标签:c style class blog code java
本篇博客将会介绍R中的一个神经网络算法包:Neuralnet,通过模拟一组数据,展现其在R中是如何使用,以及如何训练和预测。在介绍Neuranet之前,我们先简单介绍一下神经网络算法。
人工神经网络(ANN),简称神经网络,是一种模仿生物神经网络的结构和功能的数学模型或计算模型。神经网络由大量的人工神经元联结进行计算。大多数情况下人工神经网络能在外界信息的基础上改变内部结构,是一种自适应系统。现代神经网络是一种非线性统计性数据建模工具,常用来对输入和输出间复杂的关系进行建模,或用来探索数据的模式。
人工神经网络从以下四个方面去模拟人的智能行为:
物理结构:人工神经元将模拟生物神经元的功能
计算模拟:人脑的神经元有局部计算和存储的功能,通过连接构成一个系统。人工神经网络中也有大量有局部处理能力的神经元,也能够将信息进行大规模并行处理
存储与操作:人脑和人工神经网络都是通过神经元的连接强度来实现记忆存储功能,同时为概括、类比、推广提供有力的支持
训练:同人脑一样,人工神经网络将根据自己的结构特性,使用不同的训练、学习过程,自动从实践中获得相关知识
神经网络是一种运算模型,由大量的节点(或称“神经元”,或“单元”)和之间相互联接构成。每个节点代表一种特定的输出函数,称为激励函数。每两个节点间的连接都代表一个对于通过该连接信号的加权值,称之为权重,这相当于人工神经网络的记忆。网络的输出则依网络的连接方式,权重值和激励函数的不同而不同。而网络自身通常都是对自然界某种算法或者函数的逼近,也可能是对一种逻辑策略的表达。

一. 感知器
感知器相当于神经网络的一个单层,由一个线性组合器和一个二值阈值原件构成:构成ANN系统的单层感知器:

感知器以一个实数值向量作为输入,计算这些输入的线性组合,如果结果大于某个阈值,就输出1,否则输出‐1。
感知器函数可写为:sign(w*x)有时可加入偏置b,写为sign(w*x+b)
学习一个感知器意味着选择权w0,…,wn的值。所以感知器学习要考虑的候选假设空间H就是所有可能的实数值权向量的集合
算法训练步骤:
1、定义变量与参数x(输入向量),w(权值向量),b(偏置),y(实际输出),d(期望输出),a(学习率参数)
2、初始化,n=0,w=0
3、输入训练样本,对每个训练样本指定其期望输出:A类记为1,B类记为-1
4、计算实际输出y=sign(w*x+b)
5、更新权值向量w(n+1)=w(n)+a[d-y(n)]*x(n),0
6、判断,若满足收敛条件,算法结束,否则返回3
注意,其中学习率a为了权值的稳定性不应过大,为了体现误差对权值的修正不应过小,说到底,这是个经验问题。
从前面的叙述来看,感知器对于线性可分的例子是一定收敛的,对于不可分问题,它没法实现正确分类。这里与我们前面讲到的支持向量机的想法十分的相近,只是确定分类直线的办法有所不同。可以这么说,对于线性可分的例子,支持向量机找到了“最优的”那条分类直线,而单层感知器找到了一条可行的直线。
我们以鸢尾花数据集(iris)为例(截取前十行,共150行数据):
ID Sepal.Length
Sepal.Width Petal.Length
Petal.Width
Species
1
5.1
3.5
1.4
0.2 setosa
2
4.9
3.0
1.4
0.2 setosa
3
4.7
3.2
1.3
0.2 setosa
4
4.6
3.1
1.5
0.2 setosa
5
5.0
3.6
1.4
0.2 setosa
6
5.4
3.9
1.7
0.4 setosa
7
4.6
3.4
1.4
0.3 setosa
8
5.0
3.4
1.5
0.2 setosa
9
4.4
2.9
1.4
0.2 setosa
10 4.9
3.1
1.5
0.1
setosa
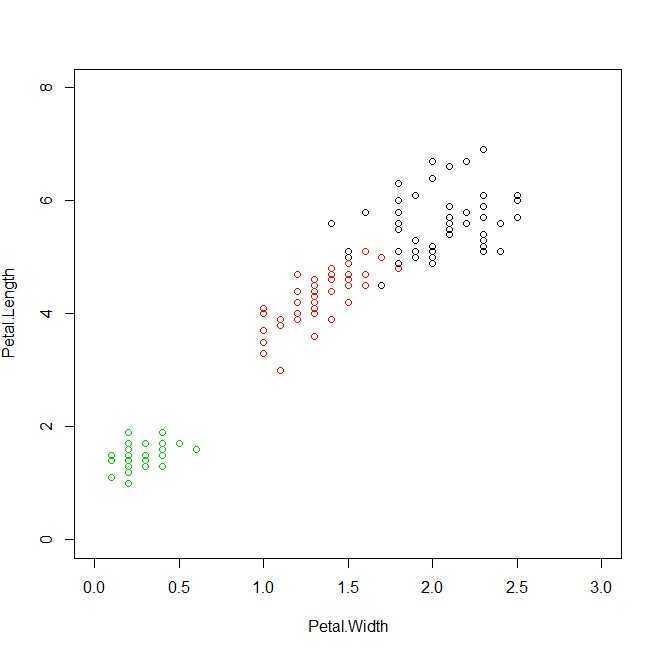
由于单层感知器是一个二分类器,所以我们将鸢尾花数据也分为两类,“setosa”与“versicolor”(将后两类均看做第2类),那么数据按照特征:花瓣长度与宽度做分类。
运行下面的代码:
#感知器训练代码:

1 a<-0.2 2 w<-rep(0,3) 3 iris1<-t(as.matrix(iris[,3:4])) 4 d<-c(rep(0,50),rep(1,100)) 5 e<-rep(0,150) 6 p<-rbind(rep(1,150),iris1) 7 max<-100000 8 eps<-rep(0,100000) 9 i<-0 10 repeat{ 11 v<-w%*%p; 12 y<-ifelse(sign(v)>=0,1,0); 13 e<-d-y; 14 eps[i+1]<-sum(abs(e))/length(e) 15 if(eps[i+1]<0.01){ 16 print("finish:"); 17 print(w); 18 break; 19 } 20 w<-w+a*(d-y)%*%t(p); 21 i<-i+1; 22 if(i>max){ 23 print("max time loop"); 24 print(eps[i]) 25 print(y); 26 break; 27 } 28 }
#绘图代码:
1 plot(Petal.Length~Petal.Width,xlim=c(0,3),ylim=c(0,8), 2 data=iris[iris$Species=="virginica",]) 3 data1<-iris[iris$Species=="versicolor",] 4 points(data1$Petal.Width,data1$Petal.Length,col=2) 5 data2<-iris[iris$Species=="setosa",] 6 points(data2$Petal.Width,data2$Petal.Length,col=3) 7 x<-seq(0,3,0.01) 8 y<-x*(-w[2]/w[3])-w[1]/w[3] 9 lines(x,y,col=4)
二. R中的神经网络算法包——Neuralnet
本次学习将会通过Neuralnet输出如下的神经网络拓扑图。我们将会模拟一组很简单的数据实现输入和输出,其中,输出的变量是独立分布的随机数,输入的变量则是输出变量的平方。本次试验中,将会训练10个隐藏神经元。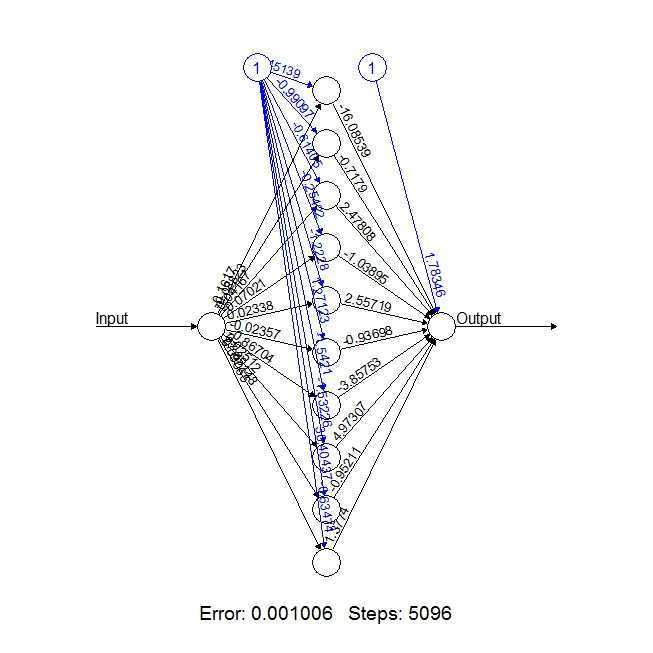
而输入和输出,包括神经网络的预测数据如下:
Input Expected Output Neural Net Output
1 1 0.9623402772
4 2 2.0083461217
9 3 2.9958221776
16 4 4.0009548085
25 5 5.0028838579
36 6 5.9975810435
49 7 6.9968278722
64 8 8.0070028670
81 9 9.0019220736
100 10 9.9222007864
训练代码如下:
1 # 安装并导入neuralnet包(还需要安装grid和MASS两个依赖包) 2 install.packages(‘neuralnet‘) 3 library("neuralnet") 4 5 # 构造50个独立分布在0到100之间的随机数 6 # 然后将他们保存成数据框架(data.frame) 7 8 traininginput <- as.data.frame(runif(50, min=0, max=100)) 9 trainingoutput <- sqrt(traininginput) 10 11 # 通过cbind函数将输入和输出向量构造成一个数据 12 # 用一些训练数据测试该神经网络 13 trainingdata <- cbind(traininginput,trainingoutput) 14 colnames(trainingdata) <- c("Input","Output") 15 16 # 训练10个隐藏神经元的神经网络 17 net.sqrt <- neuralnet(Output~Input,trainingdata, hidden=10, threshold=0.01) 18 print(net.sqrt) 19 20 # 绘制神经网络拓扑图 21 plot(net.sqrt) 22 23 testdata <- as.data.frame((1:10)^2) 24 net.results <- compute(net.sqrt, testdata) 25 26 ls(net.results) 27 28 # 查看结果 29 print(net.results$net.result) 30 31 # 让结果更直观些 32 cleanoutput <- cbind(testdata,sqrt(testdata), 33 as.data.frame(net.results$net.result)) 34 colnames(cleanoutput) <- c("Input","Expected Output","Neural Net Output") 35 print(cleanoutput)
机器学习(1)_R与神经网络之Neuralnet包,布布扣,bubuko.com
标签:c style class blog code java
原文地址:http://www.cnblogs.com/bicoffee/p/3767330.html