标签:
原文地址:http://www.redblobgames.com/pathfinding/a-star/introduction.html
如果想尝试文中的小程序,请点击上述链接,找到对应画面即可。
在游戏中我们想要找到从一个位置到另一个位置的路径。我们不仅尝试着找到最短距离的路径;我们还想要顾忌到消耗的时间。在一张地图上,穿过一片池塘速度会明显减慢,所以我们想要找到一条如果可以的话,绕过水路的路径。这是一个互动的图。在地图上单击去通过地面,草地,沙滩,水池以及墙/树。
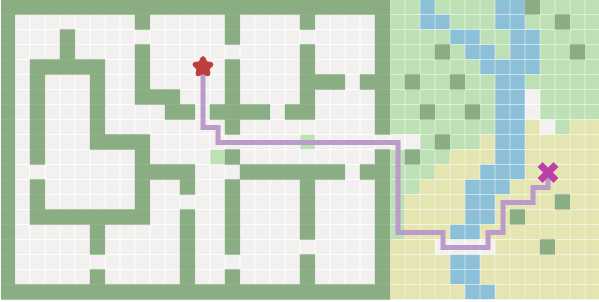
如何去计算这样一条路径呢?A*算法在游戏领域是最常见的算法。它是图形搜索算法家族中遵循相同结构的一员。这些算法的特征是:地图化作一张图结构,然后在图中查找路径。如果你之前不了解节点-边缘结构的图的话,这里是我的介绍性文章(http://www.redblobgames.com/pathfinding/grids/graphs.html)。在这个文章中,图节点将定位在地图中。广度优先算法是一种最简单的图搜索算法,所以我们就从它开始,然后以我们的方式讲述A*。
这些算法的关键思想是:我们跟踪一个叫做前驱的扩张圈。开始这个动画去观看前驱如何扩张。
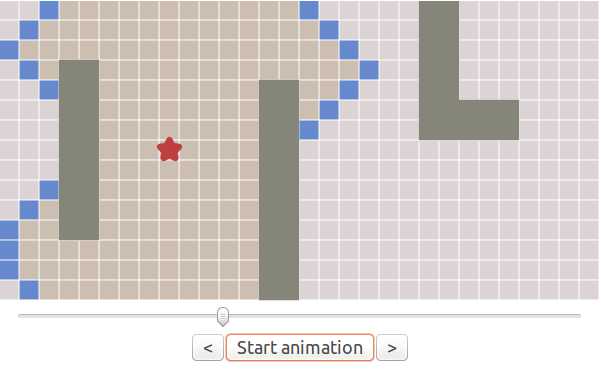
The expanding frontier can be viewed as contour lines that stop at walls; this process is sometimes called “flood fill”:
这个扩张的前驱可以被看做是一个停在墙边的等高线;这个过程有时候也被称为“泛洪填充”(用词不当,多多见谅)。

我们该怎样去实现这个算法呢?重复这些步骤知道“前驱frontier”为空:
1.从前驱中挑选并且移除一个位置;
2.为访问过的位置打上标志,让我们可以知道以后不会再去访问这个重复的节点。
3.通过它的邻居节点来扩张它。任何一个我们没有访问过的节点添加到前驱节点序列中。
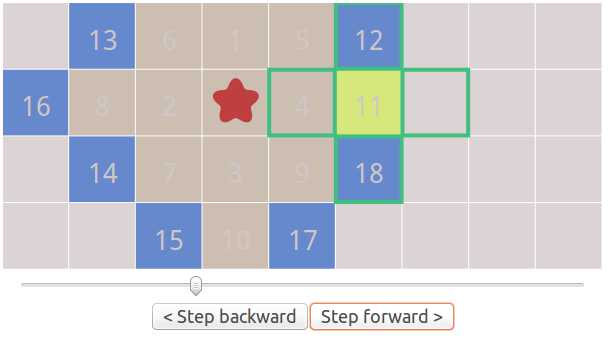
让我们来仔细的看看这个过程。这些区块被按照我们访问的顺去来排列序号。一步一步前进来观察这个过程:
python写的该算法只有10行(如下所示):
frontier = Queue()
frontier.put(start)
visited = {}
visited[start] = True
while not frontier.empty():
current = frontier.get()
for next in graph.neighbors(current):
if next not in visited:
frontier.put(next)
visited[next] = True
程序中的这个循环结构是这个网页中的图形搜索算法中的本质,也包括A*算法。但是我们怎样才能找到最短的路径呢?这个循环事实上不能构造出这样的路径;它仅仅告诉我们怎么去访问图中的每一个节点。那是因为广度优先搜索算法能够被用在更多的地方,而不仅仅是搜索路径;再这篇文章中我展示了它是如何应用在塔防游戏中的,但是它也可以被用在距离地图以及程序地图生成中,以及大量的其他方面。这里,虽然我们想要使用它去查找路径,所以,让我们来修改这个循环(跟踪我们过来时访问过的每一个位置,并且为这些之前走过的节点打上visited标志):
frontier = Queue()
frontier.put(start)
came_from = {}
came_from[start] = None
while not frontier.empty():
current = frontier.get()
for next in graph.neighbors(current):
if next not in came_from:
frontier.put(next)
came_from[next] = current
构造这条路径的代码也是非常简单:
current = goal
path = [current]
while current != start:
current = came_from[current]
path.append(current)
那就是最简单的路径查找算法。它不仅可以实现在网格中的路径查找,也可以应用在任何图结构序列上。在一个地下城中,图形位置可能是房间和图形边沿之间的门道。
在一个平台游戏中,图形位置可能是位置和图形边缘的可能的操作,如左移,右移,跳起来,跳下去。在一般情况下,认为图作为状态和改变状态的行动。
我有更多的写了地图表示在这里(http://theory.stanford.edu/~amitp/GameProgramming/MapRepresentations.html)。
在本文的其余部分,我会继续使用有网格的例子,并探讨为什么你可能会使用广度优先搜索的变种。
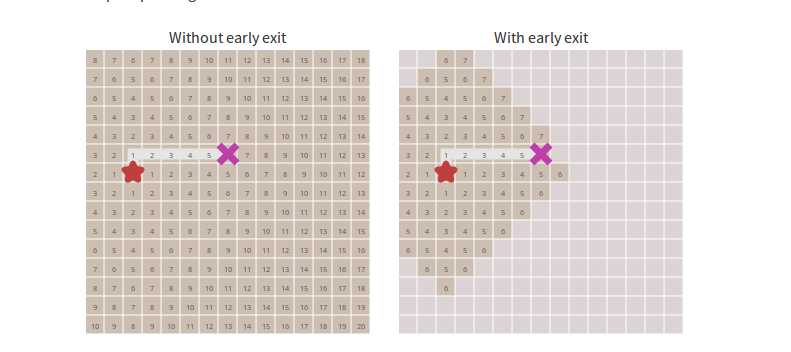
We’ve found paths from one location to all other locations. Often we don’t need all the paths; we only need a path from one location to one other location. We can stop expanding the frontier as soon as we’ve found our goal. Drag the X around see how the frontier stops expanding as soon as it reaches the X.
我们已经找出了从一个位置到另一个位置的路径。通常我们不需要所有的路径;我们只需要其中的一条路经。我们只要尽可能快的找到我们的目标,就可以停止扩张这个“前驱”。四处拖拽X,并且观看前驱是如何在到达X处 立刻停止扩张的。
frontier = Queue()
frontier.put(start)
came_from = {}
came_from[start] = None
while not frontier.empty():
current = frontier.get()
if current == goal:
break
for next in graph.neighbors(current):
if next not in came_from:
frontier.put(next)
came_from[next] = current
移动的代价
到目前为止,我们都是假定移动的消耗是一样的。在一些路径查找方案中,对于不同类型的移动有着不同的代价消耗。例如,在市区,通过平原或沙漠可能消耗1元(为了简单,咱们用“元”作为单位),但是通过森林或者小山可能会消耗5元。在这网页的顶端地图中,穿过河流需要10倍或者更多的代价比通过草地。另一个例子是:网格中的对角线移动比轴向(绕着走)移动消耗更多。我们想要将这些消耗考虑进去,然后再计算查找路径。让我们来比较从起始位置的步数以及从起始位置的距离:
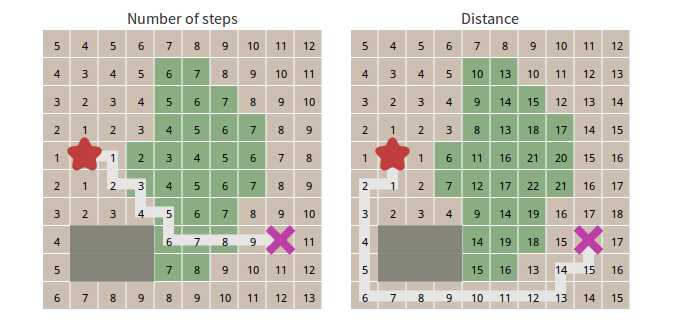
这里我们想用Dijkstra算法来解决这个问题。它跟广度优先算法有什么不同呢?我们需要跟踪它们的移动代价,所以让我们来添加新的变量cost_so_far,去跟踪记录从起始位置开始总共的移动消耗代价。我们想要将移动消耗代价考虑进去,然后决定怎样评估位置;让我们把队列转为优先级队列。不太明显的,我们最终可能会访问一个位置多次,不同的成本,所以我们需要一点点的改变逻辑。不要再 在遇到没有访问过的节点情况下添加该节点到前驱序列中,而是要 在到目标位置的新路径优于之前的路径的情况下才将该节点添加进去。
frontier = PriorityQueue()
frontier.put(start, 0)
came_from = {}
cost_so_far = {}
came_from[start] = None
cost_so_far[start] = 0
while not frontier.empty():
current = frontier.get()
if current == goal:
break
for next in graph.neighbors(current):
new_cost = cost_so_far[current] + graph.cost(current, next)
if next not in cost_so_far or new_cost < cost_so_far[next]:
cost_so_far[next] = new_cost
priority = new_cost
frontier.put(next, priority)
came_from[next] = current
使用一个优先级队列,
标签:
原文地址:http://www.cnblogs.com/L-Arikes/p/4314113.html