标签:
最近在研究文本挖掘,对于中文文本,首先要进行分词,那么就用到了NLPIR分词系统。总结了一下网上的资料:下面介绍一下如何用C++调用NLPIR分词系统:
step 1:下载最新版的NLPIR分词系统:http://ictclas.nlpir.org/。解压后如下图:
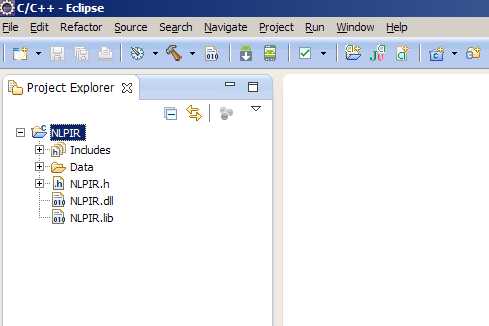
step 2:打开IDE(我用的是eclipse)新建一个c++工程NLPIR,然后从上面解压出来的文件中找到Data、NLPIR.h、NLPIR.lib、NLPIR.dll,拷贝到刚才新建的工程下面:
step 3:添加库文件,右键工程NLPIR—>properties->c/c++ build->settings->Mingw c++ Linker->Libraries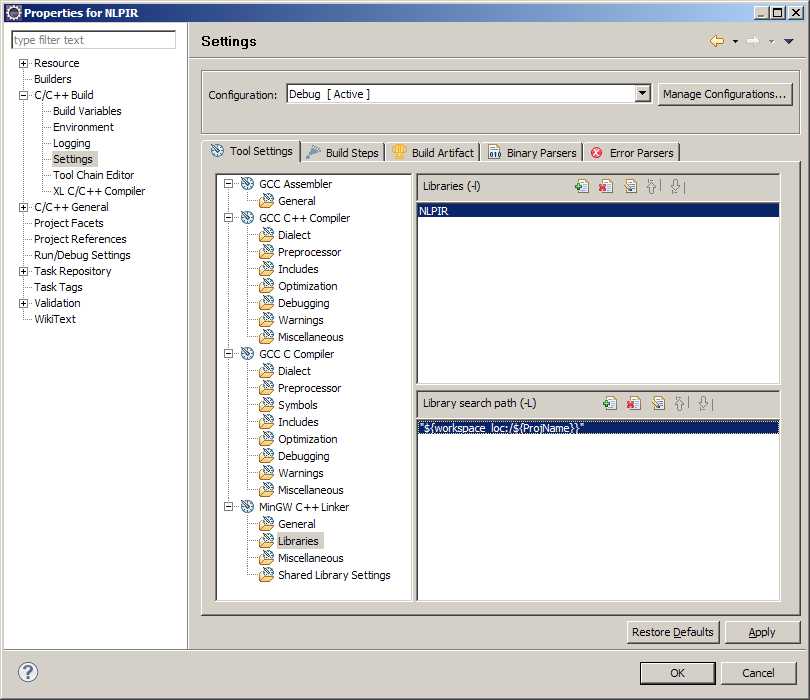
step 4:测试代码:

#include "NLPIR.h" #include <stdio.h> #include <string.h> int main(int argc, char* argv[]) { char sSentence[2000]; const char * sResult; if(!NLPIR_Init()) { printf("Init fails\n"); return -1; } printf("Input sentence now(‘q‘ to quit)!\n"); scanf("%s",sSentence); while(_stricmp(sSentence,"q")!=0) { sResult = NLPIR_ParagraphProcess(sSentence,0); printf("%s\nInput string now(‘q‘ to quit)!\n", sResult); scanf("%s",sSentence); } NLPIR_Exit(); return 0; }
标签:
原文地址:http://www.cnblogs.com/cainiao-xf/p/4341946.html
