标签:
under review as a conference paper at ICLR 2015.
Motivation:
本文提出来一种regularization的方法,叫做FaMe (Factored Mean training). The proposed FaMe model aims to apply a similar strategy, yet learns a factorization of each weight matrix such that the factors are robust to noise.
具体做法如下:
Standard dropout hidden activation:
![]()
其中r^(l-1)是dropout noise。
FaMe hidden activation:
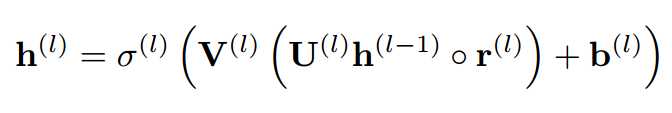
其中r^(l)也是noise,可以是dropout或者additive/multiplication Gaussian
唯一的区别在于把weight进行matrix factorization可以变成low rank:
![]()
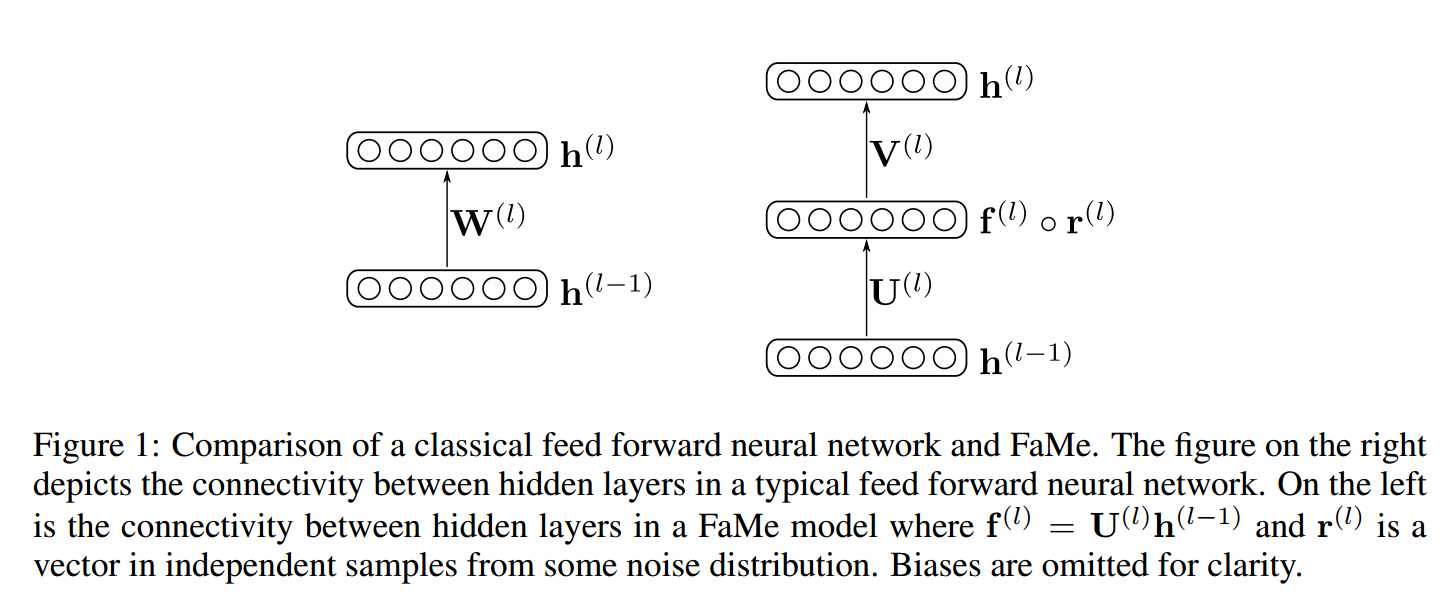
一些问题:
说实话我没有太明白这个文章的motivation。除了做了一个Matrix factorization之外,基本上和standard dropout差不多。但是Standard dropout作为一种mask noise具有regularization的效果,按照作者自己在abstract里面陈述的,做factorization可以robust to noise。那么问题来了:
Q1:为什么会robust to noise?是因为low rank吗?noise对应eigenvalue非常小的eigenvector,现在low rank导致非常小的eigenvalue变成0,某种程度上有denoise的效果?
Q2:为什么需要robust to noise呢?就像我前面说的,dropout noise正是带来regularization效果的东东,是好的。如果robust to noise是Q1里面理解的那样,有denoise的效果,那为什么要把好的noise给去掉呢?
Q3:V和U这两个矩阵的参数怎么求的,我不是很清楚?作者说和standard的NN一样?
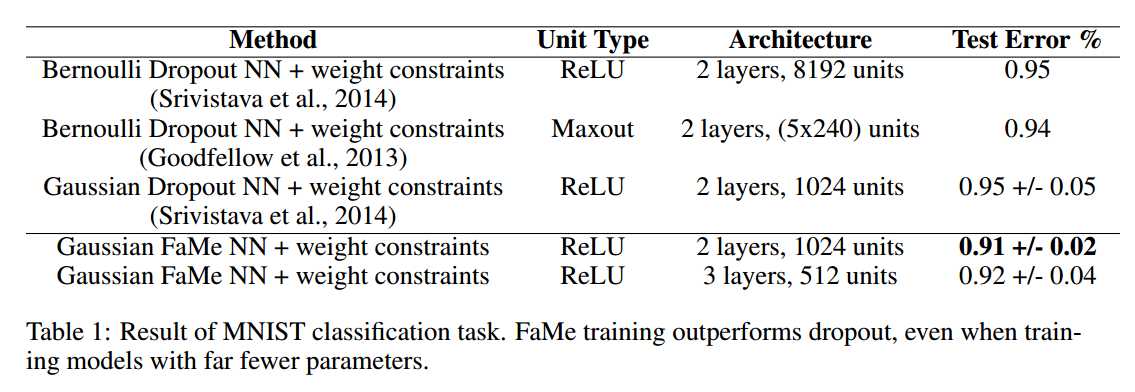
实验部分:
本文测试的dataset有MNIST, CIFAR-10. 从实验结果来看,效果并不明显。

Deep Learning 论文笔记 (2): Neural network regularization via robust weight factorization
标签:
原文地址:http://www.cnblogs.com/yyuanad/p/4326649.html