标签:
先来看一条SQL语句: SELECT * FROM aa where acol like ‘%like_normal%‘;
当我们使用Innodb时,无论如何对这条语句进行优化,都是无意义的;有的人会说,对于这种情况先建议采用MyISAM 表来存储,不错,MyISAM确实是个不错的选择;但是我们这个表不仅只有这一列数据,还有其他列呢,开发又说了,对于这个表的数据需要保证一定的事物性,额怎么办?
看到这种变态的SQL,首先想到的办法就是建议开发该逻辑,做缓存,或者直接使用ES,收索引擎等东东;因为这种SQL在MySQL 里边是个头疼的问题,在MySQL5.6以前是不用考虑任何索引机制能够用的上。
好消息就是MySQL5.6版本,加入了这一新特性 InnoDB FULLTEXT Index 东东,简单的来说就是个全文索引,它可以对你指定的表的 TEXT,CHAR,VARCHAR 建立全文索引,注意!! 不是我们说的一般的索引,或者前缀索引的,是全文索引。
问题来了, 什么叫全文索引呢?相信接触过MyISAM、搜索引擎、Lucen 的人对全文索引并不陌生,简而言之,全文索引就是对你的这个文件中每个单词建立一个索引,通过这个单词建立的索引,我们可以快速的找到,这些单词在什么地方。
好了,有了全文索引的基本概念以后呢,我们来看看MySQL InnoDB 的全文索引是怎么实现的,废话少说,直接来试验看结果吧:
我们首先创建一个表:
CREATE TABLE test_fullindex ( id int(11) NOT NULL AUTO_INCREMENT PRIMARY KEY, aname char(200) DEFAULT NULL, bname text, cname varchar(400) );
表建好了以后呢, 我们就可以给它添加一些索引了,为了进行对比,我们添加两个索引:
alter table test_fullindex add fulltext idx_aname_bname(aname,bname); 注意这里有个Warning !!!,稍微我们在说。
alter table test_fullindex add index idx_bname_cname_idx(bname(20),cname(20));
注意建立全文索引的语法和普通索引的语法不一样!
看一下表结构:
mysql> show create table test_fullindex\G
*************************** 1. row ***************************
Table: test_fullindex
Create Table: CREATE TABLE `test_fullindex` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`aname` char(200) DEFAULT NULL,
`bname` text,
`cname` varchar(400) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `idx_bname_cname_idx` (`bname`(20),`cname`(20)),
FULLTEXT KEY `idx_aname_bname` (`aname`,`bname`)
) ENGINE=InnoDB AUTO_INCREMENT=6095778 DEFAULT CHARSET=utf8mb4
Ok, 到目前为止我们的基础表已经建好了,然后我们就开始去发现全文索引的神秘吧:
一般来说,我们都会打开innodb_file_per_table 这个选项的,理由不言而喻。而我们也知道,对于表上的索引是存储在该表的表空间上的,但是对于这个全文索引,就不是这么一回事了,我们去搂一把数据文件一看究竟哈:
-rw-rw---- 1 dba dba 96K Mar 29 23:16 FTS_0000000000000015_0000000000000018_INDEX_1.ibd
-rw-rw---- 1 dba dba 72M Mar 30 00:02 FTS_0000000000000015_0000000000000018_INDEX_2.ibd
-rw-rw---- 1 dba dba 23M Mar 30 00:02 FTS_0000000000000015_0000000000000018_INDEX_3.ibd
-rw-rw---- 1 dba dba 27M Mar 30 00:02 FTS_0000000000000015_0000000000000018_INDEX_4.ibd
-rw-rw---- 1 dba dba 40M Mar 30 00:02 FTS_0000000000000015_0000000000000018_INDEX_5.ibd
-rw-rw---- 1 dba dba 96K Mar 29 23:16 FTS_0000000000000015_0000000000000018_INDEX_6.ibd
-rw-rw---- 1 dba dba 96K Mar 29 23:16 FTS_0000000000000015_BEING_DELETED_CACHE.ibd
-rw-rw---- 1 dba dba 96K Mar 29 23:16 FTS_0000000000000015_BEING_DELETED.ibd
-rw-rw---- 1 dba dba 96K Mar 30 00:02 FTS_0000000000000015_CONFIG.ibd
-rw-rw---- 1 dba dba 96K Mar 29 23:16 FTS_0000000000000015_DELETED_CACHE.ibd
-rw-rw---- 1 dba dba 96K Mar 29 23:16 FTS_0000000000000015_DELETED.ibd
-rw-rw---- 1 dba dba 8.5K Mar 29 23:43 test_fullindex.frm
-rw-rw---- 1 dba dba 2.1G Mar 30 00:05 test_fullindex.ibd
一看这玩意儿,就惊呆了, 刚才我们明明就只建了一个表,为什么多了这么多ibd文件呢?这些文件是从哪里来的呢?
于是我们连上数据库,查一下这个表就知道了:
mysql> select TABLE_ID,NAME,FLAG,SPACE ,ROW_FORMAT from information_schema.innodb_sys_tables where name like ‘%test/%‘;
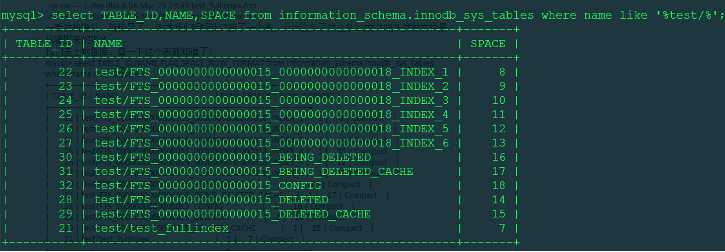

先看几个转换: 21 = 0x15 ;24 = ox18
从这里我们也可以看出,这些几个文件(FTS_*)就是存的全文索引的数据文件,这些文件呢是由系统统一管理,统一命名的,其命名方式相信你已经看明白了。没错,我们的系统会为每张表和每个索引分配一个id,拿到这个ID转换成16进制然后就可以拼接成我们全文索引表的名字,系统默认会给这个全文索引建上6个表,其中的值按照hash分布,这6个表也就是我们上边看到的 FTS_****_***_INDEX_* 了,然后还有几个额外的表,其中有 DELETE字段和CONFIG字段的,这个我们稍后讨论。
好了,我们现在知道了全文索引是怎么存储的了, 以及它直观的表现形式,下面来看看怎么个使用这个FULLTEXT吧。
FULLTEXT的使用比较简单,语法也比较好理解,我们可以使用 SELECT * FROM TEST_FULLINDEX WHERE MATCH(…) AGAINST(…); 这种语法来查询我们想要的结果。
首先解释一下两个特殊字段的含义: MATCH() 这里需要指明你要用到的那个全文索引, 注意对于INNODB表来讲,这里的值就是你创建全文索引时指定的值,比如你在创建全文索引时用了一个字段(aname) 那么这里就应该这样写:MATCH(aname) ; 如果你在创建全文索引是用了两个字段 (aname,bname) 那么你就应该这样写:MATCH(aname,bname)。指定了查找哪个全文索引以后,我们就可以指定我们想查的条件了, 这个条件就是用 AGAINST() 来指定的。
关于AGAINST() , 这里有几种语法可以写:
第一种我们可以直接指定一个字符串,比如我要查找包含 “netease” 的单词, 那么我们可以直接写成 AGAINST(‘netease‘) 或者写成 AGAINST(‘netease‘ IN NATURAL LANGUATE MODE) 都可以, 注意这里是区分大小写的。
两个具体列子:
mysql> select * from test_fullindex where match(aname,bname) against(‘netease‘) limit 1;
mysql> select * from test_fullindex where match(aname,bname) against(‘netease‘ in natural language mode) limit 1;
+---------+-------+----------------+-------+
| id | aname | bname | cname |
+---------+-------+----------------+-------+
| 6095778 | net | netease nethot | hah |
+---------+-------+----------------+-------+
第二种:叫做BOLLEAN查找, 这种查找语法如下:
SELECT * FROM articles WHERE match(aname,bname) against(‘+netease -net‘ IN BOOLEAN MODE);
这种语法有3个关键字: + 代表 AND,- 代表 not , no 代表 OR;
OK , 基本的介绍就到这里,下面会介绍一下,FULLTEXT的内部细节的东西。
InnoDB 5.6 新特性之一:FullTEXT Indexes[1.简单介绍]
标签:
原文地址:http://www.cnblogs.com/svan/p/4382552.html