可能很多人又有疑问了,既然
Hash 索引的效率要比 B-Tree 高很多,为什么大家不都用 Hash 索引而还要使用 B-Tree
索引呢?任何事物都是有两面性的,Hash 索引也一样,虽然
Hash 索引效率高,但是 Hash
索引本身由于其特殊性也带来了很多限制和弊端,主要有以下这些。
(1)Hash
索引仅仅能满足"=","IN"和"<=>"查询,不能使用范围查询。
由于
Hash 索引比较的是进行 Hash 运算之后的 Hash 值,所以它只能用于等值的过滤,不能用于基于范围的过滤,因为经过相应的
Hash 算法处理之后的 Hash 值的大小关系,并不能保证和Hash运算前完全一样。
(2)Hash
索引无法被用来避免数据的排序操作。
由于
Hash 索引中存放的是经过 Hash 计算之后的 Hash 值,而且Hash值的大小关系并不一定和 Hash
运算前的键值完全一样,所以数据库无法利用索引的数据来避免任何排序运算;
(3)Hash
索引不能利用部分索引键查询。
对于组合索引,Hash
索引在计算 Hash 值的时候是组合索引键合并后再一起计算 Hash 值,而不是单独计算 Hash 值,所以通过组合索引的前面一个或几个索引键进行查询的时候,Hash
索引也无法被利用。
(4)Hash
索引在任何时候都不能避免表扫描。
前面已经知道,Hash
索引是将索引键通过 Hash 运算之后,将 Hash运算结果的 Hash 值和所对应的行指针信息存放于一个 Hash
表中,由于不同索引键存在相同
Hash 值,所以即使取满足某个
Hash 键值的数据的记录条数,也无法从 Hash
索引中直接完成查询,还是要通过访问表中的实际数据进行相应的比较,并得到相应的结果。
(5)Hash
索引遇到大量Hash值相等的情况后性能并不一定就会比B-Tree索引高。
对于选择性比较低的索引键,如果创建
Hash 索引,那么将会存在大量记录指针信息存于同一个 Hash
值相关联。这样要定位某一条记录时就会非常麻烦,会浪费多次表数据的访问,而造成整体性能低下
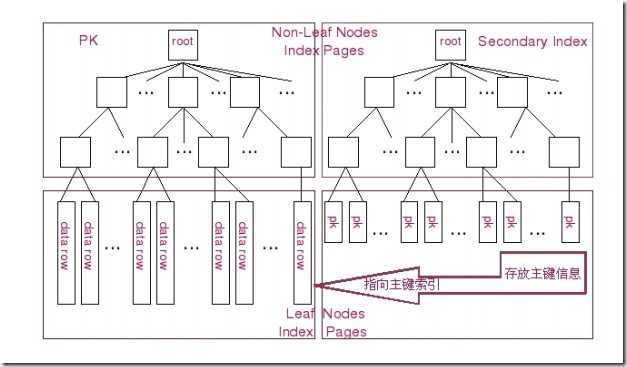
MySQL的btree索引和hash索引的区别,布布扣,bubuko.com
原文地址:http://www.cnblogs.com/xuzhenmin/p/3765658.html