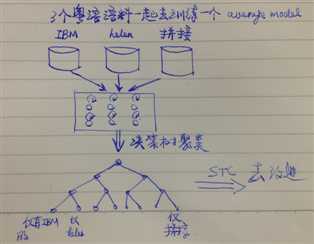
In the conventional decision-tree-based context cluster- ing for the average voice model, each leaf node does not always have the training data of all speakers, and some leaf nodes have only a few speakers’ training data.
As a result, every node of the deci- sion tree has the training data of all speakers, which leads to a speaker-unbiased average voice model.
这就是所谓的speaker-unbiased average voice model
================
================
3.2. Transform mapping based on language-independent decision tree using STC
To use contextual information in the transform mapping be- tween different languages, we must consider the language dependency of decision trees.
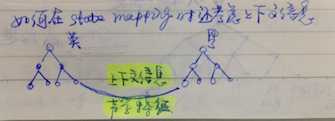
这也是我正在考虑的一个问题,如何在state mapping构建过程中去考虑上下文的信息
什么叫做上下文的信息,于泉杰,你自己能举一个例子吗?
作者在这里给出了一个提示,如何在构建state mapping时,考虑上下文的信息,
必须要考虑决策树的language dependence
In general, near the root node of the decision trees, there are language-independent proper- ties between the two languages in terms of basic articulation manners such as vowel, consonant, and voiced/unvoiced sound.
On the other hand, near the leaf nodes, there frequently appear language-dependent properties because some nodes are split us- ing language-specific questions, e.g., ”Is the current phoneme diphthong?”
在叶子节点处,一般是出现语言相关的属性,因为一些节点的分裂,使用语言特定的问题
例如,当前的音素是diphthong?这种问题是英语所特有的,粤语是肯定没有这个问题的
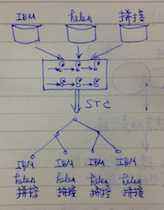
To alleviate the language mismatch in the trans- form mapping between the average voice models, we gener- ate a transform mapping based on a language-independent de- cision tree constructed by STC.
我们使用STC构建一个语言无关的决策树,使用这个决策树来,构建state mapping
Specifically, we use both av- erage voice models of input and output languages in the con- text clustering, and the transformation matrices for the two av- erage voice models are explicitly mapped to each other in the leaf nodes of the language-independent decision tree.
Con- structing the tree, we split nodes from the root using only the questions that can be applied to all speakers of both languages.
构建树,什么树,language-independent decision tree,
构建树,就需要问题集,那么用什么样的问题集呢?
问题集中的问题,必须能应用两种不同的语言
也就是两种语言共享的问题
In this study, we control the tree size by introducing a weight into stopping criterion based on the minimum description length (MDL) [13].
我们控制树的大小,通过引入一个权重,到停止原则中,基于MDL的
To avoid the effect of the language dependency, a smaller tree is constructed compared with that based on MDL.
为了避免语言相关性的影响,一个更小的树被构建,与基于MDL的进行比较
Since the node splitting is based on the acoustic parameters of each node, the transform mapping is conducted using both the acoustic and contextual information, which is more desirable than the conventional state mapping based on KLD.