标签:
Spring的开发初衷是为了减轻企业级开发的复杂度,其对数据库访问的支持亦如此,使用Spring访问数据库能带来以下好处:
使用原生的JDBC访问数据库,一般总是要执行以下步骤:
1) 获取数据库资源,例如连接等;
2) 准备并执行SQL,并处理返回结果
3) 释放数据库资源
4) 处理上述所有步骤出现的异常,处理异常的过程中也要捕获异常
典型的代码结构如下:
public TestObj queryTestObj(long id)
{
final String SQL_SELECT_OBJ="select * from testobj where id=?";
Connection conn = null;
PreparedStatement stmt = null;
ResultSet rs=null;
try
{
conn = dataSource.getConnection();
stmt = conn.prepareStatement(SQL_SELECT_OBJ);
stmt.setLong(1, id);
rs = stmt.executeQuery();
TestObj obj=null;
if(rs.next())
{
obj = new TestObj();
//将查询出的各项属性设置至TestObj对象
}
return obj;
}
catch(SQLException ex)
{
//处理异常
}
finally
{
if(rs!=null)
{
try
{
rs.close();
}
catch(SQLException ex)
{
}
}
if(stmt!=null)
{
try
{
stmt.close();
}
catch(SQLException ex)
{
}
}
if(conn!=null)
{
try
{
conn.close();
}
catch(SQLException ex)
{
}
}
}
return null;
}
从示例代码可以看出,真正与业务相关的部分仅仅占用代码的不到20%,而其他大部分代码都在做一些与业务无关的事情,但是这些“冗余代码”却是必不可少而且每个数据库处理都需要,根据“职责拆分”的原则,解决这个问题的办法很明显:将这些“冗余代码”集中到一起。“大步骤相同,而部分步骤的处理细节不同”,这是“模板模式”的典型应用场景。
Spring已经为我们做好了。
先看示例,使用Spring提供的JDBC模板后,上述代码会变成这样:
public TestObj queryTestObjBySping(long id)
{
final String SQL_SELECT_OBJ="select * from testobj where id=?";
return jdbcTemplate.queryForObject(SQL_SELECT_OBJ,
new ParameterizedRowMapper<TestObj>()
{
@Override
public TestObj mapRow(ResultSet arg0, int arg1)
throws SQLException
{
TestObj obj = new TestObj();
//将查询出的各项属性设置至TestObj对象
return obj;
}
}, id);
}
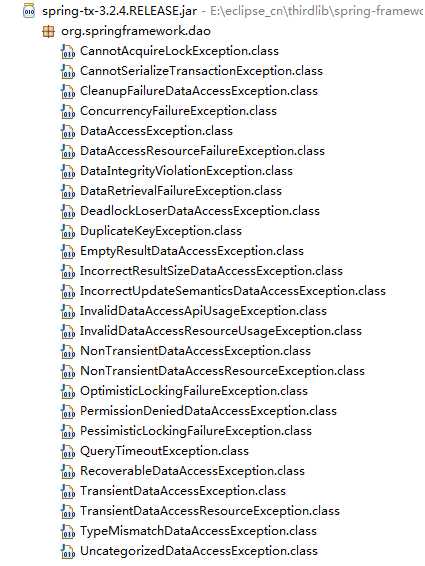
原生JDBC的数据库操作异常类包括BatchUpdateException、DataTruncation、SQLException、SQLWarning四个,而令人难以理解的是,这些异常都是Checked异常,也就是说,代码中必须显式捕捉它们,但是如果出现这些异常,一般都是发生了致命性的且运行时不可恢复的错误,异常处理块中除了打印堆栈外难以有其他有意义的操作。
Spring对此做了两个改进:(1)细化异常,便于分析问题;(2)将异常修改为UnChecked类型。
Spring细化的异常如下
标签:
原文地址:http://www.cnblogs.com/lidabnu/p/4338795.html