标签:c style class blog code java
原文:再议 js 数字格式之正则表达式

前面我们提到到了js的数字格式《浅谈 js
数字格式类型》,之前的《js
正则练习之语法高亮》里也提到了优化数字匹配的正则。
不过最近落叶给了我一个正则,让我豁然开朗,比我写的犀利多了,所以今天拿出来简单说一下(只说十进制部分的匹配)。
先看下我之前写的正则:/\d+(?:\.\d+)?(?:[eE][+-]?\d+)?|\.\d+(?:[eE][+-]?\d+)?/
落叶在
jQuery 中发现的正则: /(?:\d*\.|)\d+(?:[eE][+-]?\d+|)/ (ps:
我去掉了 [+-] 因为没必要匹配那个。。)
很明显犀利很多。
我的思路其实很简单,就是根据官方描述然后写了个臃肿不堪的正则。
在 MDN JavaScript Guide 的 Values, variables, and literals#Floating-point literals
一节中可以看到。
对于js数字格式的语法描述为 [(+|-)][digits][.digits][(E|e)[(+|-)]digits]
(PS:这不是正则)
所以我就粗略的写了一个表达式 (?:\d+)?(?:\.\d+)?(?:[eE][+-]?\d+)?
当时看着比较舒服,但是在测试中,我发现了严重的问题,能空匹配,简单说就是任何空字符串都能匹配成功。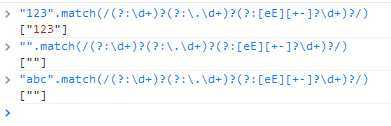
这是一个严重的BUG,所以我把它拆分为两部分,修复了这个BUG,于是得到了上面那个臃肿的代码,没办法水平有限。
其实是我想的太简单了,我只是按照传统的想法写的正则,先匹配整数,然后匹配小数,最后匹配指数。。。
再看 jQuery 中的正则 /(?:\d*\.|)\d+(?:[eE][+-]?\d+|)/ 写的太霸气了。
他的思路是先匹配浮点数,然后匹配小数点后面的整数,接着匹配指数,同样是3部分,只是匹配顺序不同而已。
当然如果匹配不到浮点数,就回溯放弃匹配,直接匹配整数和指数部分。
这样就不需要拆分成两个表达式了。
我们做个测试,先去掉 | 试试,测试数据如下:
1231.231.2e31.2e+31.2e-3.123.12e3.12e+3.12e-3 |
正则: /(?:\d*\.)\d+(?:[eE][+-]?\d+|)/
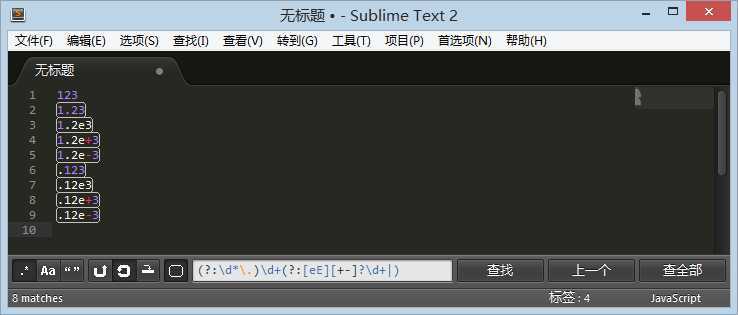
发现 123
没匹配到,后面的浮点型数据都可以正常匹配。
为什么会这样呢,因为 (?:\d*\.)
是必须匹配到 . 的,所以整数就无法匹配成功了。
(?:\d*\.|)
则可以在匹配失败的情况下回溯然后发现第二个表达式是个空,就是不匹配了。
自然就让出位置给后面的 \d+
进行匹配了,所以整数可以匹配成功。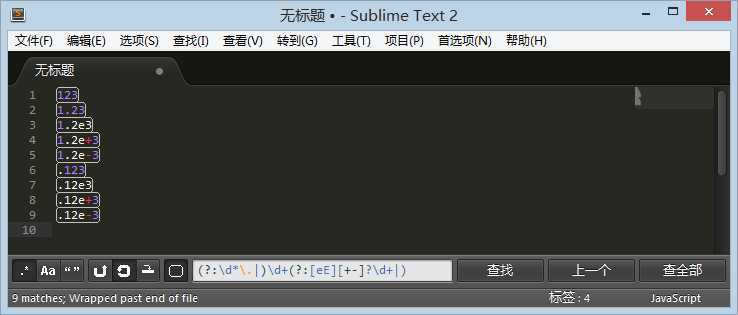
这个正则霸气在于利用最少的代码实现最优的性能,当然整数情况回溯是必须的,不过性能上也不会有多大的问题。
我们来看个测试吧。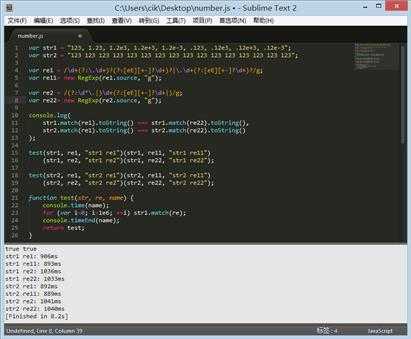
对浮点和整数进行100万次匹配测试,可以看到浮点数测试相差0.1秒,整数相差0.2秒。
这已经是非常小的性能差异了,有的垃圾正则,100万次测试可能会相差十几甚至几十秒呢。
这么个小知识点让我开拓了眼界,其实只是写的少,看的少,所以一直都是井底蛙,技术这东西,必须多看,多想,多写才行。
好了今天的分享完毕,明天见。

再议 js 数字格式之正则表达式,布布扣,bubuko.com
标签:c style class blog code java
原文地址:http://www.cnblogs.com/lonelyxmas/p/3768952.html