标签:
第一段:
In cross-lingual automatic speech recognition (ASR), models applied to a target language are enhanced using data from a different source language.
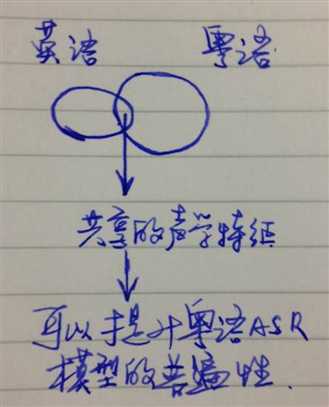
第二段
第三段:
《Cross-lingual adaptation with multi-task adaptive networks》(1)
标签:
原文地址:http://www.cnblogs.com/yu-blog/p/4382083.html