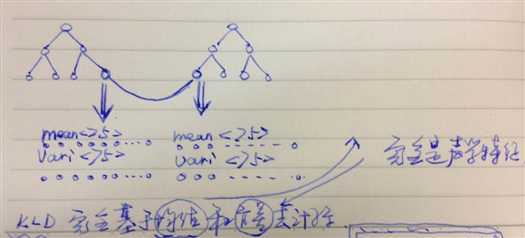
In the state mapping technique described in the previous section, the mismatch of language characteristics affects the mapping performance of transformation matrices because only the acoustic features are taken into account in the KLD-based mapping construction.