }
retval = do_new_mount(&path, type_page, flags, mnt_flags, dev_name, data_page);,该函数接手来完成接下来的挂载工作

static int do_new_mount(struct path *path, char *type, int flags, int mnt_flags, char *name, void *data) { struct vfsmount *mnt; if (!type) return -EINVAL; /* we need capabilities... 必须是root权限 */ if (!capable(CAP_SYS_ADMIN)) return -EPERM; lock_kernel(); /* 调用do_kern_mount()来完成挂载第一步 1. 处理实际的安装操作并返回一个新的安装文件系统描述符地址 2. 使用get_fs_type()辅助函数扫描已经注册文件系统链表,找到匹配的file_system_type实例,该辅助函数扫描已注册文件系统的链表,返回正确的项。如果没有找到匹配的文件系统,该例程就自动加载对应的模块 3. 调用vfs_kern_mount用以调用特定于文件系统的get_sb函数读取sb结构(超级块),并与mnt关联,初始化mnt并返回 */ mnt = do_kern_mount(type, flags, name, data); unlock_kernel(); if (IS_ERR(mnt)) return PTR_ERR(mnt); /* do_add_mount处理一些必须的锁定操作,并确保一个文件系统不会重复装载到同一位置,并将创建的vfsmount结构添加到全局结构中,以便在内存中形成一棵树结构 */ return do_add_mount(mnt, path, mnt_flags, NULL); }
调用do_kern_mount()来完成挂载第一步
struct vfsmount * do_kern_mount(const char *fstype, int flags, const char *name, void *data) { /* 首先根据文件系统名称获取文件系统结构file_system_type 内核中所有支持的文件系统的该结构通过链表保存 */ struct file_system_type *type = get_fs_type(fstype); struct vfsmount *mnt; if (!type) return ERR_PTR(-ENODEV); /* 调用vfs_kern_mount()完成主要挂载 1. 分配一个代表挂载结构的struct vfs_mount结构 2. 调用具体文件系统的get_sb方法,从name代表的设备上读出超级块信息 3. 设置挂载点的dentry结构为刚读出的设备的根目录 */ mnt = vfs_kern_mount(type, flags, name, data); if (!IS_ERR(mnt) && (type->fs_flags & FS_HAS_SUBTYPE) && !mnt->mnt_sb->s_subtype) mnt = fs_set_subtype(mnt, fstype); put_filesystem(type); return mnt; } EXPORT_SYMBOL_GPL(do_kern_mount);
至此,我们第一部分的主要工作就完成了,在该部分的核心工作就是创建一个struct vfsmount,并读出文件系统超级块来初始化该结构。接下来就是将该结构添加到全局结构中,这就是do_add_mount()的主要工作,真正的挂载过程在函数do_add_mount()中完成
int do_add_mount(struct vfsmount *newmnt, struct path *path, int mnt_flags, struct list_head *fslist) { int err; down_write(&namespace_sem); /* Something was mounted here while we slept 如果在获取信号量的过程中别人已经进行了挂载,那么我们进入已挂载文件系统的根目录 */ while (d_mountpoint(path->dentry) && follow_down(path)) ; err = -EINVAL; if (!(mnt_flags & MNT_SHRINKABLE) && !check_mnt(path->mnt)) goto unlock; /* Refuse the same filesystem on the same mount point */ err = -EBUSY; if (path->mnt->mnt_sb == newmnt->mnt_sb && path->mnt->mnt_root == path->dentry) goto unlock; err = -EINVAL; if (S_ISLNK(newmnt->mnt_root->d_inode->i_mode)) goto unlock; newmnt->mnt_flags = mnt_flags; /* 调用graft_tree()来实现文件系统目录树结构,其中newmnt是本次创建的vfsmount结构,path是挂载点信息 */ if ((err = graft_tree(newmnt, path))) goto unlock; if (fslist) /* add to the specified expiration list */ list_add_tail(&newmnt->mnt_expire, fslist); up_write(&namespace_sem); return 0; unlock: up_write(&namespace_sem); mntput(newmnt); return err; } EXPORT_SYMBOL_GPL(do_add_mount);
主要是将当前新建的vfsmount结构与挂载点挂钩,并和挂载点所在的vfsmount形成一种父子关系结构。形成的结构图如下所示
至此,整个mount过程分析完毕

Relevant Link:
http://blog.csdn.net/kai_ding/article/details/9050429 http://blog.csdn.net/ding_kai/article/details/7106973 http://www.2cto.com/os/201202/119141.html
共享子树
unmount系统调用
自动过期
伪文件系统
文件系统未必需要底层块设备支持,它们可以使用内存作为后备存储器(如ramfs、tmpfs),或者根本不需要后备存储器(如procfs、sysfs),其内容是从内核数据结构包含的信息生成的。伪文件系统的例子包括
1. 负责管理表示块设备的inode的bdev 2. 处理管道的pipefs 3. 处理套接字的sockfs
所有这些都出现在/proc/filesystems中,但不能装载,内核提供了装载标志"MS_NOUSER",防止此类文件系统被装载,伪文件系统的加载和卸载都和普通文件系统都调用同一套函数API。内核可以使用kern_mount、kern_mount_data装载一个伪文件系统,最后调用vfs_kern_mount,将文件系统数据集成到VFS数据结构中。
在从用户层装载一个文件系统时,只有do_kern_mount并不够,还需要将文件和目录集成到用户可见的空间中,该工作由graft_tree处理,但如果设置了MS_NOUSER,则graft_tree拒绝工作
static int graft_tree(struct vfsmount *mnt, struct path *path) { int err; if (mnt->mnt_sb->s_flags & MS_NOUSER) return -EINVAL; ... }
需要明白的是,伪文件系统的结构内容对内核都是可用的,文件系统库提供了一些方法,可以用于向伪文件系统写入数据
0x2: 文件操作
操作整个文件系统是VFS的一个重要方面,但相对而言很少发生,因为除了可移动设备之外,文件系统都是在启动过程中装载,在关机时卸载。更常见的是对文件的频繁操作,所有系统进程都需要执行此类操作
为容许对文件的通用存取,而无需考虑所用的文件系统,VFS以各种系统调用的形式提供了用于文件处理的接口函数
1. 查找inode
一个主要操作是根据给定的文件名查找inode,nameidata结构用来向查找函数传递参数,并保存查找结果
有关struct nameidata的相关知识,请参阅另一篇文章
http://www.cnblogs.com/LittleHann/p/3865490.html //搜索:0x9: struct nameidata
内核使用path_lookup函数查找路径或文件名
\linux-2.6.32.63\fs\namei.c
/* Returns 0 and nd will be valid on success; Retuns error, otherwise. 除了所需的名称name和查找标志flags之外,该函数需要一个指向nameidata实例的指针,用作临时结果的"暂存器" */ static int do_path_lookup(int dfd, const char *name, unsigned int flags, struct nameidata *nd) { //内核使用nameidata实例规定查找的起点,如果名称以/开始,则使用当前根目录的dentry和vfsmount实例(要考虑到chroot情况),否则从当前进程的task_struct获得当前工作目录的数据 int retval = path_init(dfd, name, flags, nd); if (!retval) { retval = path_walk(name, nd); } if (unlikely(!retval && !audit_dummy_context() && nd->path.dentry && nd->path.dentry->d_inode)) { audit_inode(name, nd->path.dentry); } if (nd->root.mnt) { path_put(&nd->root); nd->root.mnt = NULL; } return retval; } int path_lookup(const char *name, unsigned int flags, struct nameidata *nd) { return do_path_lookup(AT_FDCWD, name, flags, nd); }
其中的核心path_walk()的流程是一个不断穿过目录层次的过程,逐分量处理文件名或路径名,名称在循环内部分解为各个分量(通过一个或多个斜线分隔),每个分量表示一个目录名,最后一个分量例外,总是文件名
static int path_walk(const char *name, struct nameidata *nd) { current->total_link_count = 0; return link_path_walk(name, nd); } /* * Wrapper to retry pathname resolution whenever the underlying * file system returns an ESTALE. * * Retry the whole path once, forcing real lookup requests * instead of relying on the dcache. */ static __always_inline int link_path_walk(const char *name, struct nameidata *nd) { struct path save = nd->path; int result; /* make sure the stuff we saved doesn‘t go away */ path_get(&save); result = __link_path_walk(name, nd); if (result == -ESTALE) { /* nd->path had been dropped */ nd->path = save; path_get(&nd->path); nd->flags |= LOOKUP_REVAL; result = __link_path_walk(name, nd); } path_put(&save); return result; } static int __link_path_walk(const char *name, struct nameidata *nd) { struct path next; struct inode *inode; int err; unsigned int lookup_flags = nd->flags; while (*name==‘/‘) name++; if (!*name) goto return_reval; inode = nd->path.dentry->d_inode; if (nd->depth) lookup_flags = LOOKUP_FOLLOW | (nd->flags & LOOKUP_CONTINUE); /* At this point we know we have a real path component. */ for(;;) { unsigned long hash; struct qstr this; unsigned int c; nd->flags |= LOOKUP_CONTINUE; /* 检查权限 */ err = exec_permission_lite(inode); if (err) break; this.name = name; c = *(const unsigned char *)name; //计算路径中下一个部分的散列值 hash = init_name_hash(); do { name++; //路径分量的每个字符都传递给partial_name_hash,用于计算一个递增的散列和,当路径分量的所有字符都已经计算,则将该散列和转换为最后的散列值,并保存到一个qstr中 hash = partial_name_hash(c, hash); c = *(const unsigned char *)name; } while (c && (c != ‘/‘)); this.len = name - (const char *) this.name; this.hash = end_name_hash(hash); /* remove trailing slashes? */ if (!c) goto last_component; while (*++name == ‘/‘); if (!*name) goto last_with_slashes; /* * "." and ".." are special - ".." especially so because it has * to be able to know about the current root directory and * parent relationships. */ if (this.name[0] == ‘.‘) switch (this.len) { default: break; case 2: if (this.name[1] != ‘.‘) break; /* 如果路径分量中出现两个点(..) 1. 当查找操作处理进程的根目录时,没有效果,因为根目录是没有父母了的 2. 如果当前目录不是一个装载点的根目录,则将当前dentry对象的d_parent成员用作新的目录,因为它总是表示父目录 3. 如果当前目录是一个已装载文件系统的根目录,保存在mnt_mountpoint和mnt_parent中的信息用于定义新的dentry和vfsmount对象 */ follow_dotdot(nd); inode = nd->path.dentry->d_inode; /* fallthrough */ case 1: continue; } /* * See if the low-level filesystem might want * to use its own hash.. */ if (nd->path.dentry->d_op && nd->path.dentry->d_op->d_hash) { err = nd->path.dentry->d_op->d_hash(nd->path.dentry, &this); if (err < 0) break; } /* This does the actual lookups.. 如果路径分量是一个普通文件,则内核可以通过两种方法查找对应的dentry实例(以及对应的inode) 1. 位于dentry cache中,访问它仅需很小的延迟 2. 需要通过文件系统底层实现进行查找 */ err = do_lookup(nd, &this, &next); if (err) break; err = -ENOENT; inode = next.dentry->d_inode; if (!inode) goto out_dput; /* 处理路径的最后一步是内核判断该分量是否为符号链接look */ if (inode->i_op->follow_link) { err = do_follow_link(&next, nd); if (err) goto return_err; err = -ENOENT; inode = nd->path.dentry->d_inode; if (!inode) break; } else path_to_nameidata(&next, nd); err = -ENOTDIR; if (!inode->i_op->lookup) break; continue; /* here ends the main loop */ last_with_slashes: lookup_flags |= LOOKUP_FOLLOW | LOOKUP_DIRECTORY; last_component: /* Clear LOOKUP_CONTINUE iff it was previously unset */ nd->flags &= lookup_flags | ~LOOKUP_CONTINUE; if (lookup_flags & LOOKUP_PARENT) goto lookup_parent; if (this.name[0] == ‘.‘) switch (this.len) { default: break; case 2: if (this.name[1] != ‘.‘) break; follow_dotdot(nd); inode = nd->path.dentry->d_inode; /* fallthrough */ case 1: goto return_reval; } if (nd->path.dentry->d_op && nd->path.dentry->d_op->d_hash) { err = nd->path.dentry->d_op->d_hash(nd->path.dentry, &this); if (err < 0) break; } err = do_lookup(nd, &this, &next); if (err) break; inode = next.dentry->d_inode; if (follow_on_final(inode, lookup_flags)) { err = do_follow_link(&next, nd); if (err) goto return_err; inode = nd->path.dentry->d_inode; } else path_to_nameidata(&next, nd); err = -ENOENT; if (!inode) break; if (lookup_flags & LOOKUP_DIRECTORY) { err = -ENOTDIR; if (!inode->i_op->lookup) break; } goto return_base; lookup_parent: nd->last = this; nd->last_type = LAST_NORM; if (this.name[0] != ‘.‘) goto return_base; if (this.len == 1) nd->last_type = LAST_DOT; else if (this.len == 2 && this.name[1] == ‘.‘) nd->last_type = LAST_DOTDOT; else goto return_base; return_reval: /* * We bypassed the ordinary revalidation routines. * We may need to check the cached dentry for staleness. */ if (nd->path.dentry && nd->path.dentry->d_sb && (nd->path.dentry->d_sb->s_type->fs_flags & FS_REVAL_DOT)) { err = -ESTALE; /* Note: we do not d_invalidate() */ if (!nd->path.dentry->d_op->d_revalidate( nd->path.dentry, nd)) break; } return_base: return 0; out_dput: path_put_conditional(&next, nd); break; } path_put(&nd->path); return_err: return err; } static int exec_permission_lite(struct inode *inode) { int ret; /* 判断inode是否定义了permission方法 */ if (inode->i_op->permission) { ret = inode->i_op->permission(inode, MAY_EXEC); if (!ret) goto ok; return ret; } ret = acl_permission_check(inode, MAY_EXEC, inode->i_op->check_acl); if (!ret) goto ok; if (capable(CAP_DAC_OVERRIDE) || capable(CAP_DAC_READ_SEARCH)) goto ok; return ret; ok: //LSM hook挂载点 return security_inode_permission(inode, MAY_EXEC); }
循环一直重复下去,直至到达文件名的末尾,如果内核发现文件名不再出现,则确认已经到达文件名末尾
do_lookup起始于一个路径分量,并且包含最初目录数据的nameidata实例,最终返回与之相关的inode
1. 内核首先试图在dentry缓存中查找inode,使用__d_lookup函数,找到匹配的数据,并不意味着它是最新的,必须调用底层文件系统的dentry_operation中的d_revalidate函数,来检查缓存项是否仍然有效 1) 如果有效: 则将其作为缓存搜索的结果返回 2) 如果无效: 必须在底层文件系统中发起一个查找操作 如果缓存没有找到,也必须在底层文件系统中发起一个查找操作,即在内存中建立dentry结构
do_follow_link,在内核跟踪符号链接时,它必须要注意死循环符号链接的可能性
static inline int do_follow_link(struct path *path, struct nameidata *nd) { //检查链接限制 int err = -ELOOP; if (current->link_count >= MAX_NESTED_LINKS) goto loop; if (current->total_link_count >= 40) goto loop; BUG_ON(nd->depth >= MAX_NESTED_LINKS); cond_resched(); err = security_inode_follow_link(path->dentry, nd); if (err) goto loop; current->link_count++; current->total_link_count++; nd->depth++; err = __do_follow_link(path, nd); current->link_count--; nd->depth--; return err; loop: path_put_conditional(path, nd); path_put(&nd->path); return err; }
task_struct结构包含两个计数变量,用于跟踪连接
strcut task_struct { .. //link_count用于防止递归循环 int link_count; //total_link_count限制路径名中连接的最大数目 int total_link_count; .. }
2. 打开文件
在读写文件之前,必须先打开文件,从应用程序的角度来看,这是通过标准库的open函数完成的,该函数返回一个文件描述符。该函数使用了同名的open()系统调用
\linux-2.6.32.63\fs\open.c
SYSCALL_DEFINE3(open, const char __user *, filename, int, flags, int, mode) { long ret; /* 检查是否应该不考虑用户层传递的标志,总是强行设置O_LARGEFILE。如果底层处理器字长是64位系统,就需要设置这个选项 */ if (force_o_largefile()) { flags |= O_LARGEFILE; } //调用do_sys_open完成实际功能 ret = do_sys_open(AT_FDCWD, filename, flags, mode); /* avoid REGPARM breakage on x86: */ asmlinkage_protect(3, ret, filename, flags, mode); return ret; } long do_sys_open(int dfd, const char __user *filename, int flags, int mode) { /*获取文件名称,由getname()函数完成,其内部首先创建存取文件名称的空间,然后从用户空间把文件名拷贝过来*/ char *tmp = getname(filename); int fd = PTR_ERR(tmp); if (!IS_ERR(tmp)) { /* 在内核中,每个打开的文件由一个文件描述符表示,该描述符在特定于进程的数组中充当位置索引(task_strcut->files->fd_array),该数组的元素包含了file结构,其中包含了每个打开文件所有必要的信息 获取一个可用的fd,此函数调用alloc_fd()函数从fd_table中获取一个可用fd,并进行初始化 */ fd = get_unused_fd_flags(flags); if (fd >= 0) { /*fd获取成功则开始打开文件,此函数是主要完成打开功能的函数,用于获取对应文件的inode*/ struct file *f = do_filp_open(dfd, tmp, flags, mode, 0); if (IS_ERR(f)) { /*打开失败,释放fd*/ put_unused_fd(fd); fd = PTR_ERR(f); } else { //文件如果已经被打开了,调用fsnotify_open()函数 fsnotify_open(f->f_path.dentry); //将文件指针安装在fd数组中,每个进程都会将打开的文件句柄保存在fd_array[]数组中 fd_install(fd, f); } } //释放放置从用户空间拷贝过来的文件名的存储空间 putname(tmp); } return fd; }
do_filp_open完成查找文件inode的主要工作
struct file *do_filp_open(int dfd, const char *pathname, int open_flag, int mode, int acc_mode) { /* 若干变量声明 */ struct file *filp; struct nameidata nd; int error; struct path path; struct dentry *dir; int count = 0; int will_write; /*改变参数flag的值,具体做法是flag+1*/ int flag = open_to_namei_flags(open_flag); /*设置访问权限*/ if (!acc_mode) { acc_mode = MAY_OPEN | ACC_MODE(flag); } /* O_TRUNC implies we need access checks for write permissions */ /* 根据O_TRUNC标志设置写权限 */ if (flag & O_TRUNC) { acc_mode |= MAY_WRITE; } /* Allow the LSM permission hook to distinguish append access from general write access. */ /* 设置O_APPEND标志 */ if (flag & O_APPEND) { acc_mode |= MAY_APPEND; } /* The simplest case - just a plain lookup. */ /* 如果不是创建文件 */ if (!(flag & O_CREAT)) { /* 当内核要访问一个文件的时候,第一步要做的是找到这个文件,而查找文件的过程在vfs里面是由path_lookup或者path_lookup_open函数来完成的 这两个函数将用户传进来的字符串表示的文件路径转换成一个dentry结构,并建立好相应的inode和file结构,将指向file的描述符返回用户 用户随后通过文件描述符,来访问这些数据结构 */ error = path_lookup_open(dfd, pathname, lookup_flags(flag), &nd, flag); if (error) { return ERR_PTR(error); } goto ok; } /* * Create - we need to know the parent. */ //path-init为查找作准备工作,path_walk真正上路查找,这两个函数联合起来根据一段路径名找到对应的dentry error = path_init(dfd, pathname, LOOKUP_PARENT, &nd); if (error) { return ERR_PTR(error); } /* 这个函数相当重要,是整个NFS的名字解析函数,其实也是NFS得以构筑的函数 该函数采用一个for循环,对name路径根据目录的层次,一层一层推进,直到终点或失败。在推进的过程中,一步步建立了目录树的dentry和对应的inode */ error = path_walk(pathname, &nd); if (error) { if (nd.root.mnt) { /*减少dentry和vsmount得计数*/ path_put(&nd.root); } return ERR_PTR(error); } if (unlikely(!audit_dummy_context())) { /*保存inode节点信息*/ audit_inode(pathname, nd.path.dentry); } /* * We have the parent and last component. First of all, check * that we are not asked to creat(2) an obvious directory - that * will not do. */ error = -EISDIR; /*父节点信息*/ if (nd.last_type != LAST_NORM || nd.last.name[nd.last.len]) { goto exit_parent; } error = -ENFILE; /* 返回特定的file结构体指针 */ filp = get_empty_filp(); if (filp == NULL) { goto exit_parent; } /* 填充nameidata结构 */ nd.intent.open.file = filp; nd.intent.open.flags = flag; nd.intent.open.create_mode = mode; dir = nd.path.dentry; nd.flags &= ~LOOKUP_PARENT; nd.flags |= LOOKUP_CREATE | LOOKUP_OPEN; if (flag & O_EXCL) { nd.flags |= LOOKUP_EXCL; } mutex_lock(&dir->d_inode->i_mutex); /*从哈希表中查找nd对应的dentry*/ path.dentry = lookup_hash(&nd); path.mnt = nd.path.mnt; do_last: error = PTR_ERR(path.dentry); if (IS_ERR(path.dentry)) { mutex_unlock(&dir->d_inode->i_mutex); goto exit; } if (IS_ERR(nd.intent.open.file)) { error = PTR_ERR(nd.intent.open.file); goto exit_mutex_unlock; } /* Negative dentry, just create the file */ /*如果此dentry结构没有对应的inode节点,说明是无效的,应该创建文件节点 */ if (!path.dentry->d_inode) { /* * This write is needed to ensure that a * ro->rw transition does not occur between * the time when the file is created and when * a permanent write count is taken through * the ‘struct file‘ in nameidata_to_filp(). */ /*write权限是必需的*/ error = mnt_want_write(nd.path.mnt); if (error) { goto exit_mutex_unlock; } /*按照namei格式的flag open*/ error = __open_namei_create(&nd, &path, flag, mode); if (error) { mnt_drop_write(nd.path.mnt); goto exit; } /*根据nameidata 得到相应的file结构*/ filp = nameidata_to_filp(&nd, open_flag); if (IS_ERR(filp)) { ima_counts_put(&nd.path, acc_mode & (MAY_READ | MAY_WRITE | MAY_EXEC)); } /*放弃写权限*/ mnt_drop_write(nd.path.mnt); if (nd.root.mnt) { /*计数减一*/ path_put(&nd.root); } return filp; } /* * It already exists. */ /*要打开的文件已经存在*/ mutex_unlock(&dir->d_inode->i_mutex); /*保存inode节点*/ audit_inode(pathname, path.dentry); error = -EEXIST; /*flag标志检查代码*/ if (flag & O_EXCL) { goto exit_dput; } if (__follow_mount(&path)) { error = -ELOOP; if (flag & O_NOFOLLOW) { goto exit_dput; } } error = -ENOENT; if (!path.dentry->d_inode) { goto exit_dput; } if (path.dentry->d_inode->i_op->follow_link) { goto do_link; } /*路径装化为相应的nameidata结构*/ path_to_nameidata(&path, &nd); error = -EISDIR; /*如果是文件夹*/ if (path.dentry->d_inode && S_ISDIR(path.dentry->d_inode->i_mode)) { goto exit; } ok: /* * Consider: * 1. may_open() truncates a file * 2. a rw->ro mount transition occurs * 3. nameidata_to_filp() fails due to * the ro mount. * That would be inconsistent, and should * be avoided. Taking this mnt write here * ensures that (2) can not occur. */ /*检测是否截断文件标志*/ will_write = open_will_write_to_fs(flag, nd.path.dentry->d_inode); if (will_write) { /*要截断的话就要获取写权限*/ error = mnt_want_write(nd.path.mnt); if (error) { goto exit; } } //may_open执行权限检测、文件打开和truncate的操作 error = may_open(&nd.path, acc_mode, flag); if (error) { if (will_write) { mnt_drop_write(nd.path.mnt); } goto exit; } filp = nameidata_to_filp(&nd, open_flag); if (IS_ERR(filp)) { ima_counts_put(&nd.path, acc_mode & (MAY_READ | MAY_WRITE | MAY_EXEC)); } /* * It is now safe to drop the mnt write * because the filp has had a write taken * on its behalf. */ //安全的放弃写权限 if (will_write) { mnt_drop_write(nd.path.mnt); } if (nd.root.mnt) { path_put(&nd.root); } return filp; exit_mutex_unlock: mutex_unlock(&dir->d_inode->i_mutex); exit_dput: path_put_conditional(&path, &nd); exit: if (!IS_ERR(nd.intent.open.file)) { release_open_intent(&nd); } exit_parent: if (nd.root.mnt) { path_put(&nd.root); } path_put(&nd.path); return ERR_PTR(error); do_link: //允许遍历连接文件,则手工找到连接文件对应的文件 error = -ELOOP; if (flag & O_NOFOLLOW) { //不允许遍历连接文件,返回错误 goto exit_dput; } /* * This is subtle. Instead of calling do_follow_link() we do the * thing by hands. The reason is that this way we have zero link_count * and path_walk() (called from ->follow_link) honoring LOOKUP_PARENT. * After that we have the parent and last component, i.e. * we are in the same situation as after the first path_walk(). * Well, almost - if the last component is normal we get its copy * stored in nd->last.name and we will have to putname() it when we * are done. Procfs-like symlinks just set LAST_BIND. */ /* 以下是手工找到链接文件对应的文件dentry结构代码 */ //设置查找LOOKUP_PARENT标志 nd.flags |= LOOKUP_PARENT; //判断操作是否安全 error = security_inode_follow_link(path.dentry, &nd); if (error) { goto exit_dput; } //处理符号链接 error = __do_follow_link(&path, &nd); if (error) { /* Does someone understand code flow here? Or it is only * me so stupid? Anathema to whoever designed this non-sense * with "intent.open". */ release_open_intent(&nd); if (nd.root.mnt) { path_put(&nd.root); } return ERR_PTR(error); } nd.flags &= ~LOOKUP_PARENT; //检查最后一段文件或目录名的属性情况 if (nd.last_type == LAST_BIND) { goto ok; } error = -EISDIR; if (nd.last_type != LAST_NORM) { goto exit; } if (nd.last.name[nd.last.len]) { __putname(nd.last.name); goto exit; } error = -ELOOP; //出现回环标志: 循环超过32次 if (count++==32) { __putname(nd.last.name); goto exit; } dir = nd.path.dentry; mutex_lock(&dir->d_inode->i_mutex); //更新路径的挂接点和dentry path.dentry = lookup_hash(&nd); path.mnt = nd.path.mnt; __putname(nd.last.name); goto do_last; }
接下来,将控制权返回用户进程,返回文件描述符之前,fd_install必须将file实例放置到进程task_struct的files_fd数组中
3. 读取和写入
在文件成功打开后,进程将使用内核提供的read或write系统调用,来读取或修改文件的数据,入口例程是sys_read、sys_write

读写数据涉及到一个复杂的缓冲区和缓存系统,这些用于提供系统性能
5. 标准函数
0x1: 通用读取例程
0x2: 失效机制
0x3: 权限检查
Copyright (c) 2014 LittleHann All rights reserved
标签:
原文地址:http://www.cnblogs.com/LittleHann/p/4305892.html