标签:
之前说到,朴素的匹配,每趟比较,都要回溯主串的指针,费事。则 KMP 就是对朴素匹配的一种改进。正好复习一下。
KMP 算法其改进思想在于:
每当一趟匹配过程中出现字符比较不相等时,不需要回溯主串的 i指针,而是利用已经得到的“部分匹配”的结果将模式子串向右“滑动”尽可能远的一段距离后,继续进行比较。如果 ok,那么主串的指示指针不回溯!算法的时间复杂度只和子串有关!很好。
KMP算法的关键是利用匹配失败后的信息,尽量减少模式串与主串的匹配次数以达到快速匹配的目的,很自然的,需要一个函数来存储匹配失败的信息。
先理解一个概念:前后缀字符串
比如"ababa"
前缀:a,ab,aba,abab,除了最后一个字符
后缀:a,ba,aba,baba,除了第一个 字符
比如"abcd"
前缀:a,ab,abc
后缀:d,cd,bcd
图解kmp 算法对朴素匹配改进的过程;
同样如图1,发生不匹配,朴素的做法是 j 到开头1出,i 到上次开始比较的位置的下一位2处(i回溯)
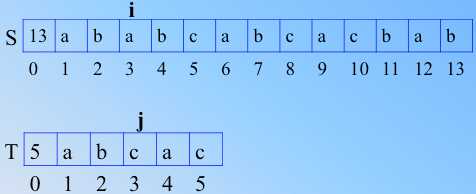 图1
图1 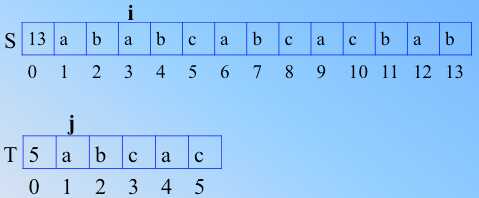 2
2
但是发现一个问题,那就是在 图1的3处,不匹配的时候,前面的字符已知是匹配的,ab 是模式串里临时匹配的串,如果 i 回溯,那么等于是白白去比较,因为要把"搜索位置"移到已经比较过的位置,重比一遍。无用功,如果此时 i 不动,直接就可以减少无用的比较次数(所谓无用是说以最少的比较次数,找出完全的匹配串,尽量少做不匹配比较,通过之前的信息来计算和判断),如上图2,i 不动,j 回溯到1,匹配,ij继续走……一直都是匹配的,直到图4
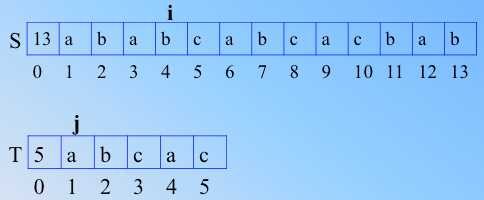 3
3 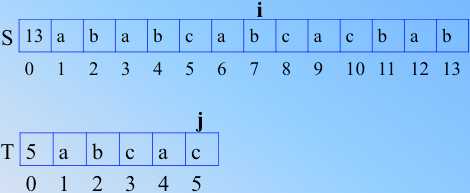 4
4
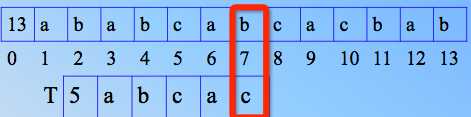
那么不匹配了,临时的匹配串是 abca,如果 j 还是回到1,i 回溯到4(朴素的),我们发现1和4比较后不匹配,那么 i 继续右移,j 还是1,直到 i 到了6,才和 j=1处的 a 匹配,是不是之前的比较都是无用功?为什么不可以直接就和6比较呢?怎么解决呢?
发现一个规律:如果临时匹配串里,前后缀有重复,那么其实模式串的j,没必要每次都回到1,仔细思考是这样的。有一定规律可寻。
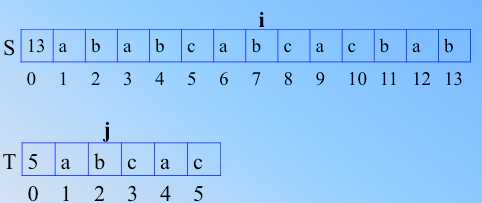 5
5 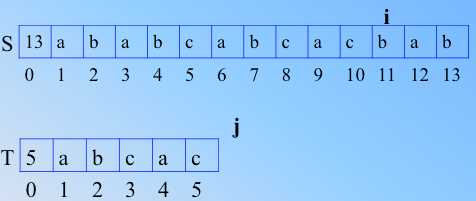 6
6
整个过程结束,最后结果和朴素一样,但减少了比较次数,改进了时间复杂度,让 o(t) 只和模式串t有关,因为主串s是给定的,且 i 不回溯,一直往前走!
到这里,就要思考,如何找出 j 回溯的逻辑。
换一个角度思考;
之前我们的做法是都观察 i j 的回溯!如图,现在我们移动模式串来观察。
 7
7 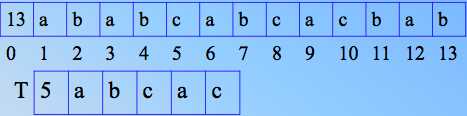 8
8
图7不匹配, i 到2,j 到1,其实这相当于 T 右移,看图8。T 继续右移直到发生匹配,顺次比较,直到图9,红色标出,发现了不匹配,那么,按照之前的朴素做法,i 到4,j 还是1,相当于 T还是 右移一位!如下下图10。
 9
9 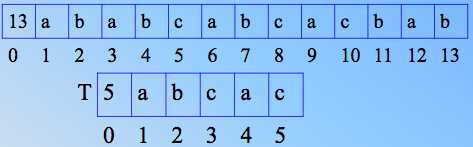 10
10
比较之后,不匹配,T 继续友谊,直到T 1处移动到S6处,才发生匹配,之后继续顺次比较,ok!找出了匹配串。
 11
11
那么通过观察来思考:每当临时匹配串(已知的)前后有重复的时候,那么只需 把模式串 T 直接移动到后缀刚刚开始有重复的位置(设移动距离为 d),i 不回溯。也就是j 直接反向的回溯距离 d,亮着等价的。为什么这样?
因为,在字符串搜索和匹配的时候,经常有前后重复的时候,前缀和后缀重复!如倒数第3图的已知的临时匹配串abca,前后缀 a 重复!此时没必要再用模式串的首位a去和S 的 b 比较了,直接和前后缀子串第一次有重复的位置比较(设子串右移距离 d),也就是 a 处。如果还那么顺次比较,是做无用功!此时思考如何实现这个逻辑,找到对应的j 回溯的距离 d。这个距离 d 就是前后重复的字符串的距离。
设置一个数组next来返回模式串的 j 应该回溯的位置
若令数组next[j]=k,则next[j]表明当模式中第j个字符与主串中相应字符失配时,在模式中需要重新和主串中该字符进行比较的字符的位置。
得到 KMP 模式匹配算法的实现思路(区别就是 next 函数)
那么问题来了,如何实现 next数组 ,生成对于的 j回溯的位置,从前面的讨论可知,next数组值仅取决于模式串本身,而与主串无关。
j 的回溯距离d 等于模式串中临时匹配串长(也就是j) 减去 相同的前后缀子串中的最大子串长度S(两个最大子串的距离),next 的值就是 j - j + S =S因此要计算next函数的返回值,就要找出前缀和后缀相同的最大子串的长度。
这个查找过程实际上仍然是模式匹配,只是匹配的模式与目标在这里是同一个串S。(这里遵守 c 的规定,数组都是默认下标0开始存储)
//计算 next 数组:根据待匹配的字符串,求出对应每一位的最大相同前后缀的长度 void computeNext(char *str, int next[]) { } int strKMPCompare(char *strMain, char *strSub, int index, int next[]) { int iMain = index; int jSub = 0; int lenMain = getLength(strMain); int lenSub = getLength(strSub); while ((iMain >= 0 && iMain <= lenMain - 1) && ((jSub >= 0 && jSub <= lenSub - 1))){ if (strMain[iMain] == strSub[jSub]) { iMain++; jSub++; }else{ //主串的 i 不回溯! //计算 next 数组 computeNext(strSub, &next[0]); jSub = next[jSub]; } } //如果匹配 ok,肯定子串先比完。 if (jSub > lenSub - 1) { return iMain - lenSub;//得到的就是匹配 ok 后,主串里第一个和模式串第一个字符匹配的字符的位置 }else{ return 0;//匹配失败 } }
那么最大的问题来了,如何实现 next数组?
next 数组递推的图解如下,已知,模式串的长度为 L ,j=0的时候,也就是第一个就不匹配, 规定next[0]=-1成立!其实在匹配过程中,若发生不匹配的情况,如果next[j]>=0,则目标串的指针i不变,将模式串的指针j移动到next[j]的位置继续进行匹配;若next[j]=-1,则将i右移1位,并将j置0,继续进行比较。
假设执行到某步,求出此时的 j (也就是第 j+1项发生不匹配)的 next[j] = k,k 是程序执行到这 步时,最长前后缀子串的长度。
如下是最长前缀子串:
P(0) P(1) …… P(K-1)
如下是模式串:
P(0) P(1) …… P(K-1) P(K) P(K+1) …… P(J-1) P(J) …… P(L - 1)
因为前后缀子串长度相等为 k,那么得到:
P(0) P(1) …… P(K-1) = P(J - K) …… P(J-1)
其中P(J - K) …… P(J-1)是最长后缀子串,长度是 k,注意满足j-1-j+k=k-1,直观的看就是:
P(0) P(1) …… P(K-1)
|| || || ||
P(J - K) …… P(J-1)
如果,对于模式串,继续求 j+1的 next[J+1],如下:
P(0) P(1) …… P(K-1) P(K) P(K+1) …… P(J - K) …… P(J-1) P(J)
如果 p(k)=p(j),那么有:
P(0) P(1) …… P(K-1) P(K)
|| || || || ||
P(J - K) …… P(J-1) P(J)
此时,next[j+1]=k+1=next[j]+1
如果,p(k)!=p(j),那么需要从新检查,不过不论怎样计算,最后还是能得到一个正确的结果,即:最大重复前后缀字符串的前缀子字符串开头一定是 p(0),后缀字符串结尾一定是 p(j)。 但是在得到这个正确结果之前,我们总会经历相思的步骤,因为是找前后缀相等的子字符串,那么一般情况下总会经历这样的过程:前缀子字符串开头一定是 p(0),而已经知道后缀字符串的倒数第二项等于 p(k-1),那么前缀字符串的倒数第二项也应该等于 p(k-1),现在设为 p(m-1)来表示,又我们假设的是求出了next[j]=k,
P(0) P(1) …… p(m-1) …… P(K-1) P(K) P(K+1) …… P(J - K) …… P(J-1)
那么 j 之前的 每一位对应的 next 也都求出了,自然得到next[k-1]=m,此时前缀的结尾 p(m)要么满足和 p(j)相等,要么不相等,如相等还是m++处理,不等还是如上的过程,这样递归下去直到成功找到。
本质上则可以把其看做模式匹配的问题,即匹配失败的时候,k值如何移动
next[k-1]=m,next[m-1]=n,……,next[0]=0 =》
next[next[next[k-1]-1]-1……]=next[j+1] 且 next[j]=k
或
k++
实现代码
1 //计算 next 数组:根据待匹配的字符串,求出对应每一位的最大相同前后缀的长度 2 void computeNext(char *str, int next[]) 3 { 4 int k = -1;//记录最长前后缀字符串的长 5 int i = 1;// 6 //next【0】=-1,肯定要遍历模式串 7 next[0] = -1; 8 //模式串长度 9 int len = getLength(str); 10 //第一岑循环控制计算到模式串的每一位 11 while (i < len) { 12 //第二层循环,控制每次计算到某位置时,递归求解 k 的过程 13 //next[next[next[k-1]-1]-1……]=next[j+1] 且 next[j]=k 14 while (k > 0 && str[i] != str[k]) { 15 k = next[k - 1];//递归,逐层深入,调用 16 } 17 //i 变化,如果 stri=strk,退出递归循环,直接+1求解,否则一直递归到为k<=0退出 18 if (k == -1 || str[i] == str[k]) { 19 k++; 20 } 21 //所有情况都处理完毕,存储结果 22 next[i] = k; 23 i++; 24 } 25 }
需要注意几个点,因为规定了,next[0]=-1,那么 k 最小应该为-1,且若 next 返回-1的话,说明第一个不匹配,那么这里注意下,把 i++,j=0设置!在 kmp 函数里注意。
jSub = next[jSub]; if (jSub == -1 ) { jSub = 0; iMain++; }
在next 函数的 if 语句中,当 strk==stri, k++,但是还要注意,k==-1的情况!也要k++,否则紧跟 下面的 赋值,会把-1付给next【i】
完整代码
1 //计算 next 数组:根据待匹配的字符串,求出对应每一位的最大相同前后缀的长度 2 void computeNext(char *str, int next[]) 3 { 4 int k = -1;//记录最长前后缀字符串的长 5 int i = 1;// 6 //next【0】=-1,肯定要遍历模式串 7 next[0] = -1; 8 //模式串长度 9 int len = getLength(str); 10 //第一岑循环控制计算到模式串的每一位 11 while (i < len) { 12 //第二层循环,控制每次计算到某位置时,递归求解 k 的过程 13 //next[next[next[k-1]-1]-1……]=next[j+1] 且 next[j]=k 14 while (k > 0 && str[i] != str[k]) { 15 k = next[k - 1];//递归,逐层深入,调用 16 } 17 //i 变化,如果 stri=strk,退出递归循环,直接+1求解,否则一直递归到为k<=0退出 18 if (k == -1 || str[i] == str[k]) { 19 k++; 20 } 21 //所有情况都处理完毕,存储结果 22 next[i] = k; 23 i++; 24 } 25 } 26 27 int strKMPCompare(char *strMain, char *strSub, int index, int next[]) 28 { 29 int iMain = index; 30 int jSub = 0; 31 int lenMain = getLength(strMain); 32 int lenSub = getLength(strSub); 33 34 while ((iMain >= 0 && iMain <= lenMain - 1) && ((jSub >= 0 && jSub <= lenSub - 1))){ 35 if (strMain[iMain] == strSub[jSub]) { 36 iMain++; 37 jSub++; 38 }else{ 39 //主串的 i 不回溯! 40 //计算 next 数组 41 computeNext(strSub, &next[0]); 42 jSub = next[jSub]; 43 if (jSub == -1 ) { 44 jSub = 0; 45 iMain++; 46 } 47 } 48 } 49 //如果匹配 ok,肯定子串先比完。 50 if (jSub > lenSub - 1) { 51 return iMain - lenSub;//得到的就是匹配 ok 后,主串里第一个和模式串第一个字符匹配的字符的位置 52 }else{ 53 return 0;//匹配失败 54 } 55 } 56 57 int main(int argc, const char * argv[]) { 58 char *str1 = "avcbababcc"; 59 char *str2 = "bab"; 60 int next[100] = {0}; 61 62 int i = strKMPCompare(str1, str2, 0 , &next[0]); 63 64 for (int i = 0; i < 11; i++) { 65 printf("%d \n", next[i]); 66 } 67 68 printf("%d\n", i); 69 70 return 0; 71 }
-1
0
1
0
0
0
0
0
0
0
0
3
Program ended with exit code: 0
补充:next数组的直接求法,上面说的是递归思想,递推关系。其实也可以直接求解。
思考:关键是如何比较,肯定需要知道模式串长 len,还需要头部一个标记,尾部一个标记。直接想到循环去遍历两个头,头++,尾部++,这是求的模式串的某个位置的 next 数组值。故还需要一个外循环控制依次遍历模式串。在这个外循环里,每趟循环,调用一次比较函数,求出 next[x]=?,通过 break 退出内部循环,实现一次调用。
1 //i 是前缀长,后缀长=i,故后缀第一个下标是 j-i ,通过比较函数内部的约束来调整参数 2 bool equal(char *str, int i, int j) 3 { 4 int head = 0;//假设是 0 1 …… i-1 和 j-i …… j-1,依靠,前后缀相等的特征! 5 int tailHead = j - i;//参数 i 是前缀字符串的尾部下标,而前缀字符串长度就是 i,等于后缀字符串长度,故用末位 j-i 就是后缀字符串的开头 6 7 for (; head <= i - 1 && tailHead <= j -1; head++, tailHead++) { 8 if (str[head] == str[tailHead]) { 9 return true; 10 } 11 } 12 13 return false; 14 } 15 16 void getNext(char *str, int next[]) 17 { 18 int nextI = 0; 19 int head = 0; 20 21 for (; nextI < getLength(str) ; nextI++) { 22 //规定0是-1 23 if (0 == nextI) { 24 next[nextI] = -1; 25 }else if (nextI == 1){ 26 next[nextI] = 0; 27 } 28 else{ 29 //进行比较,需要一个循环控制 尾部字符串的处理 30 for (head = nextI - 1; head > 0; head--) { 31 //head 是头字符串的终点,nextI 是临时模式串的终点 32 if (equal(str, head, nextI)) { 33 next[nextI] = head; 34 break; 35 } 36 } 37 //别忘了要习惯性的思考边界的特例,如果 head--为0了,自动退出内循环,要处理下,其实是说明字符串没有任何重复字符出现的情况。 38 if (0 == head) { 39 next[nextI] = 0; 40 } 41 } 42 } 43 }
改进的 next数组 算法
在看一个例子:
主串:’aaabaaab’;
子串: aaaa3b
当子串中的第四个字符’a’与主串中的第四个字符’b’失配后,按照之前的 next 数组求法,的 next[3]=2如果用子串中的第3个字符’a’继续与主串中的第四个字符’b’比较,将是做无用功。以此类推。说明:kmp 算法里的关键next函数仍有改进的地方。改进next函数:当子串中的第j个字符与主串中的第i个字符失配后,如果有next[j]=k;且在子串中有pj=pk;那么pk肯定也与主串中的第i个字符不等,所以,直接让
next[j]=next[k];
直到他们不等或next[j] = -1为止。这个很好理解。当子串中的第四个字符’a’与主串中的第四个字符’b’失配后,next[3]=next[2]=1,则next[3]=next[1] = next[0] = -1。这样效率又高了些。
//所有情况都处理完毕,存储结果 if(str[i] == str[k]) { //本质还是把一个 k 赋值给了 next【i】,然后回到 while 处从新循环 next[i] = next[k]; }else{ next[i] = k; }
KMP算法只有在主串和模式串"部分匹配"时才会才会体现出他的优势,否则两者差异不大 ,KMP算法应用(可借鉴和参考的思想) 首先next数组代表每个字符在匹配失败时,回溯的位置,我们可以通过next数组找到每个字符的前缀和后缀
字符串模式匹配之KMP算法图解与 next 数组原理和实现方案
标签:
原文地址:http://www.cnblogs.com/kubixuesheng/p/4322612.html