标签:
一、缓存什么时候用?
数据量增大后,直接频繁操作数据库会对库造成很大的压力,对于变更不太频繁,读的频率远大于写的频率,而且对实时性要求不太高的内容,放在缓存中,能减小数据库压力,提高访问速度。下图为使用缓存和不使用缓存时的请求处理流程:
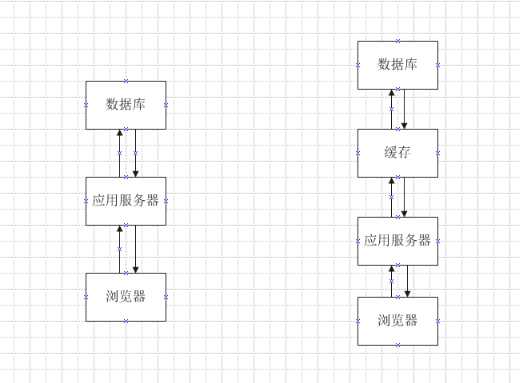
可见,在使用了缓存后,直接通过缓存取数据,减小了数据库的压力。
二、缓存技术Redis?
现在所在的项目缓存技术用的是Memcache,都知道Memcache和Redis一样,都用做缓存之用。一直被旁人灌输的就是Redis的种种优越性,二者相比,Redis的两大特点是:
(1)Memcache只能存储键值对,Redis除了可以存储键值对而外,还支持list、set等数据类型;
(2)Memcache存储的数据只能放在内存中,而Redis支持数据的持久化,可以定期将内存中的数据持久化到硬盘上。
如此看来,Redis似乎要优于Memcache,那么,Memcache应该作为被抛弃的对象才对,为什么还会有人选择它呢?
三、为什么要用Memcache?
(1)考虑具体应用目的:
在视频专区这个项目中,前台首页分版块展示视频节目的封面图片,通过封面链接到视频的详情页,进行视频的播放。这些内容变更不频繁,正好符合使用缓存的条件,到底该使用哪种缓存技术呢?在Redis和Memcache的选择中:1、存取图片只需要进行简单的key-value存储,不需要更多的数据类型;2、首页内容不需要持久化到硬盘;3、经过调研,在100k以上的数据中,Memcache性能要高于Redis,对于大数据的存储,Memcache还是要占优势一些。结合以上三点,最终项目选择使用Memcache。
当然,业务不同选择也各不相同,总之一句话,合理分析合理选择。
(2)Memcache二三事:
1、工作原理:
Memcache的工作模式并不复杂,同样也是惯用的C/S模式,分为服务器端和客户端。服务器端启动后就一直保持可用状态,等待客户端的连接。在Memcache中数据使用key-value的形式进行存储,你可能会问,key如何生成和管理呢?还是具体问题具体分析,生成规则可以根据业务自己来定,假如你要存用户名,那么就可以用用户id来作为key。key的值通过hash进行转换,根据 hash值把value传递到对应的具体的某个 服务器上。当需要获取对象数据时,也要对key进行hash,通过获得的值可以确定它被保存在了哪台Server上,然后再向该Server发出请求获取数据,客户端只需要知道保存hash(key)的值在哪台服务器上就可以了。
说到底,Memcache的工作就是在专门的机器的内存里维护一张巨大的hash表,来存储经常被读写的一些数组与文件。
2、分布式:
单台Memcache的内存容量的有限的,Memcache可以实现分布式来扩充内存,例如可以由10台8G内存的机器,构成一个80G的内存池,如果觉得还不够大可以增加机器,这样一个大的内存池,完全可以把大部分热点业务数据保存进去,由内存来阻挡大部分对数据库读的请求,对数据库释放可观的压力。
它的分布式是怎么实现的呢?个人对这部分内容很好奇。Memcache服务器端仅提供存储功能,等待客户端的连接,分布式主要通过客户端路由来实现。每次存取某key的value时,通过某种算法把key映射到某台Memcached服务器节点上,因此这个key所有操作都在这个节点上。怎么才能让数据平均到所有服务器上呢?经常采用的是hash算法。hash后对服务器数目n取模,假设有3台机子,余数为1即分配到第一台机子。
顿时我产生了一个疑问,分布式的机子只要有一个宕机了,服务器数目发生变化,key的分配就会发生根本性的变化,怎样才能使影响最小化呢?consistent hashing思想应运而生,它指的是服务器节点的hash值配置到一个0到232的圆上,同时求出key的hash值,也映射到圆上,然后顺时针找到的第一个服务器即为保存数据的服务器。这样一来,增加或减小服务器,只会影响增加或减小点之前的数据分布。我不禁对如此精妙的思想感到万分佩服。
四、后记
对于Memcache,暂时只是将了解的皮毛总结记录下来,希望后续一步一步学习后能持续更新。
标签:
原文地址:http://www.cnblogs.com/yangml/p/4331599.html