标签:
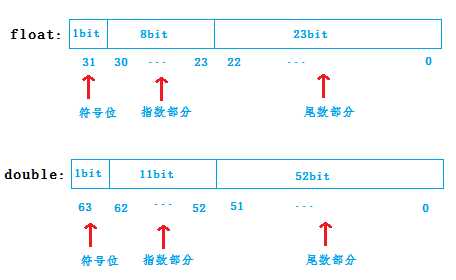
浮点型变量在计算机内存中占用4个字节(4 Byte),即32-bit,一个浮点数由2部分组成:底数m 和 指数e;
底数部分:使用2进制数来表示此浮点数的实际值;
指数部分:占用8=bit空间来表示,表示数值范围:0-255;后面介绍 用于存储科学计数法中的指数部分,并且采用移位存储方式;
具体分析:
浮点数据就是按下表的格式存储在4个字节中:
Address+0 Address+1 Address+2 Address+3 Contents
SEEE EEEE EMMM MMMM MMMM MMMM MMMM MMMM
S部分: 表示浮点数正负,1为负数,0为正数。一位即可
E部分:指数加上127后的值的二进制数(why是加上了127之后的值? 由于指数应可正可负,所以IEEE规定,此处算出的次方须减去127才是真正的指数。所以float的指数可从 -126到128.)
M部分:24-bit的底数(底数部分实际是占用24-bit的一个值,由于其最高位始终为 1 ,所以最高位省去不存储,在存储中只有23-bit。)
特例:浮点数 为0时,指数和底数都为0,但此前的公式不成立。因为2的0次方为1,所以,0是个特例。这个特例也不用认为去干扰,编译器会自动去识别。
举例:看下-12.5在计算机中存储的具体数据:0xC1 0x48 0x00 0x00
二进制:11000001 01001000 00000000 00000000
格式:SEEE EEEE EMMM MMMM MMMM MMMM MMMM MMMM
可见:
S: 为1,是个负数。
E:(8-bit)为 10000010 转为10进制为130,130-127=3,即实际指数部分为3.
M:(23-bit)为 10010000000000000000000。底数实际上是:1.10010000000000000000000
现在,我们通过指数部分E的值来调整底数部分M的值。
调整方法为:如果指数E为负数,底数的小数点向左移,如果指数E为正数,底数的小数点向右移。小数点移动的位数由指数E的绝对值决定。
这里,E为正3,使用向右移3为即得: 1100.10000000000000000000
转换过程:小数点左边的1100 表示为 (1 × 2^3) + (1 × 2^2) + (0 × 2^1) + (0 × 2^0), 其结果为 12 。
小数点右边的 .100… 表示为 (1 × 2^-1) + (0 × 2^-2) + (0 × 2^-3) + ... ,其结果为.5 。
以上二值的和为12.5, 由于S 为1,使用为负数,即-12.5 。所以,16进制 0XC1480000 是浮点数 -12.5 。
下面看下如何将一浮点数装换成计算机存储格式中的二进制数。 举例将17.625换算成 float型。
1、转为二进制:10001.101
2、小数点,左移4位,变成1.0001101
3、这样底数为:1.0001101, 指数为:4+127=131,二进制位:1000011
4、符号位为0,因为是正数;
5、合并:0 1000011 0001101后面补0,补成32-bit;
6、转成16进制:转换成16进制:0x41 8D 00 00
浮点数转成二进制代码形式代码:
1 #include<iostream> 2 using namespace std; 3 4 #define uchar unsigned char 5 6 void binary_print(uchar c) 7 { 8 for(int i = 0; i < 8; ++i) 9 { 10 if((c << i) & 0x80) 11 cout << ‘1‘; 12 else cout << ‘0‘; 13 } 14 cout << ‘ ‘; 15 } 16 17 int main() 18 { 19 float a; 20 uchar c_save[4]; 21 uchar i; 22 void *f; 23 f = &a; 24 25 cout<<"pls input a float num:"; 26 for(i=4;i!=0;i--) 27 binary_print(c_save[i-1]); 28 cout<<endl; 29 30 return 0; 31 }
C标准规定,float类型必须至少能表示6位有效数字,就像33.333 333这样的数字的小数点后的前6位;那么whyfloat能表示6位有效数字呢?
解释如下:十进制中的9,在二进制中的表示形式是1001,这也就是说: 表示十进制中的一位数在二进制中需要4bit,所以我们现在float中具有24bit的精度,所以float在十进制中具有24/4=6,所以在十进制里,float能够精确到小数点后6位;
double呢?其实和float原理是一样的,只是double的位数更长一些而已;
注意点,double类型数据操作比float型运算要慢很多;
c语言中float、double、long double在内存中存储方式
标签:
原文地址:http://www.cnblogs.com/chris-cp/p/4321793.html